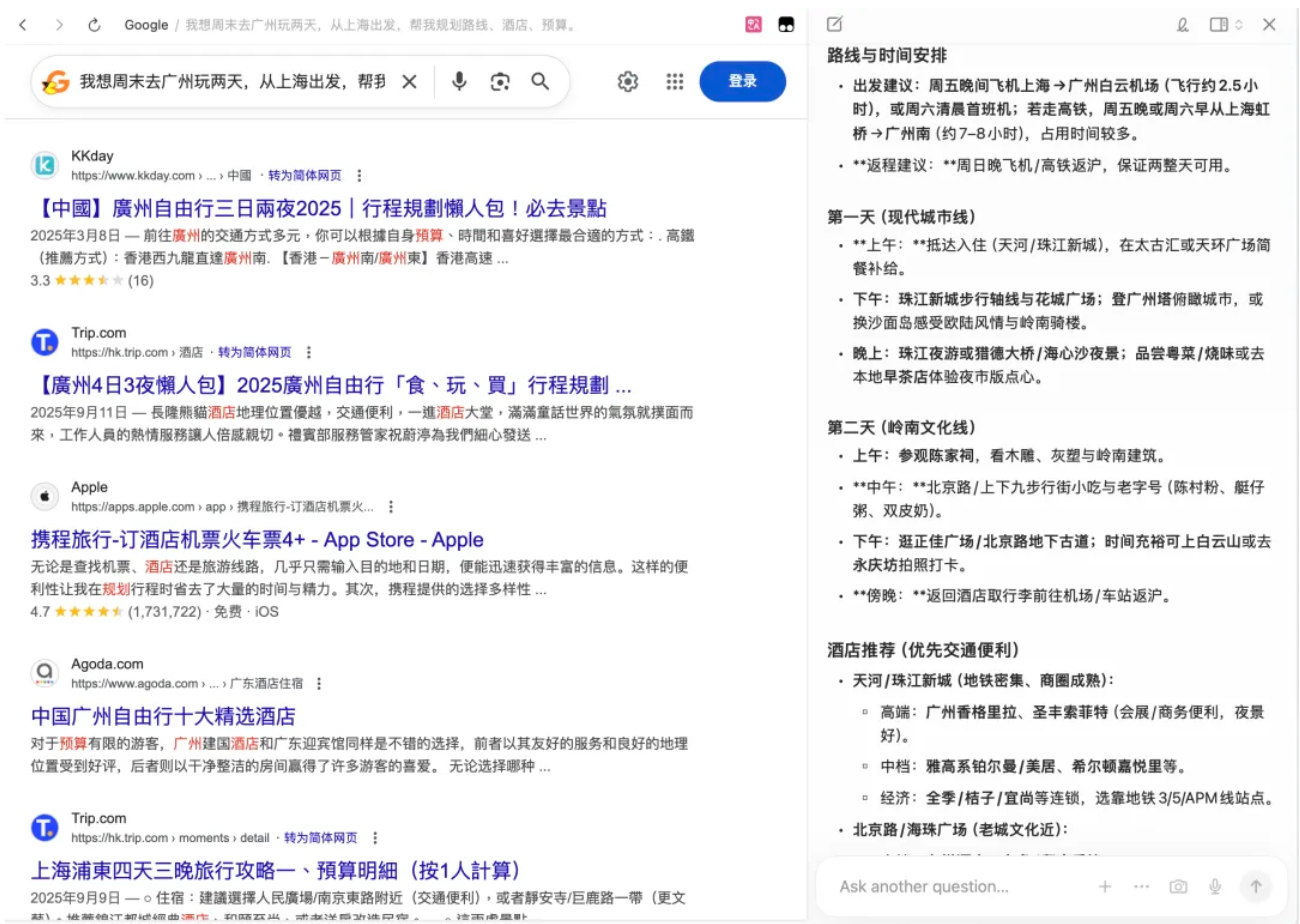
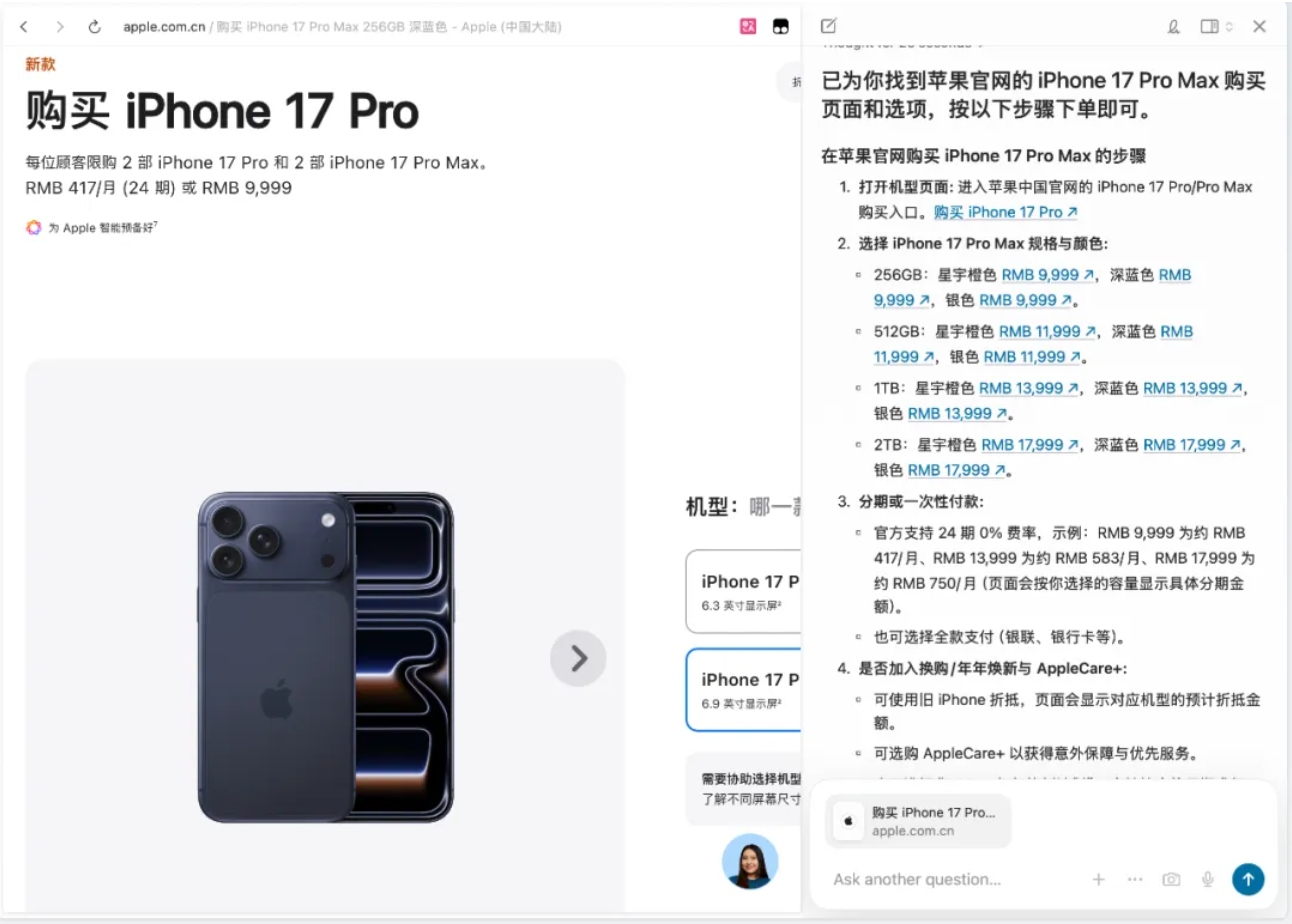
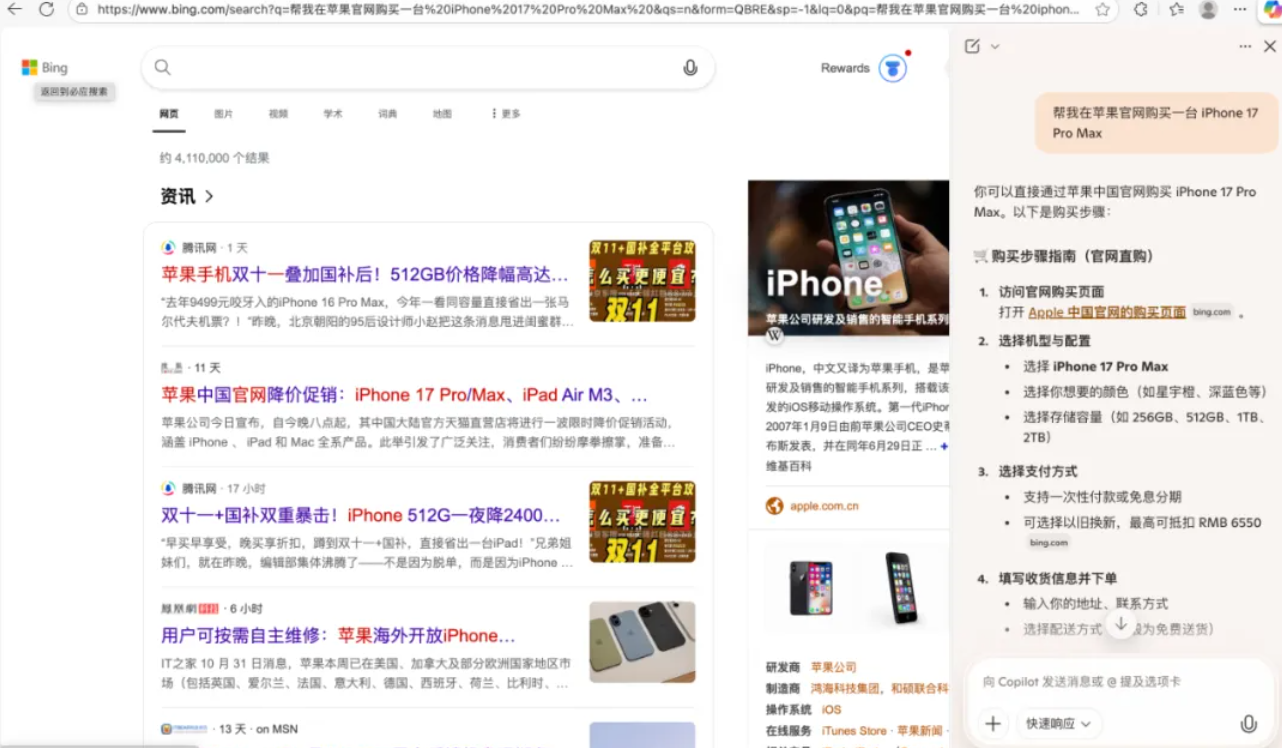
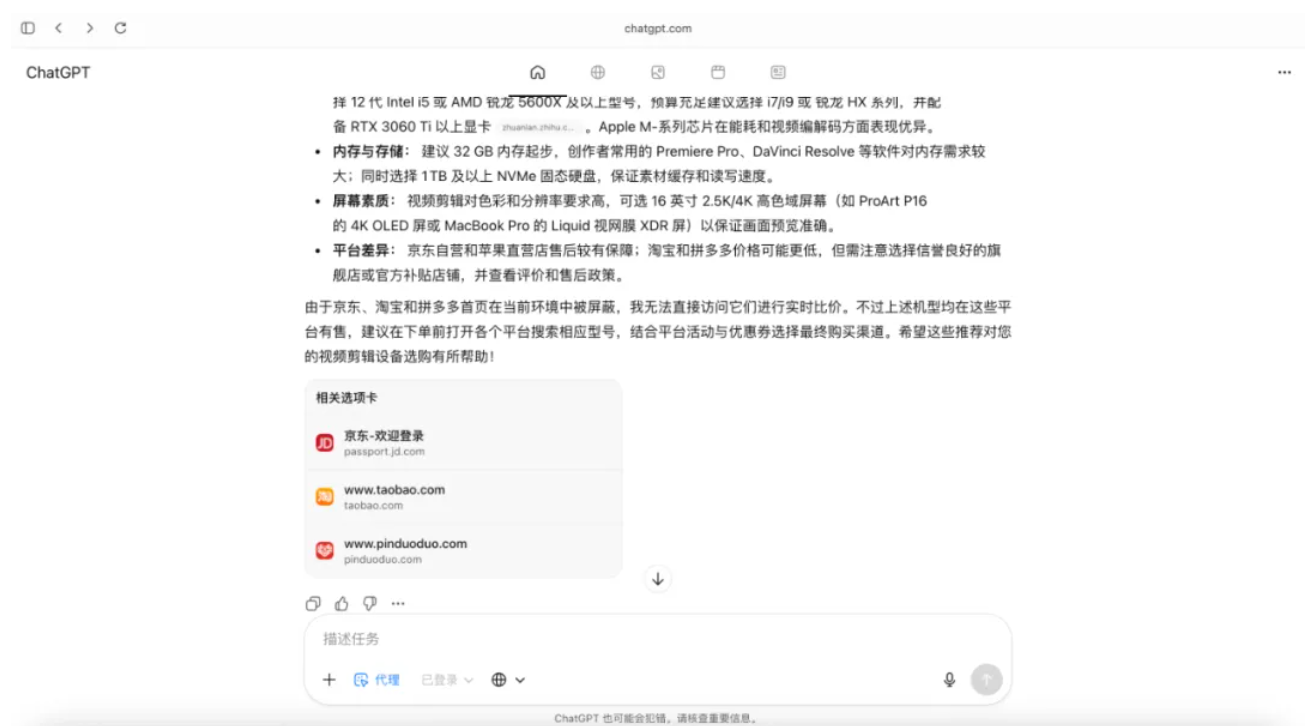
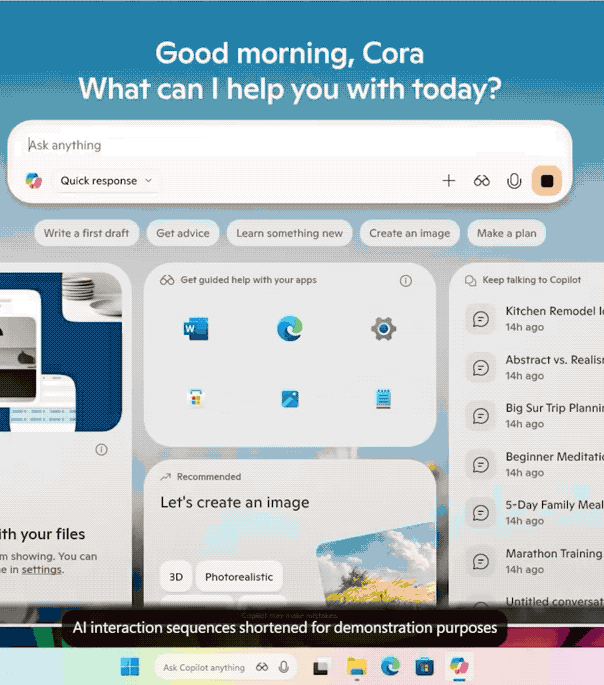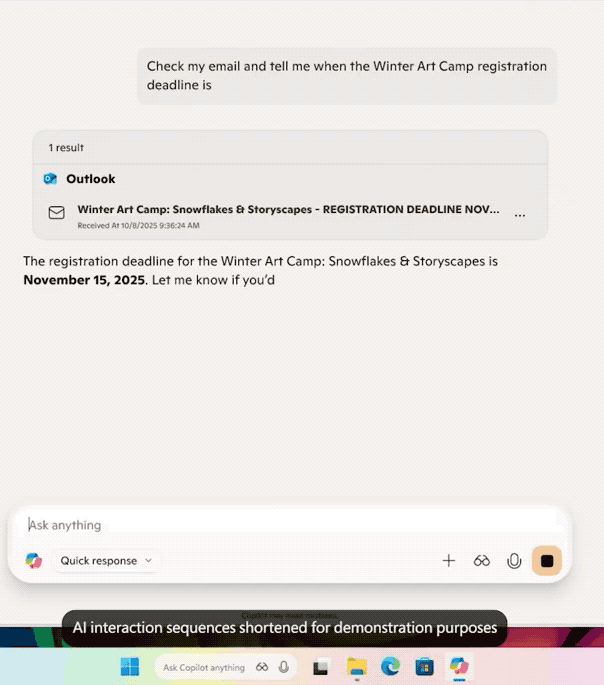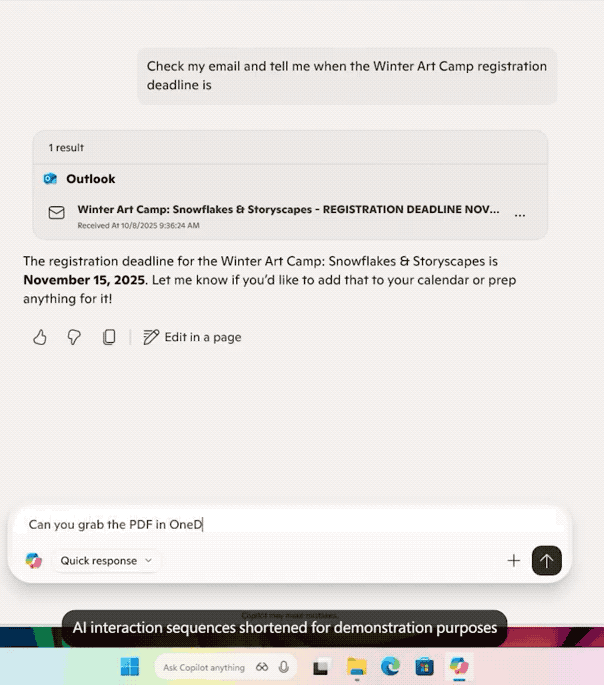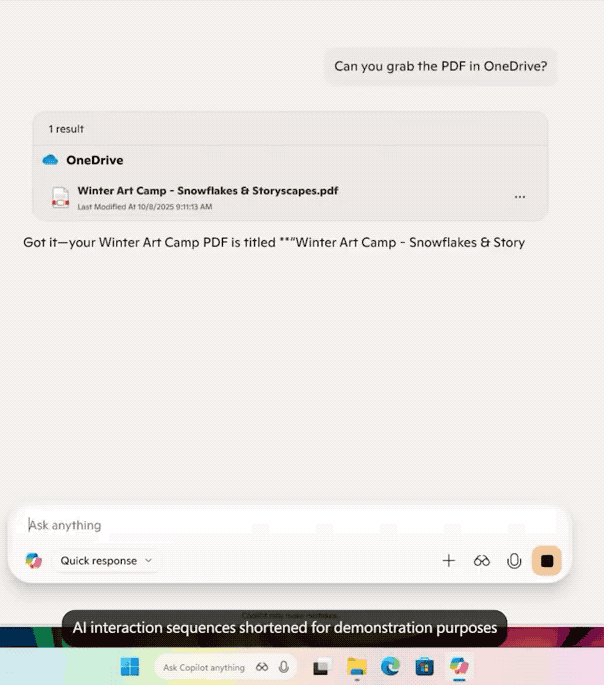
欢迎收看最新一期的 Hunt Good 周报!
在本期内容你会看到:
8 条新鲜资讯
3 个有用工具
1 个有趣案例
3 个鲜明观点
Hunt for News|先进头条
 杨振宁逝世,享年 103 岁
杨振宁逝世,享年 103 岁
据新华社报道,享誉世界的物理学家、诺贝尔物理学奖获得者,中国科学院院士,清华大学教授、清华大学高等研究院名誉院长杨振宁先生,因病于 2025 年 10 月 18 日在北京逝世,享年 103 岁。
公开资料显示,杨振宁 1922 年出生于安徽合肥,上世纪 40 年代赴美留学任教,他与同是华裔物理学家的李政道于 1956 年共同提出宇称不守恒理论,因而获得 1957 年诺贝尔物理学奖,成为最早华人诺奖得主之一。

「杨-米尔斯规范场论」,是研究凝聚原子核的力的精深理论。
杨振宁和米尔斯把电磁作用是由定域规范不变性所决定的观念推广到对易性的定域对称群,提出具有定域同位旋不变性的理论,发现必须引进 3 种矢量规范场,它们形成同位旋转动群的伴随表示。揭示出规范不变性可能是电磁作用和其它作用的共同本质,从而开辟了用此规范原理来统一各种相互作用的新途径。
杨振宁晚年曾多次谈及自己的人生体悟,他曾说:「我这一生最重要的贡献,是帮助改变了中国人自己觉得不如人的心理作用。我想,我在科学工作的成就,帮助中国人的自信心增加了。」
 苹果 CEO:Apple Intelligence 正努力入华
苹果 CEO:Apple Intelligence 正努力入华
10 月 18 日, 苹果公司首席执行官蒂姆·库克(Tim Cook)现身上海,在全球财富管理论坛·2025 上海苏河湾大会上,与清华大学经管学院院长、全球财富管理论坛执委会主席白重恩进行了对话。
据第一财经报道,在对话环节中, 库克就「科技驱动时代的创新边界」议题透露, 苹果正积极推动 Apple Intelligence 进入中国市场。他表示:「我们正在推动苹果智能进入中国,在操作系统层面整合人工智能的功能,让人们在每天使用的所有应用程序中,都能借助 AI 的力量。」

库克特别强调了 AI 技术的重要价值, 指出 AI 正在改变人们生活甚至挽救生命。本周在走访苹果上海浦东陆家嘴旗舰店时, 他特别与中国消费者交流了 Apple Watch 的跌倒检测等健康监测功能。
此外,报道中提到,促成 Apple Intelligence 在华发布是库克此行的核心目标之一, 同时他还肩负着与国内运营商协商在 iPhone Air 中推广 eSIM 技术的重要使命。
 OpenAI 推「ChatGPT 登录」功能,打造个人 AI 订阅生态
OpenAI 推「ChatGPT 登录」功能,打造个人 AI 订阅生态
据知情人士透露,OpenAI 正在推销一项更具野心的服务——允许访客使用 ChatGPT 凭证登录其网站,类似于目前广泛使用的 Google 或 Facebook 账号登录,采用该登录功能的公司可以将使用 OpenAI 模型的成本转移给客户。
具体而言,当用户使用 ChatGPT 账号登录某个基于 OpenAI 模型的初创公司服务时,该初创公司应向 OpenAI 支付的费用将从用户 ChatGPT 账户的容量限制中扣除。
免费用户每五小时可向 GPT-5 发送约 10 个查询,其中部分查询额度将用于抵消初创公司的 API 费用。如果免费用户在使用第三方服务时达到使用限额,系统会提示其升级到付费账户。

这种模式对使用频率较低、从未达到容量上限的用户具有吸引力,也能帮助缺乏资金支付高额 API 账单的小型初创公司降低成本。
不过,对于按使用量收费的初创公司而言,这可能损害其收入。
业内人士指出,这些举措凸显了 OpenAI 希望像苹果、谷歌和 Facebook 一样,将影响力扩展到消费者在线生活的各个方面。OpenAI 已告知投资者,预计到 2030 年将通过非付费用户间接产生约 1100 亿美元收入。
 https://www.theinformation.com/articles/openais-growing-ecosystem-play?rc=qmzset
https://www.theinformation.com/articles/openais-growing-ecosystem-play?rc=qmzset
 我国生成式人工智能用户规模超 5 亿
我国生成式人工智能用户规模超 5 亿
据新华社报道,10 月 18 日,中国互联网络信息中心在 2025(第六届)中国互联网基础资源大会上发布《生成式人工智能应用发展报告(2025)》。
报告显示,截至 2025 年 6 月,我国生成式人工智能用户规模达 5.15 亿人,较 2024 年 12 月增长 2.66 亿人,用户规模半年翻番;普及率为 36.5%。
报告认为,生成式人工智能正逐渐融入我国各类群体的日常生活中,中青年、高学历用户是核心群体。在所有生成式人工智能用户中,40 岁以下中青年用户占比达到 74.6%,大专、本科及以上高学历用户占比为 37.5%
报告指出,国产生成式人工智能大模型得到用户广泛青睐,并推动各种应用场景下的智能化改造升级。
调查发现,超九成用户首选国产大模型。生成式人工智能被广泛应用于智能搜索、内容创作、办公助手、智能硬件等多种场景,还在农业生产、工业制造、科学研究等领域得到积极探索实践。
https://www.news.cn/fortune/20251018/22bbffa5b01a47078a558a0ab46e66a4/c.html
 维基百科警告:AI 导致人类访问量大幅下降
维基百科警告:AI 导致人类访问量大幅下降
维基百科的托管机构维基媒体基金会近日发出警告,由于越来越多用户通过生成式 AI 聊天机器人和搜索引擎摘要获取信息,而非直接访问网站,导致这个全球最大在线百科全书的人类访问量出现危险性下降,威胁到其长期可持续发展。
基金会产品高级总监马歇尔·米勒在博客中表示,修正机器人检测系统后发现,维基百科过去几个月的人类页面浏览量与 2024 年同期相比下降了约 8%。他指出,这反映了生成式 AI 和社交媒体对人们获取信息方式的影响,尤其是搜索引擎开始直接提供答案,而这些答案往往基于维基百科内容。

米勒强调,访问量减少将带来严重后果。他说:「随着对维基百科的访问量减少,愿意参与并丰富内容的志愿者可能会越来越少,支持这项工作的个人捐赠者也可能减少。」
讽刺的是,虽然 AI 导致维基百科流量下降,但其数据对 AI 的价值却前所未有地高。几乎所有大型语言模型都在维基百科数据集上训练,谷歌等平台多年来也一直挖掘维基百科内容来支持其摘要功能,这些功能反过来又分流了维基百科本身的流量。
这一发现与其他研究相呼应。今年 7 月皮尤研究中心发现,仅有 1% 的谷歌搜索用户会点击 AI 摘要中的链接访问原始页面。基金会表示正在加强政策执行、制定归属框架并开发新技术能力,同时呼吁用户在搜索信息时主动寻找引用并点击原始资料,支持由真实的人创作的可信知识。
https://www.404media.co/wikipedia-says-ai-is-causing-a-dangerous-decline-in-human-visitors/
 Gemini 3.0 或将于 12 月发布
Gemini 3.0 或将于 12 月发布
据 Sources.news 报道,谷歌计划于 12 月推出旗舰 AI 模型 Gemini 的最新版本 3.0,该版本预计将实现显著性能提升,有望跻身行业排行榜前列。
作为谷歌 AI 战略的核心产品,Gemini 应用曾凭借热门的 Nano Banana 图像生成模型,一度登顶 iOS App Store 排行榜,短暂取代 ChatGPT 的榜首位置。
值得关注的是,报道中还提到,谷歌内部正讨论将部分 Gemini 高级功能纳入免费版本的方案。此外,谷歌还组建了一支小型秘密团队,致力于将 Gemini 3.0 集成到苹果的操作系统中,拓展应用场景。
https://sources.news/p/google-readies-gemini-3-perplexity
 OpenAI 宣布自研 AI 芯片
OpenAI 宣布自研 AI 芯片
本周,OpenAI 与芯片巨头博通宣布达成一项价值数十亿美元的重大合作协议,双方将在未来四年内共同开发和部署 10 吉瓦的定制 AI 芯片和计算系统,以满足 OpenAI 日益增长的庞大计算需求。
根据协议,OpenAI 将自主设计图形处理单元 (GPU),将其在开发强大 AI 模型过程中积累的经验整合到硬件系统中。这些芯片将由两家公司共同开发,博通负责从明年下半年开始部署。
新系统将采用博通的以太网技术和其他连接技术,部署在 OpenAI 自有及第三方运营的数据中心。据悉,双方 18 个月前就已开始定制芯片合作,此次进一步扩大至服务器机架和网络设备等相关组件。
这笔巨额交易使 OpenAI 与博通、英伟达和 AMD 三大芯片巨头约定购买的计算能力总规模达到 26 吉瓦。OpenAI CEO 山姆·奥特曼和负责基础设施建设的总裁格雷格·布罗克曼表示,公司目前可用的计算能力远远不足。随着 AI 产品需求快速增长,他们希望在全球建设大型数据中心以保持领先。
据知情人士透露,奥特曼最近告诉员工,OpenAI 计划到 2033 年建设 250 吉瓦的新计算能力,按当前标准这将耗资超过 10 万亿美元。
https://openai.com/index/openai-and-broadcom-announce-strategic-collaboration/
苹果新 AI 搜索主管转投 Meta
据彭博社记者 Mark Gurman 报道,苹果公司负责 AI 搜索项目的高管 Ke Yang 即将离职,加入 Meta。
这一变动发生在他刚刚接手「Answers,Knowledge and Information」(直译为「答案、知识和信息」,简称 AKI)团队数周之后。
该团队的任务是为 Siri 增强类 ChatGPT 功能,使其能够从网络实时获取信息。
知情人士透露,Ke Yang 的离开是苹果人工智能部门近期一系列高层出走中的最新一例。
今年以来,已有约十余名核心成员离开苹果基础模型团队,其中部分人同样转投 Meta,加入其新成立的「Superintelligence Labs」。
苹果原计划在 2025 年 3 月推出全新版本的 Siri,整合 AKI 团队研发的搜索功能,并补齐此前推迟的多项特性,包括调用个人数据以处理更复杂的请求。
该项目被视为苹果追赶 OpenAI、Perplexity 以及 Google Gemini 等竞争对手的重要举措。
随着 Ke Yang 的离职,AKI 团队将转由苹果副总裁 Benoit Dupin 接管,他目前负责机器学习相关的云基础设施。
https://www.bloomberg.com/news/articles/2025-10-15/apple-s-newly-tapped-head-of-chatgpt-like-ai-search-effort-to-leave-for-meta
Hunt for Tools|先进工具
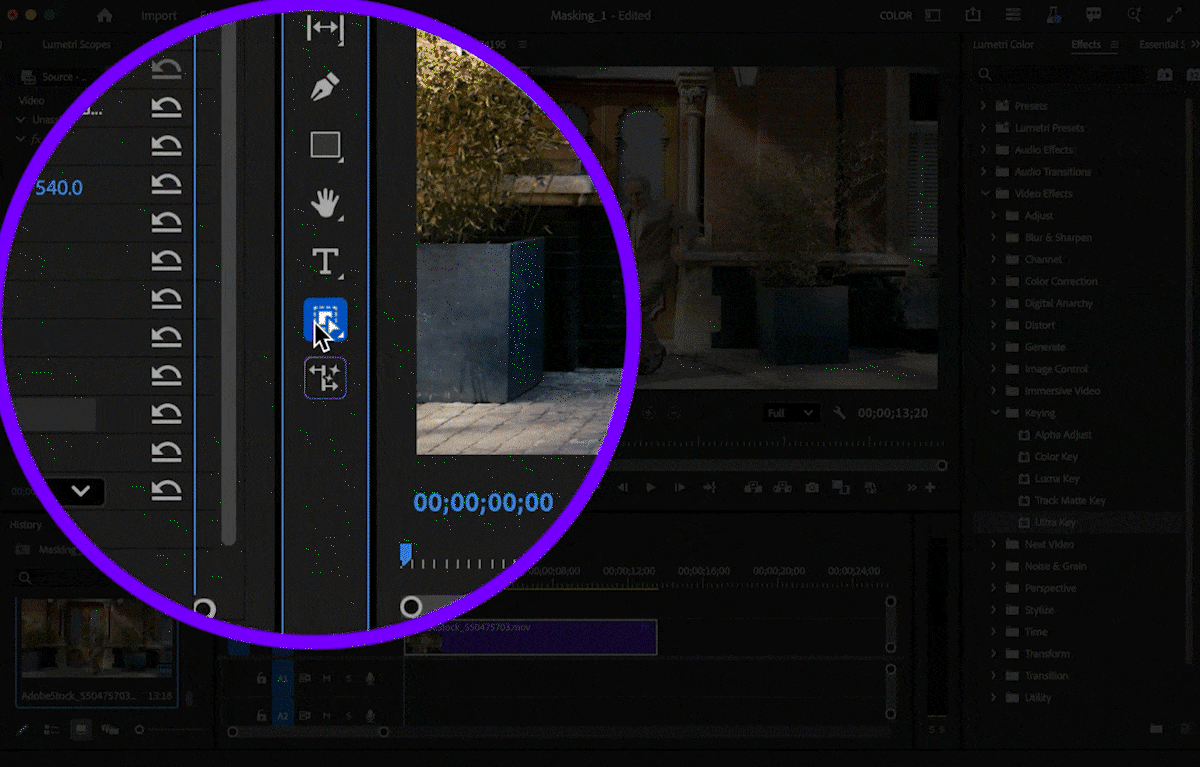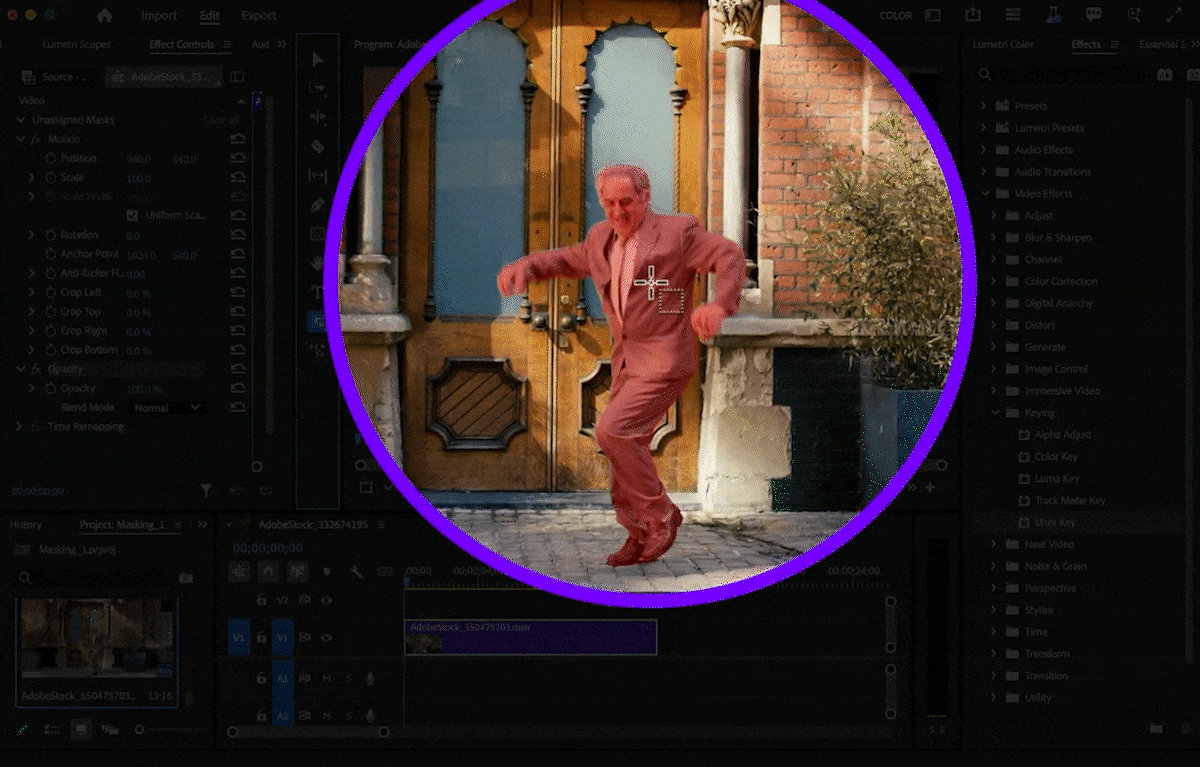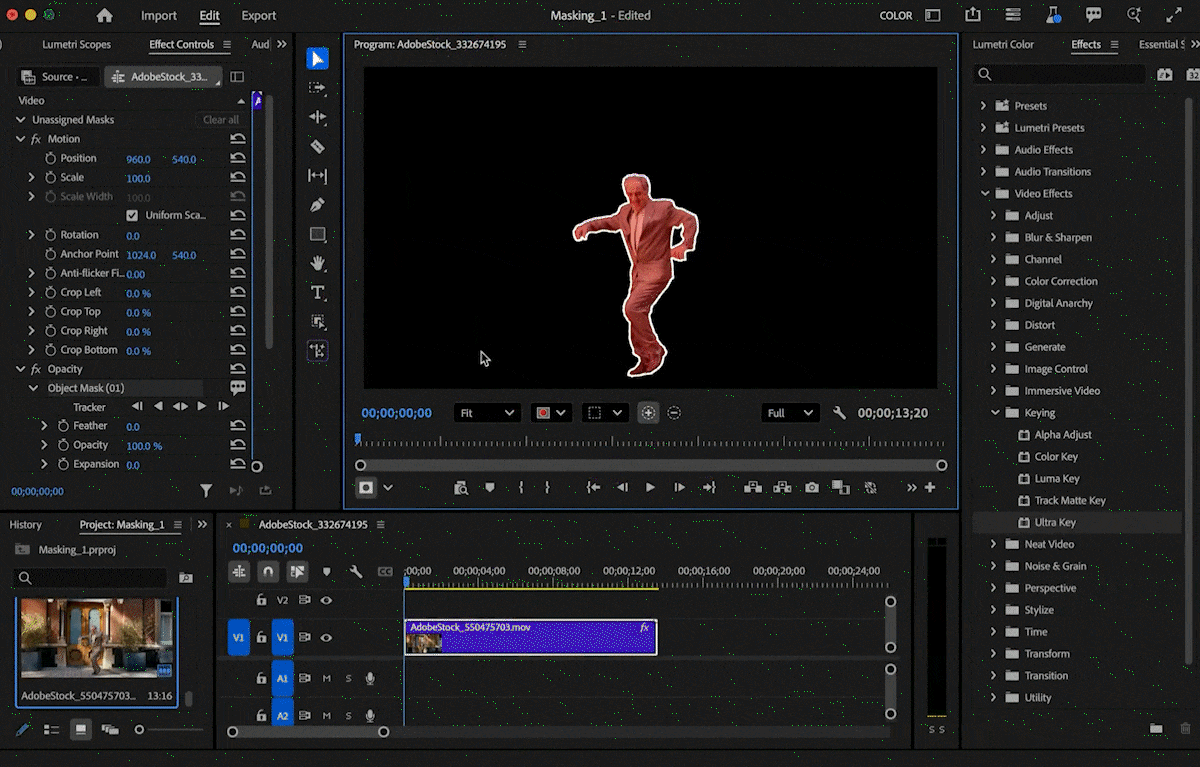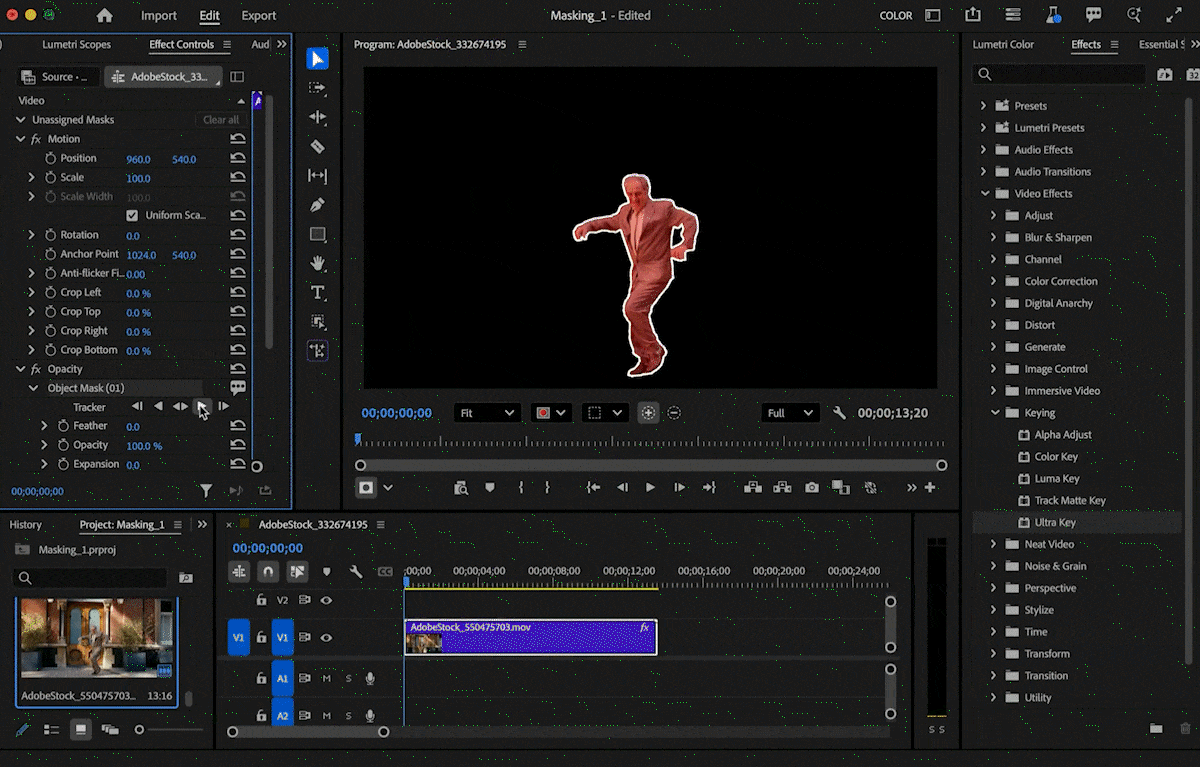
🛜 Manus 1.5 正式发布,一键开发完整 Web 应用
10 月 17 日,AI 智能体平台 Manus 宣布推出全新版本 Manus 1.5。
官方表示,本次更新在速度与性能方面实现了全面提升,并进一步验证了其核心架构的通用性。

与传统的「AI 网站生成器」不同,Manus 团队强调,他们并非单纯开发一款工具,而是持续进化底层框架,并为其配备合适的功能模块。得益于这一思路,Manus 在短短一个月内便实现了「sota 级别」的 AI Web 应用构建能力。
值得注意的是,Manus 1.5 的新能力与平台现有功能深度打通。例如,用户可快速搭建服务介绍网站,并在收集到客户信息后,通过 Manus 客户端和邮件推送触发后续任务,如自动生成个性化幻灯片。
官方表示,这一增强功能已面向所有用户开放,其背后的基础设施是团队更宏大愿景的一部分 —— 打造一个任何人都能通过对话调用云计算与 AI 全部力量的平台。
https://manus.im/zh-cn/blog/manus-1.5-release
 英伟达开售全球最小 AI 超级计算机,黄仁勋给马斯克「送货上门」
英伟达开售全球最小 AI 超级计算机,黄仁勋给马斯克「送货上门」
本周,NVIDIA 在官网发文,宣布正式开售 DGX Spark,这是一款号称「全球最小 AI 超级计算机」的桌面级产品。首台设备由 NVIDIA CEO 黄仁勋亲手交付给 Elon Musk,地点选在 SpaceX 的 Starbase 基地。
据悉,DGX Spark 基于 Grace Blackwell 架构,单机可提供 1 Petaflop AI 性能,配备 128GB 统一内存,能够在本地运行高达 2000 亿参数的推理模型,并支持对 700 亿参数模型进行微调。

官方强调,该产品面向开发者、研究人员与创作者,旨在将超级计算机级别的算力带到桌面。
黄仁勋表示:「2016 年我们推出 DGX-1,并交付给当时的 OpenAI,那台机器催生了 ChatGPT,开启了 AI 革命。如今 DGX Spark 将再次把超级计算机放到开发者桌面,点燃新一轮突破。」
马斯克也在 X 上回应称:「这台 DGX Spark 的能效比黄仁勋 2016 年交付给我的 DGX-1DGX-1 高出约 100 倍,那是史上第一台专用 AI 计算机」。
DGX Spark 将于 10 月 15 日起在 NVIDIA 官网及合作渠道开启订购。
相关阅读:时隔 9 年,黄仁勋再次给马斯克送货上门,跳票大半年的 AI 个人超算终于来了
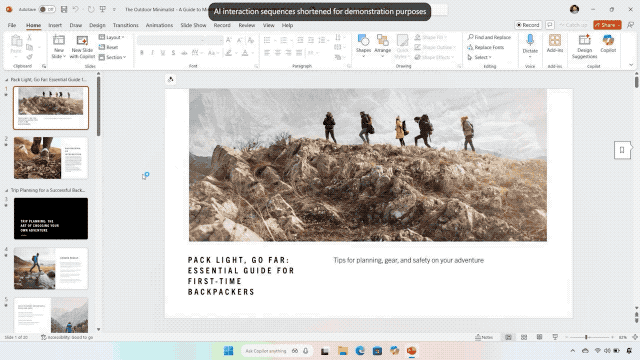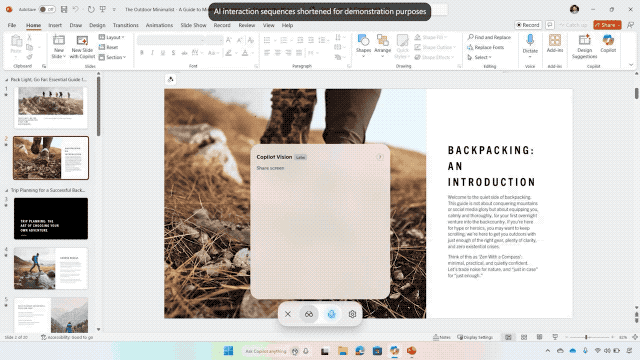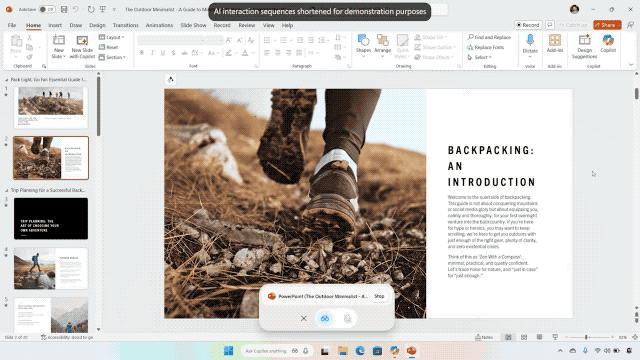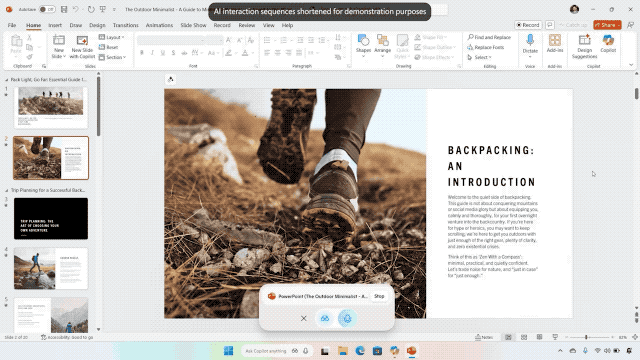
 Windows 11 迎来重磅更新:Copilot 全面接管语音、屏幕与任务栏
Windows 11 迎来重磅更新:Copilot 全面接管语音、屏幕与任务栏
近日,微软在官网发文,宣布为 Windows 11 推出大规模更新,核心在于全面引入 AI 功能,让每台设备都成为「AIPC」。
本次更新的重点包括:
- Hey,Copilot:用户可通过语音直接唤醒 Copilot,实现免手操作;
- Copilot Vision:支持读取屏幕内容并实时指导操作,甚至能在界面上标注点击步骤;
- Ask Copilot:将 Copilot 集成至任务栏,一键直达;
- Copilot Actions:可在本地执行任务,如整理照片、提取 PDF 信息;
- Copilot Connectors:打通 OneDrive、Outlook 与 Google 全家桶,实现跨平台数据检索。
此外,微软还将 Manus AI Agent 引入 Windows,用户可在文件资源管理器中直接调用「使用 Manus 创建网站」功能,几分钟内生成网页。
其他更新还包括与 Filmora 的视频编辑集成、Zoom 快捷会议安排,以及 Gaming Copilot 测试版。微软强调,语音交互不会取代键盘和鼠标,而是成为第三种输入方式。
尽管这些新功能主要面向支持 Copilot 的国家/地区,但微软的这次更新也为 AI PC 原生操作系统指明了一个可能的发展方向。
相关阅读:Windows 11 大更新:动嘴就能让 AI 操控电脑,还有 Manus 强势上岗
Hunt for Fun|先玩
🥱 GPT-5 攻克「百年数学难题」遭反转,OpenAI 科学家删帖致歉
近日, 一则关于 GPT-5「一个周末解决 10 个百年数学难题」的消息在学术界引发轩然大波, 但随后被证实存在严重误导。
事件起源于 OpenAI 研究科学家、前微软副总裁塞巴斯蒂安·布贝克上周首次披露, 两名数学研究人员利用 GPT-5 在一个周末内找到了 10 个未解决埃尔德什难题的答案。

埃尔德什难题是著名数学家保罗·埃尔德什生前提出的约 1000 多个数学问题, 此前人类只解决了部分。OpenAI 研究人员之一马克·塞尔克也随后确认, 他们通过数千次查询 GPT-5, 在 10 个问题上找到了解决方案, 并在另外 11 个问题上取得显著进展。
然而, 事实真相很快浮出水面。
埃尔德什问题网站维护者托马斯·布卢姆澄清称, 这是「严重的歪曲」,GPT-5 只是找到了他个人此前不知道的已发表文献, 这些问题实际上早已被其他数学家解决。网站上标注的「未解决」状态仅表示维护者本人尚未找到相关论文, 而非学术界真正的未解难题。
布贝克随后删除了原帖并道歉, 承认只是在文献中找到了已有的解决方案, 并非 AI 独立完成数学证明。Meta 首席 AI 科学家杨立昆也在评论区贴脸输出,讽刺他们被自己过度炒作 GPT的言论坑惨了。
https://x.com/SebastienBubeck/status/1979539604522127746
Hunt for Insight|先知
🟰 陶哲轩:AI 对数学研究的核心价值在提效而非攻坚
菲尔兹奖得主、被誉为「数学界莫扎特」的华裔数学家陶哲轩近日发表文章,阐述了他对人工智能在数学研究中应用前景的看法。
陶哲轩指出,AI 在数学领域近期最有成效的应用,并非用最强模型攻克最难问题,而是利用中等能力工具加速那些普通但耗时的关键研究任务。
他认为,在这些任务中人类专家可以凭借经验来引导和验证 AI 产出,这种 AI 结果本身也可由人工完成的特点恰恰是优势,因为专家能更可靠地评估输出结果。
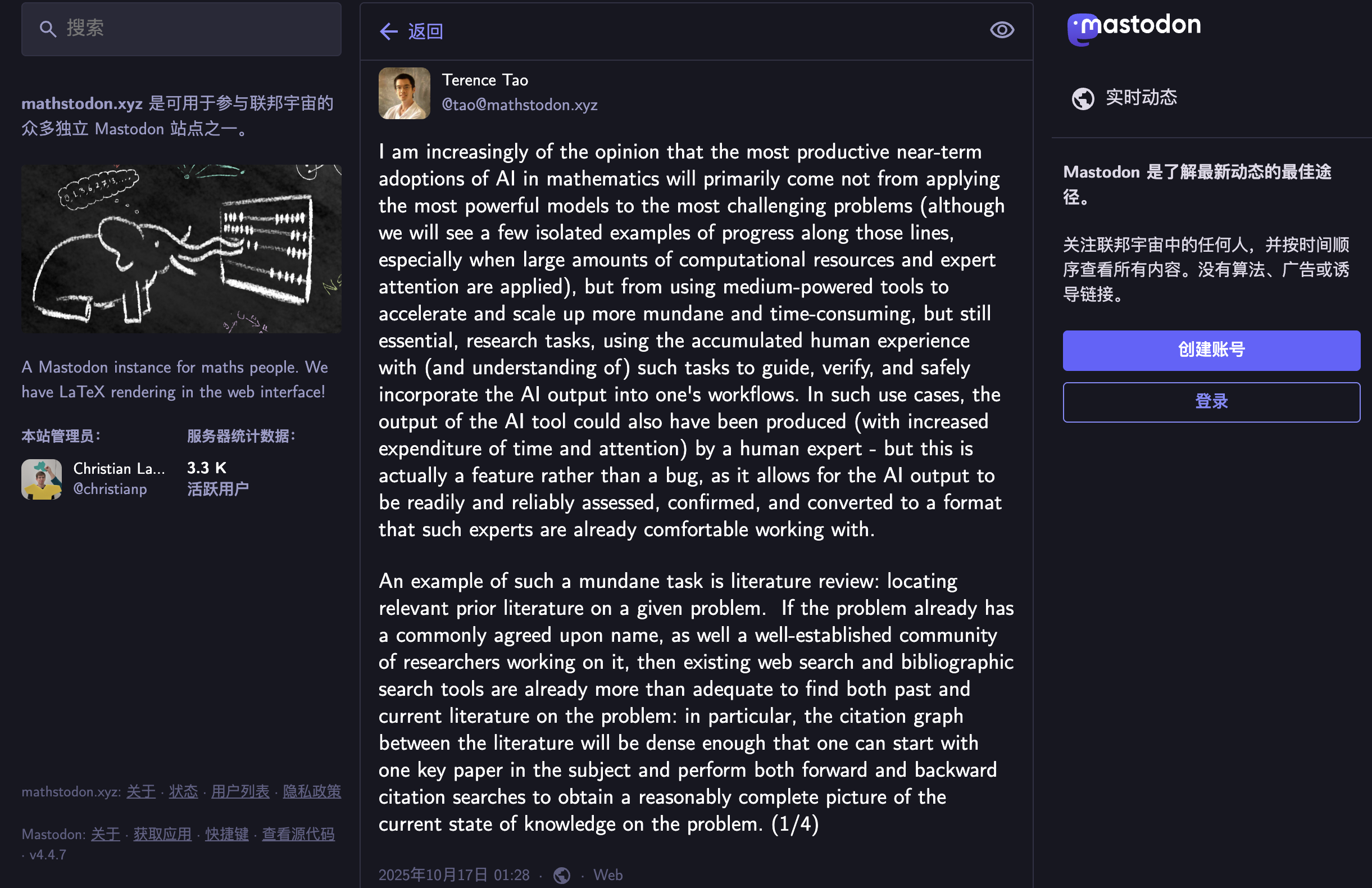
他以文献综述为例说明。对于有明确名称和成熟研究群体的问题,现有检索工具已足够强大,但当相关文献零散、缺乏统一命名,或因期刊冷门、研究群体间缺乏交流等原因导致引用关系难以追踪时,传统检索就变得极为耗时。
而 AI 工具的另一潜在优势是能促使「负面结果」得到报告。传统上研究者若未找到相关文献通常不会明确报告,担心日后发现遗漏会显得尴尬,这可能导致重复劳动或误判问题状态。但使用 AI 系统性检索时,同时报告正面和负面结果就显得更自然,有助于更准确呈现问题在现有文献中的真实状态。
https://mathstodon.xyz/@tao/115385022005130505
 Figma CEO 称 AI 不会取代工作,各部门持续招聘
Figma CEO 称 AI 不会取代工作,各部门持续招聘
当时时间 10 月 17 日,设计工具公司 Figma CEO 迪伦・菲尔德在播客中明确表示,AI 不会威胁到人类工作,反而能为行业创造新机遇。
菲尔德提到,Figma 9 月开展的一项涵盖 1199 名设计师、产品经理、开发者等从业者的调查显示,近 60% 的产品构建者因 AI 能投入更多高价值工作,约 70% 的受访者认为自身效率显著提升。
他强调,AI 的核心作用是辅助人类而非替代,应聚焦如何适应技术发展、摆脱重复劳动,而非过度担忧。
总部位于旧金山的 Figma 成立于 2012 年,今年 7 月成功上市,目前市值近 300 亿美元,员工规模超 1600 人。
菲尔德透露,公司正持续在各部门扩充岗位,虽在探索 AI 提升效率、降低成本的可能,但更看重其解锁增长新机遇的潜力。这并非他首次表态,此前他也曾多次强调,AI 是增强人类工作的工具,设计师仍需发挥主导作用,技术将让更多人获得创作机会。
https://www.businessinsider.com/figma-ceo-dylan-field-ai-jobs-hiring-2025-10
 前 OpenAI 科学家卡帕西:AGI 仍需十年,强化学习存在根本缺陷
前 OpenAI 科学家卡帕西:AGI 仍需十年,强化学习存在根本缺陷
特斯拉前自动驾驶负责人、OpenAI 联合创始人安德烈·卡帕西近日在播客访谈中系统阐述了他对人工智能发展的最新看法, 认为实现通用人工智能(AGI)至少还需要十年时间, 并对当前 AI 技术路径提出了尖锐批评。
在谈到强化学习时, 他表示强化学习「非常糟糕」, 因为它假设解决问题过程中的每个步骤都是正确的, 实际上却充满噪音。他指出, 人类绝不会像 AI 那样进行数百次尝试, 然后仅根据最终结果来加权整个过程。当前大语言模型评判者也容易被对抗性样本欺骗, 导致训练过程出现严重偏差。
关于超级智能, 他认为 AI 发展是计算演进的自然延伸, 不会出现人们想象的「智能爆炸」, 而是会延续过去几百年来 2% 左右的经济增长率。他将 AI 比作历史上的编译器、搜索引擎等工具, 认为它们都是递归式自我改进过程的一部分。
在教育领域, 卡帕西正在创建 Eureka Labs, 致力于打造「星际舰队学院」式的精英技术教育机构。他相信 AI 将彻底改变教育, 但强调当前 AI 能力尚不足以提供真正的一对一辅导体验。他设想未来每个人都能掌握多门语言和各学科知识, 人类将像健身一样追求智力提升。
https://www.dwarkesh.com/p/andrej-karpathy
彩蛋时间

作者:@CharaspowerAI
提示词:A pencil drawing of [character or object] [breaking through / emerging from / interacting with] [a paper surface or cracked wall], in the style of a tattoo sketch on white paper. Black pen and pencil only, with [one specific element] in [a vivid color] as the only colored detail. Trompe-l’œil effect with [torn edges / curled paper / cracked wall], realistic shadowing, sketchbook illustration style, high detail.
链接:https://x.com/CharaspowerAI/status/1978861011273654384
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博