Bruce Springsteen’s Father Complicates a Powerful American Narrative
He had a good factory job that helped him raise a family. But it didn’t save him from despair.
![]()
![]()
第一次看到时,我真的笑出声。但笑着笑着,就觉得有点不对劲了。
这个研究,可能说的就是我们自己。
https://llm-brain-rot.github.io/
首先,这研究不是段子,是来自德州 A&M、德州大学奥斯汀分校和普渡大学的硬核论文。简单来说,他们做了个实验:

把一个正常的 AI 大模型(对照组),和另一个被强迫刷了几个月推特、Reddit 等社交媒体的 AI 模型(实验组)进行对比,他们用了两种标准“垃圾信息”:
结果发现了不得了的事:
喂了垃圾数据后,AI 在推理、长文理解、安全等方面全面降智。
而且,这是一种 “剂量反应”:垃圾数据的比例越高,AI 就“脑损”得越厉害。
看个例子就明白了:
在一项叫“ARC-Challenge”的推理测试中(考验 AI 举一反三的能力),随着提供垃圾数据(M1 型信息标准)的比例从 0%增加到 100%,AI 的准确率从 74.9% 直降到 57.2%。
下面这张表更直观,我从原论文里摘了几个关键数据(红色代表性能变差):
简单的说:AI 不仅降智了,还变得更不安全、性格更“黑暗”了。
研究人员对 AI 犯的错误进行了分析,发现最关键的是它学会了偷懒,也就是 不思考了。
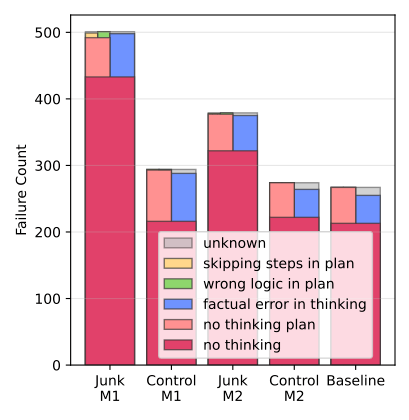
上图显示,在“脑腐”之后,对比基准,AI 思维的错误显著增多。它不再愿意进行一步一步的严谨推理,而是倾向于直接跳到结论,M1 的影响更是大于 M2。
这不就是我们在信息流里被训练出的习惯吗?
最让人难接受的是,这种“脑腐”基本不能治愈。
研究人员试着用大量高质量的“干净”数据去“修复”那个降智的 AI,结果发现效果相当有限。

即使经过大规模的“高质量训练”,性能也只能部分回升,始终无法恢复到基本水平。
这意味着,AI 的内部认知结构,或者说它的“世界观”,已经被永久性地改变了。
看到这里,你是不是也品出点别的味道了?
虽然研究的是 AI,但你很难不怀疑这个研究是在指桑骂槐。
如果 AI 会因为刷垃圾信息而变傻,那当前互联网信息环境里的我们呢?
仔细想想,我们身边是不是已经有太多迹象了:
“大学教授也可能转发每日口服 7 颗绿豆能够逆转高血压……的文章,学术训练的强度和社交网络垃圾文章洗脑的强度不可同日而语。”
我们以为自己是在驾驭信息,但很可能,我们只是在被网络信息洪流日夜冲刷,以为自己有足够的知识和阅历来抵御侵蚀,但长年累月的垃圾信息轰炸,可能正在不知不觉中重塑我们的大脑。
大脑的认知逻辑正在被悄悄地改变。
去查查那些著名社交平台的创始人,看看他们自己每天花多少时间在手机上?
你会发现一个很有意思的现象:很多产品的设计者,自己反而刻意与产品保持距离。这背后的原因,值得我们每个人深思。
一个小测试:
读到这里,你还记得这篇文章是怎么开头的吗?
…
想不起来也没关系。
这可能就是一个信号,提醒我们是时候让大脑从无休止的信息流中抽离出来,安静一会儿了。
为了保护你的脑子,现在,是不是该对我说声“谢谢”?🙂
![]()
![]()
长时间没消息的黑森林工作室憋了个大的,发布了生成式流匹配模型 FLUX Kontext。
这套模型最强的地方就是可以对图片进行编辑,但是不会影响没有编辑的地方。
而且还支持多张图片参考生成新的图像,依然能保持需要参考内容的高度一致性。
直接替代了很多原来需要 PS (美图秀秀、Photoshop 等)才能做的需求,原来需要吭哧瘪肚 P 很久的图,现在说句话就行。
我这几天也探索了很多这个模型的用法,这次不会以测试的形式展示了,全是具体用法,让你告别 P 图这个复杂难搞的操作,另外后面也会介绍所有可以使用这个模型的渠道。
🎨 先介绍一下我探索出来的各种用法:
首先是非常简单的图片修改需求,FLUX Kontext 支持通过简单的提示词对图片进行非常精细的修改,而且不会影响未修改的区域。
我们想要给自己的日常照片加一些配饰或者改一下照片的姿势都没有问题,可以看到人物的面部一致性都没有问题,而且修改的地方跟环境也融合的很好。
⚠️注意:FLUX Kontext 只支持英文提示词,我这里放中文是方便理解,你可以用 AI 或者翻译软件把提示翻译了使用
当然 FLUX Kontext 也可以对照片进行大幅度的更改,比如你想要给照片换个背景或者给你自己换一身应景的衣服,再或者在前面的基础上换个姿势。
可以看到我把场景变成了酒吧,整个光线氛围也同步发生了变化,之后又尝试了不同的拍摄角度和姿势,也没有问题。
这种修改需要注意的是优势 Kontext 的分辨率是固定的,画全身照的时候面部有可能会变糊,因为像素区域太小的原因。
🎉 从左到右的提示词分别是:
站在酒吧吧台前
低角度侧脸,白衬衫加领带,吧台灯带背光
左侧半身特写,黑色皮夹克,霓虹灯映衬
全身广角,红色鸡尾酒裙,手扶吧椅
背后平视,帽饰西装,吧台酒架虚化
之前很火给老照片上色和修复也不是问题。
比如我下面的测试提示词就只有给照片上色,Kontext 处理的很好,而且整个色彩非常的高级和自然,明暗关系处理的很好。
想要做风格化?也没问题,只需要一句“将图片变成真实照片”的提示词就行,所有的细节都还原的很好。
当然可能更多人的需求是把自己的照片变成风格化的图片。
比如我们可以输入“把照片转换为吉卜力风格”,Kontext 也处理的很好而且人物的主要特征和电车的特征都还原了,不存在 4o 那种过度重绘和修改细节的问题。
而且这玩意还能修改图片上的文字,最屌的是不会影响原来的其他内容,而且修改的文字字体依然可以保持原来的风格。
你只需要输入“将图片中的 XXX 文字修改为 XXX”就行,比如我这里就把主要的标题改为了 Guizang,字体风格都是一致的,而且他还知道不需要换行。
针对海报复杂一些的修改也是可以的,你可以把一张找到的现成海报改掉文字和内容变成你自己的。
比如这里我就把 Oppo 的倒计时海报改成了小米的,而且连背景色都换了,Kontext 很好的处理了玻璃散射光的那部分。
这里唯一可惜的就是 FLUX Kontext 不支持生成中文,所以你只能修改图片中的英文,但是如果你不修改里面的中文,文字是不受影响的,这比其他图像模型好多了。
Change “Oppo” to “Xiaomi”, and set the image background color to orange.
这个是 Padphone 老师发现的,FLUX Kontext 还是目前最强的去水印模型,可以去掉各种复杂恶心的水印。
比如这里我找了一个 Unsplash 带水印的图片,这种半透明的水印会和图片叠加混合非常难彻底去掉,你只需要跟 Kontext 说“去掉图片的水印”,接下来奇迹就会发生,一点水印都没了。
大家最近应该都被一些 AI 图像模型生成图片默认加水印搞得不堪其扰把,即使开了会员依然有水印,这时候就可以让 Kontext 帮你解决了。
我们也可以用 Kontext 给各种平面的文字或者图案添加上材质和背景,替代原来需要 3D 渲染才能完成的需求,非常适合做品牌设计和平面设计的朋友。
比如这里我就给这个 Logo 变成了金属材质,还给图片加上了草地的背景,可以看到 Kontext 把 Logo 的一些笔画细节还原的非常好。
🎹
Transform the logo text into a shimmering metallic material, floating above a grassy field filled with flowers.
Kontext 还可以在你浏览景区的时候帮你把各种无关的其他游客搞掉,再也不用担心自己好不容易拍了账号照片,结果被误入的其他人毁掉了。
可以看到 Kontext 可以很清楚的识别画面的主体不会连你想拍的人也一起去掉,当然你如果就是想拍风景也可以,让他去掉画面上所有的人就行。
去掉照片中跟主体无关的其他行人
去掉照片中所有的人
前几天收到了可灵的一周年礼盒,看到 Padphone 老师做的展示图手痒,就想看看能不能用 Kontext 做出来,没想到真可以还做的很好。
非常离谱是他连我箱子放地上的灰尘都还原了,下次你要是想要生成类似图片的话记得擦一下产品再拍,哈哈。
💡
一个黑色箱子放在一张舒适、有褶皱的白色毯子中央,毯子的织物纹理清晰可见。瓶子周围自然地摆放着一些精致的白色小苍兰,几片花瓣零星散落。阳光柔和地洒下,投下柔和、弥散的阴影,营造出一种温暖而宁静的氛围。非常逼真的特写场景,光线是柔和的自然日光。
很多人说箱子是立方体太好生成了,整点复杂的,那我们拿可灵礼盒里的工服试试。
显然也没啥问题,文字有问题是因为生成图片的分辨率低,文字又小,导致的模糊,就跟我们拍照的时候离得远的文字也会模糊一样。
一件黑色 T 恤水平漂浮于空中,正从天花板向地板降落,看起来毫无重量。画面中无人,充满超现实感且不受重力影响。光线柔和,风格简约而优雅。背景为灰色。
很多朋友说我想要更复杂的商品展示,指定多张图片的模特和商品然后合成到一个图片中行不行,也是可以的,多图参考有点复杂我后面会讲。
可以看到第一张图商品细节、模特服装、配饰、发型以及背景都没问题,这个惊到我了。
第二张图我让模特穿上了可灵的工服,这次连衣服上的小字都还原了,可以说是完美还原,这个你让我在电商平台刷到,加上电商平台的压缩,我看不出来说实话。
这里有个小技巧:FLUX Kontext 手持产品的时候,产品一般会比正常的比例偏大,这个时候提示词描述一下产品大小就可以解决问题,比如手持易拉罐变为手持小号易拉罐。
女孩拿着化妆品瓶子
女孩穿着这件 T 恤
最后压轴的是我们日常修图最常见的需求,大家都想把自己变得好看点,面部的美颜现在都发展的比较好了。
但是身体部位很多还是靠用美图或者用醒图一点点的 P,自带的一键优化非常的生硬死板,不够自然。
昨天试了一下给男生增肌,发现 FLUX Kontext 可以很好的理解需求,图片任何部分都没变化,只有胳膊的肌肉变大了,这要是不说谁知道我 P 了,哈哈。
🍞
男性胳膊的肌肉变大,面部没有变化。
那变瘦点是不是也可以呢,可以的,甚至都能瘦脸,瘦的很自然,不会再让人从扭曲的门把手或者瓷砖看到自己 P 图了,突然想到这下卖减肥药和健身课的是不是又爽了,一键搞定广告素材。
📍
让女性的胳膊变瘦,肚子变得平坦,去掉面部赘肉
如果你就是单纯的想要尝试一下这个模型 不想涉及到复杂操作的话我推荐两个渠道:
FLUX 官方的 Palyground (https://playground.bfl.ai/image/edit)和 Krea (https://www.krea.ai/edit)其中 FLUX 的 Palyground 还送了 200 积分,生成一张图只消耗 4 积分,够你玩很久了。
这两个地方的使用都很简单上传图片,输入提示词然后等待就行。
其中 Krea 选择 FLUX Kontext 的 Pro 模型就行 Max 模型在单图修改场景反而效果不好。
FLUX 的 Palyground 的话生成的时候记得把在输入框右边三个点那里把每次生成的张数改成 1,不然一次生成 4 张有点浪费。
如果你想要开发产品或者有 Comfyui 的基础想要玩一下多图参考,这里我推荐 Fal 的渠道(https://fal.ai/models/fal-ai/flux-pro/kontext/max/multi)。
Fal 的测试页面可以直接使用多图参考,上传图片输入提示词就行,如果你不想用多图了,可以在页面上方红框那里选择其他 Pro 模型尝试单图编辑。
另外 Fal 也有他们的 Comfyui 插件,只需要在 Comfyui manager 里面搜索 ComfyUI-fal-API 然后安装就行。
安装之后在插件目录,找到 config.ini 文件,把里面 这段话改成你的 API Key 就行。
工作流的搭建很简单找到 FLUX Pro Kontext Multi 这个节点链接多张图,之后输入提示词就行,另外由于这个是 API 节点不需要本地算力,所以 mac 电脑也可以玩。
在涉及到针对人体的精细修改比如变瘦、变老变年轻需要多抽卡,不一定一次能成功。
多图参考的时候人脸的 ID 保持会下降,保持 ID 最好的方式是让 FLUX 不要修改面部。
FLUX Kontext 是可以识别图片里面的涂鸦标记的意思的。
你可以将你想要修改的地方圈起来,生成的时候他不会把标记生成进去,这样就可以实现精确修改,比如这个来自 @fofrAI 的案例,没有提示词就实现了换脸。
好了今天的教程到这里就结束了。
FLUX Kontext 除了强大能力之外的另一个优势是他非常便宜,编辑一张图只需要 0.08 美元也就是 5 毛钱人民币,相较于 GPT-4o 一张图 1.4 人民币的价格可以说非常便宜了。
另外他们后面还会开源一个 Dev 的 Kontext 模型这个会让成本进一步降低,太期待了。
![]()
![]()
近期,围绕 DUN.IM 的弹性流量有一些讨论。我们希望在此参照我们的 使用条款 来澄清这些问题。〔更多问题参考这里〕
在 DUN.IM,我们根据您的计划提供不同的数据访问权限,详见我们的会员计划:
我们的方法植根于 使用条款 中阐述的原则。对所有用户而言,服务旨在用于个人非商业用途。
执行这些政策有助于为所有用户维护我们服务的完整性和性能。
这对所有 DUN.IM 用户都至关重要:
您可以观看视频、下载供个人使用的游戏以及进行大量浏览。我们的系统,尤其是付费计划的弹性流量,旨在满足合法的高稳定个人使用需求。
我们的 使用条款 并未明确禁止用于个人文件获取的 P2P 或种子下载。但是,我们明确有禁止“非法活动”、“网络滥用并降低其他用户服务质量”以及“与典型个人使用不符的过度数据传输”。
因此,虽然为个人使用下载文件通常在允许范围内(用户需合理使用“弹性流量”),但诸如持续的、大流量的做种(seeding)行为,若对共享资源造成不当负担、类似于文件托管服务或助长未经授权的版权材料分发,则可能根据这些禁止用途受到影响。
对于提供弹性流量的付费计划,DUN.IM 更关注使用的性质和影响(即是否为个人非商业用途且符合我们的条款),而非设置一个限制性的硬性上限。我们关注的是用户是否遵守禁止用途列表。
请确保您的 DUN.IM 账户安全。未经授权的访问可能导致账户被滥用,如果是合法个人使用被标记,请联系我们澄清。
所有 DUN.IM 用户均在我们 使用条款 的政策框架下运营。
正如我们的 使用条款 所述,“违反这些条款可能导致您的服务被临时暂停或终止。” 如果用户在仍持续超出限额,或任何用户从事被禁止的活动,此条款均适用。
我们还年轻,可不想看到这个世界,处在毫无自由、隐私的边缘。

![]()
![]()
BlinkShot 是一个以 AI 人工智能技术即时生成图片的免费服务,这是开源项目,背后使用 AI 加速云服务「Together AI」和图片生成模型 FLUX,这项服务特性是能在非常短的时间内依照输入的提示词生成各种图片,以毫秒为单位,生成的图片也丝毫不逊色,有兴趣的朋友可以玩玩看。
目前 BlinkShot 支持英文提示词,也可以直接叫 AI 服务帮你生成〔例如用 ChatGPT 或其他同类型服务〕,另一个方法是使用图片转文字 AI 工具,例如:Image to Prompt等工具,将喜欢的图片快速转换为英文提示词,最后稍作修改再生成想要的图片。
BlinkShot 目前没有使用的生成数量限制,还有个「Together API Key」栏位可自定义自己的 API 密钥,生成的图片素材皆可免费下载使用,AI 图片基本上也不会受到版权限制,使用于个人或商业用途都没问题。
Generate images with AI in a milliseconds
进入 BlinkShot 后直接输入提示词就会立即生成图片,整体速度非常快,过程中如果继续输入其他形容或是提示词,图片会即时更新,相较于其他同类型的 AI 图片生成器来说确实非常强大!

下方会显示生成的图片历史记录。
通过 BlinkShot 生成的图片看起来很逼真,也能依照用户需求调整成各种风格、样式,越仔细的提示词就能生成更细致准确的结果。

生成过的图片历史记录会显示于下方,可以随时切换回去查看。

在图片点击右键即可下载保存。
在图片上点击鼠标右键、选择「另存图片」后将图片保存下来即可使用。
BlinkShot 未来也会加入下载按钮,让用户更方便获取图片。

