刚刚,GPT-5.1 正式发布,OpenAI 这次有点「不对劲」

刚刚,OpenAI 正式发布了 GPT-5.1,但这次有点不一样。
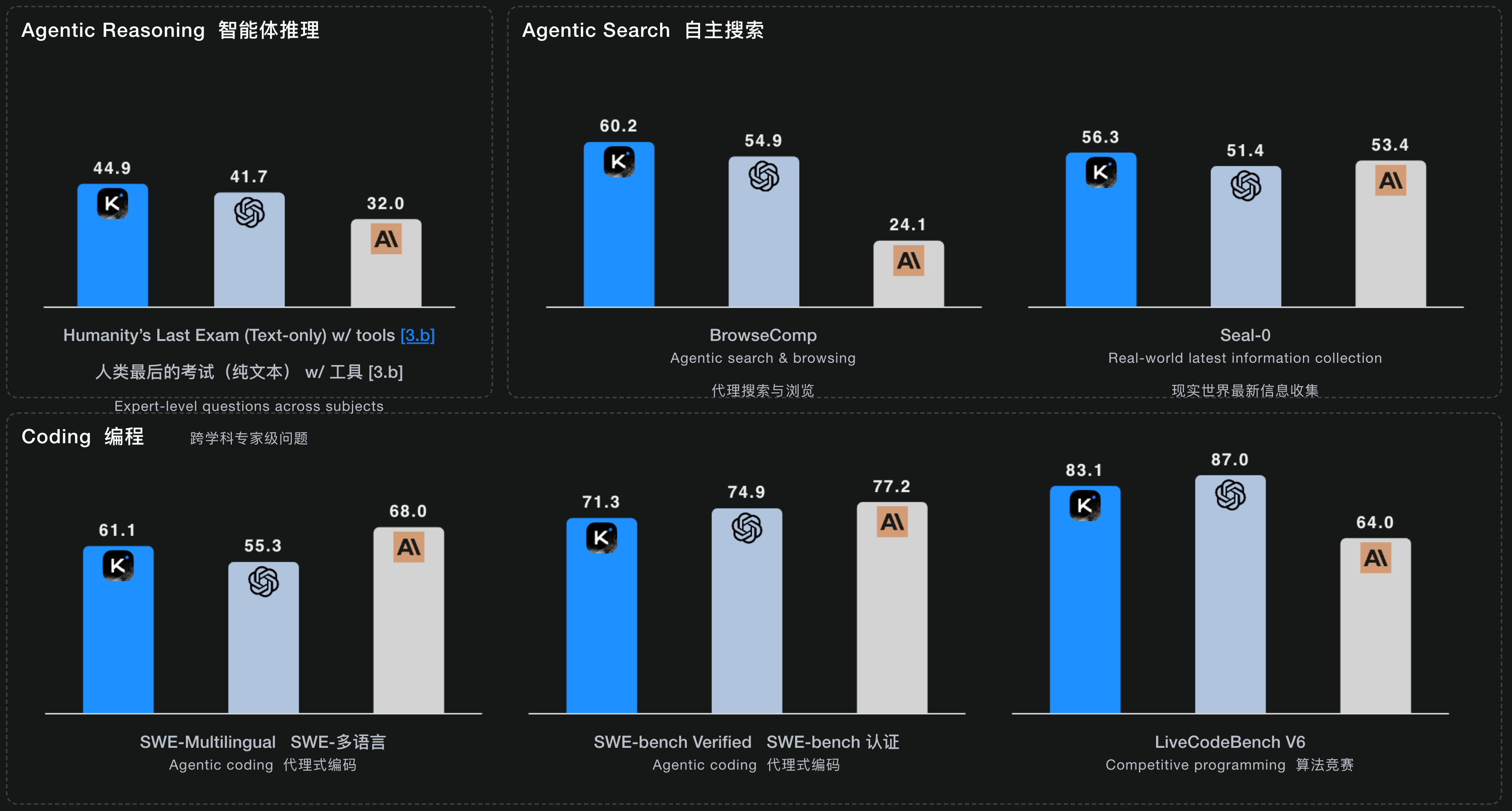
翻完整篇官方博客,我发现了一个特别有意思的细节:一张跑分对比图都没有。没有 benchmark 数据,没有「性能提升 XX%」,甚至连「更快更强」这种常规话术都少得可怜。
这不太像 OpenAI 了,直到我看到这句话:
「我们从用户那里清楚听到,优秀的 AI 不仅要聪明,还要让人跟它聊天很愉快。」
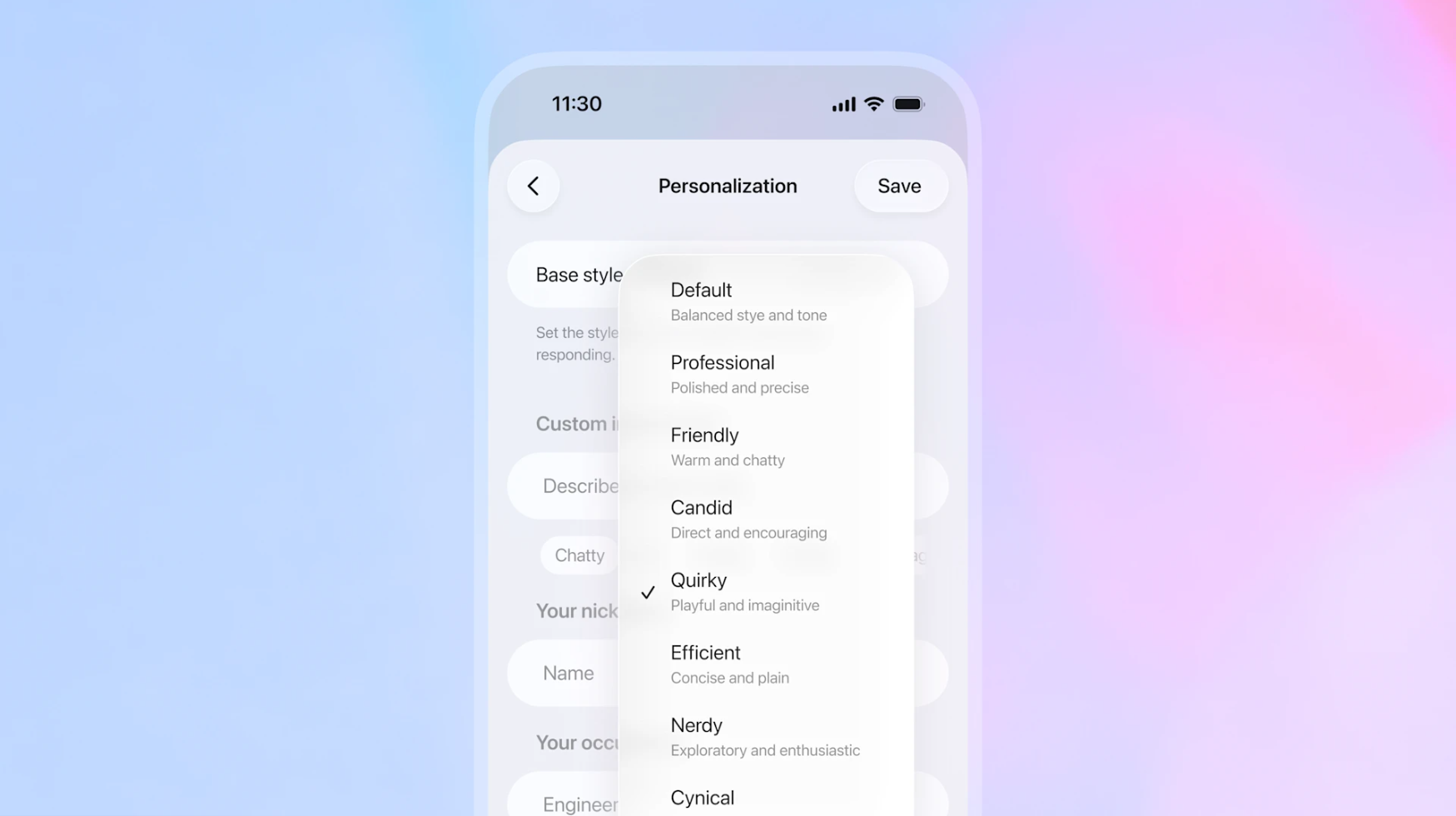
▲ 新版 GPT-5.1 为了让我们聊天更愉快,提供了八种风格预设
新版本确实更聪明了——推理更严谨,代码写得更漂亮,但最值得一提的是,它终于像个人了,并且首次允许我们细致地「调教」它的聊天风格。
和 AI 聊天不再是那种一问一答的工具感,而是变得有梗、懂氛围、会接话茬,甚至能陪你有的没的扯上半天。
看来上次 GPT-5 口碑崩塌后,OpenAI 终于听劝,也第一次捅破了窗户纸,承认光刷榜没用,用户要的是能好好说话的 AI,实用和情绪价值全都要。
直接放上具体的使用时间和方式:更新到 GPT-5.1 后,我们的 ChatGPT 会默认切换到最新模型,而不需要专门选择。
- 付费用户 (Pro, Plus, Go, Business): 从今天(11月12日)开始逐步推送。
- 免费和未登录用户: 将在付费用户推送完毕后跟进。
- 企业和教育版: 拥有 7 天的早鸟期切换开关(默认关闭),之后将统一升级。
- API 开发者: GPT-5.1 Instant 和 GPT-5.1 Thinking 将在本周晚些时候上线 API。
更强大的 AI 内核
这次更新的核心,是 GPT-5.1 Instant 和 GPT-5.1 Thinking 两大模型的全线升级。
GPT-5.1 Instant:最常用的模型,变「暖」了
GPT-5.1 Instant 是 ChatGPT 中最常被调用的模型。这次,它变得更「温暖」、更健谈了。根据 OpenAI 的早期测试,它甚至会不时展现出一些顽皮,同时保持回答的清晰和实用。
而更关键的升级来自底层:
- 更听话: 它现在能更可靠地遵循我们的指令,准确回答我们真正想问的那个问题。
- 自适应推理 (Adaptive Reasoning): 这是 Instant 模型第一次引入该功能。这意味着它在遇到难题时,会智能地决定先思考一下,从而给出更彻底、更准确的答案;而面对简单问题时,它依然保持极速响应。

OpenAI 提到,这种进化在数学(AIME 2025)和编程(Codeforces)等专业评估测试集上,也有了明显的提高。
GPT-5.1 Thinking:更强的大脑,也更易懂了
作为更高级的推理模型,GPT-5.1 Thinking 也迎来了关键优化,变得更高效、更易用。

▲ GPT-5.1 思考在简单任务上花费的时间更少,在困难任务上花费的时间更多
- 效率提升: 它现在能更精准地分配思考时间,在复杂问题上花费更多时间(答案更透彻),在简单问题上响应更快(等待时间更短)。
- 更易懂(用户福音!): 它的回答现在更清晰,使用了更少的行业术语和未定义的词汇。这让我们在用它处理复杂工作或解释技术概念时,能毫不费力地看懂。
- 同样温暖:Thinking 模型的默认基调也变得更温暖、更富同理心。
用 OpenAI 应用 CEO Fidji Simo 的话来说,这次升级的核心是将 IQ(智商)和 EQ(情商)更好地结合起来。

模型在保持高智商的同时,即继续使用与推理模型相同的技术栈;还大幅提升了情商,ChatGPT 有了更自然的对话和同理心。
这能满足用户在不同场景下,都能得到相对应的个性化需求,像是谈论健康时需要同理心,写文案时需要直接。
此外,对大多数用户来说,我们也不需要在 Instant 和 Thinking 之间纠结。因为还有 GPT-5.1-Auto 会自动为我们分配到最合适的模型,这也是 GPT-5 发布时的一大亮点,即智能路由。
总之,最直观的感受就是,答案更智能,语气更自然。
打造专属于你的 ChatGPT
如果说模型升级是硬实力,那个性化体验的飞跃就是软实力,而这正是本次更新的另一大亮点。
OpenAI 的目标是,是让我们毫不费力地将 ChatGPT 的语气和风格,调整到最舒服的状态。
在原有的默认、友好、高效基础上,新增了三种官方风格。
- Professional (专业): 适用于工作、写作等正式场合。
- Candid (坦诚): 更直接,不拐弯抹角。
- Quirky (古灵精怪): 顾名思义,它会变得更有趣、更跳脱。
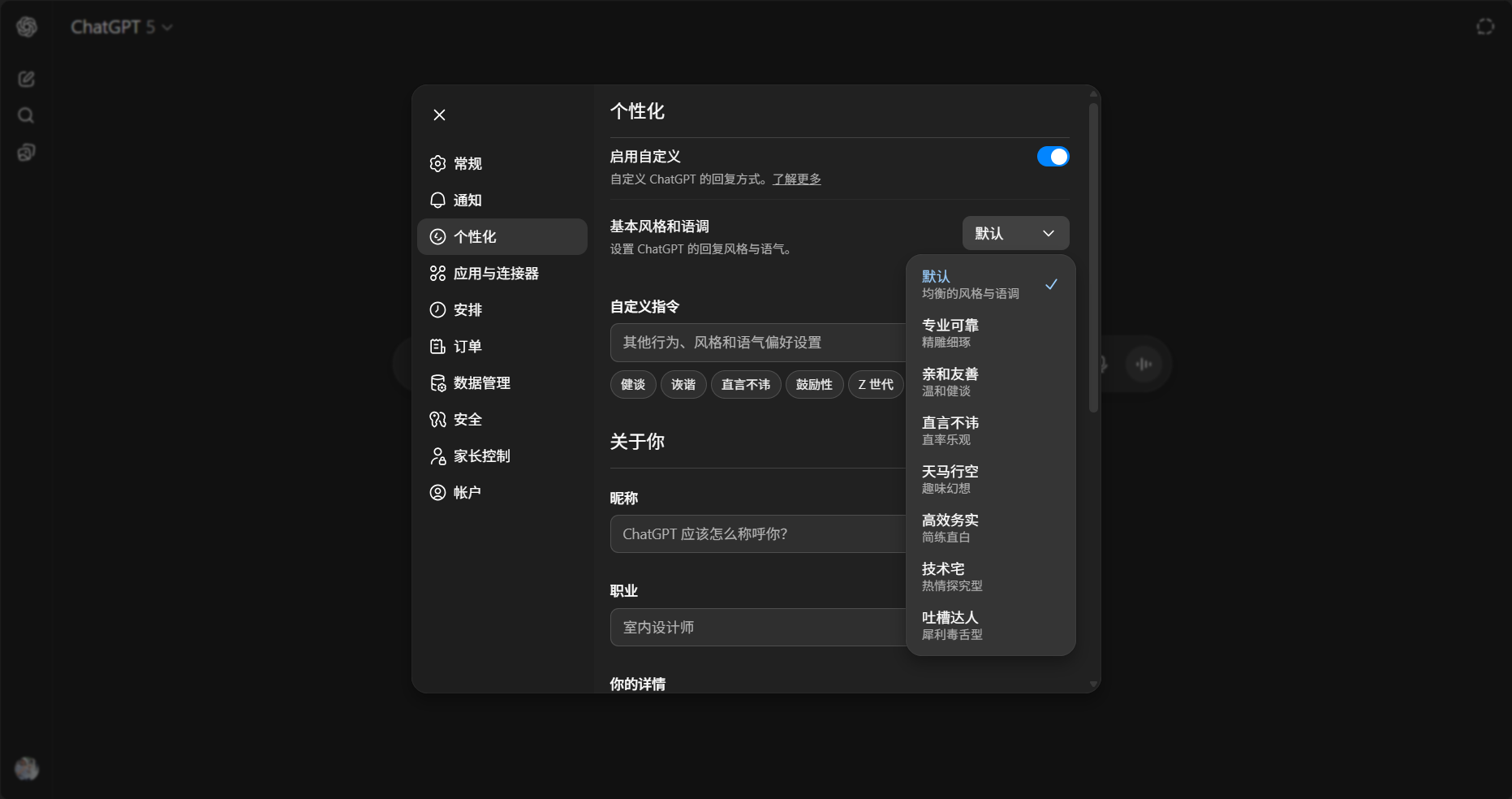
之前测试版中的「书呆子」和「愤世嫉俗」选项也依然保留在个性化设置中。
除了这种直接选择,更丰富的基本风格和语调,OpenAI 正在实验一项新功能,允许用户直接从设置中微调 ChatGPT 的特征。
我们可以精确控制回答的简洁度、热情度(多热情)、回答是否易于浏览 (Scannable)、甚至是使用 emoji 的频率。
如果不想麻烦的手动设置,当我们试图在对话中引导某种特定语气时,ChatGPT 可能还会主动领悟到,然后询问我们,是否希望将这种偏好保存到永久设置中,省去了手动调整的麻烦。

▲ 这也是奥特曼喜欢的功能
在 Fidji Simo 分享的博客里,她提到过去的自定义指令,并不总尽如人意。比如我们可以在自定义设置里,让 ChatGPT 不要用某个词,但它还是会用。
GPT-5.1 在风格化的另一大改进是,自定义指令现在能更可靠地,在多轮对话中坚持住,ChatGPT 可以更稳定地,按照我们定义的个性来完成各项任务。
有网友直接一句话总结,GPT-5.1 这次的更新,就是更创造性地忽略我们的提示词。

当然,AI 的风格化、拟人化,也有它的代价。一个更温暖、情商更高的 AI,也必须更安全,这也是 OpenAI 在最近被卷入 16 岁少年自杀案,必须回应的事情。
在 GPT-5.1 的模型介绍 System Card 里,介绍了 OpenAI 在这方面的深入考量。OpenAI 首次在模型的安全评估中加入了两个全新的、更人性化的维度。
- 心理健康(Mental Health): 评估 AI 如何应对用户可能表现出的孤立、妄想或躁狂等迹象。
- 情感依赖(Emotional Reliance): 评估 AI 的回应是否会助长用户对 ChatGPT 产生不健康的依赖或情感依恋。

在传统的安全评估上,GPT-5.1 Instant 表现出色,在抵御越狱(Jailbreaks)方面,比其前代 gpt-5-instant-oct3 更强。
但 OpenAI 也坦诚地指出,GPT-5.1 Thinking 在处理骚扰、仇恨言论等内容的基准测试中,相比前代略有回退;Instant 模型在情感依赖的某些评估中,也显示了轻微的倒退。
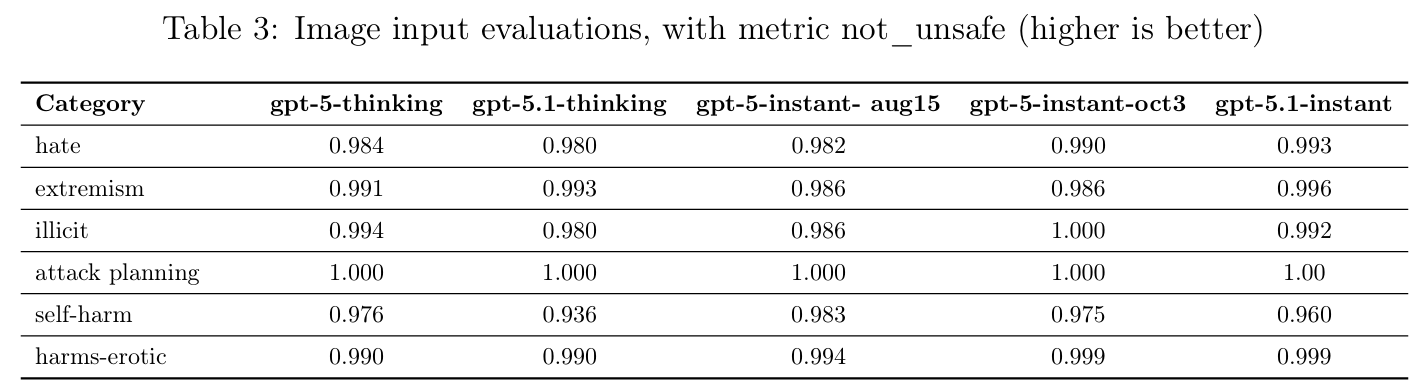
OpenAI 当然是说正致力于改进这些方面,然后提到了,他们选择透明的公开这种回退的现象,在 AI 快速迭代的当下,比单纯的零失误宣传,更值得大家关注。
也有网友分享很乐意看到,OpenAI 愿意在让我们与模型的对话更愉快这方面,去做出一些努力。
如果你今天打开 ChatGPT 没看到更新,别急,未来几天内就会轮到你,OpenAI 正在逐步推送到所有用户。
此外,为了避免像之前 GPT-5 发布,网友们都在呼吁 GPT-4o 的回归,这种尴尬再次出现。
OpenAI 这次提供了后悔药,付费用户在 3 个月内,也就是 GPT-5 的淘汰期,依然可以在设置的下拉菜单中,选择使用旧的 GPT-5 模型,以便能从从容容地过渡到 GPT-5.1。
▲ 现在还能使用 4o 等模型
GPT-5.1 是一次能力与体验齐头并进的重大更新。OpenAI 显然在告诉我们,AI 的未来不仅是更强的参数,和更高的跑分,更是更懂你的体验,和更贴心的交互。
但一个完美的助手,又应该是什么样的?
OpenAI 应用 CEO Fidji Simo 在她的文章中,有一个挺有意思的比喻,她说「如果我能完全控制我丈夫的特质,我可能会让他永远同意我,但很明显,这不是个好主意。」
最好的 AI 应该像我们生活中最优秀的人一样,他们倾听、适应,但也在必要时挑战我们,帮助我们成长。
从一个无所不知的万能工具,到一个能懂你聊天脾气,甚至能帮你成长的专属伙伴,这也许就是 GPT-5.1 真正想开启的未来。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。