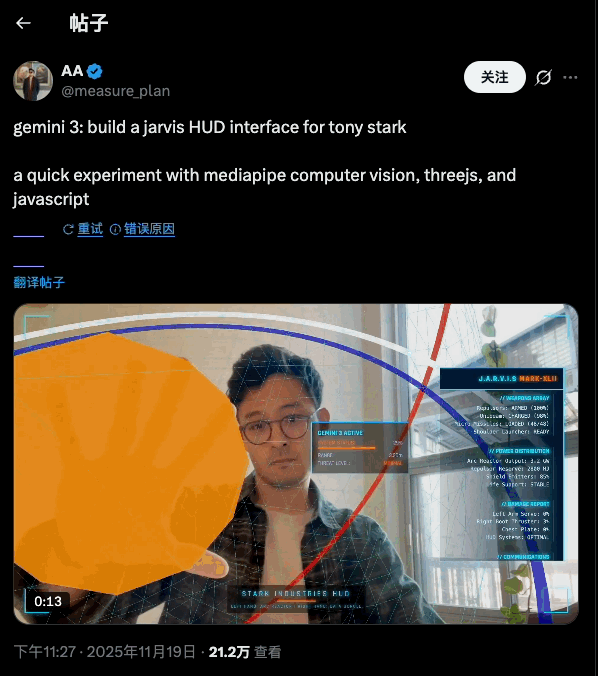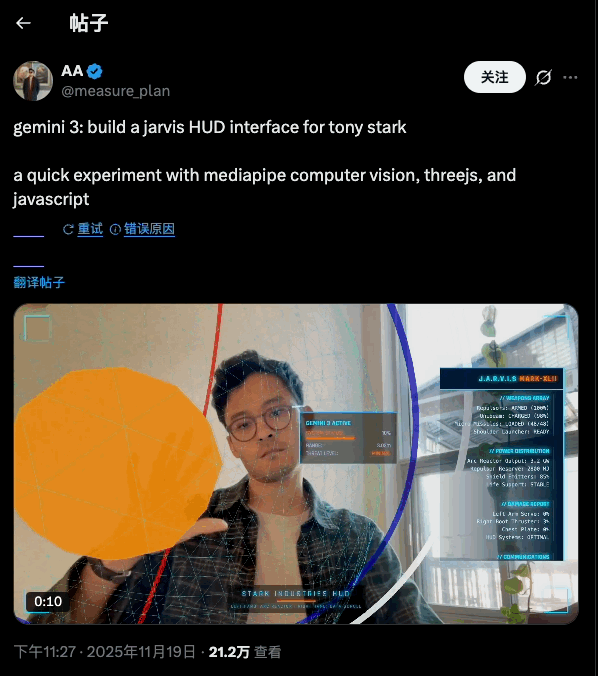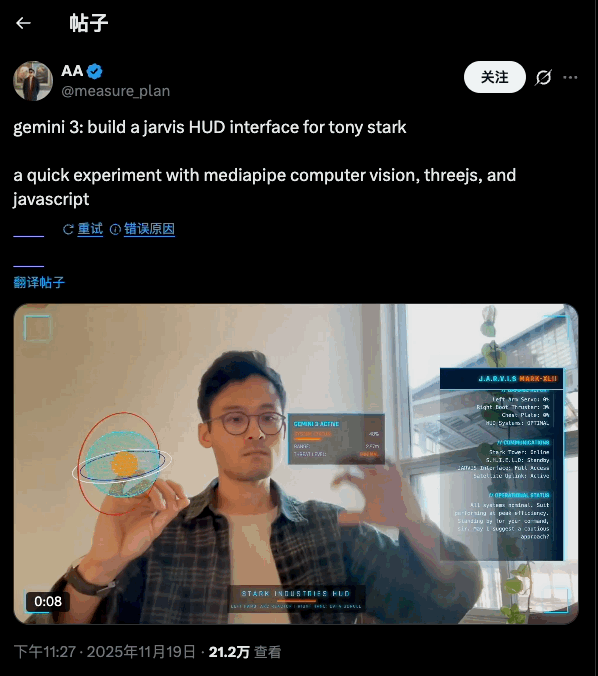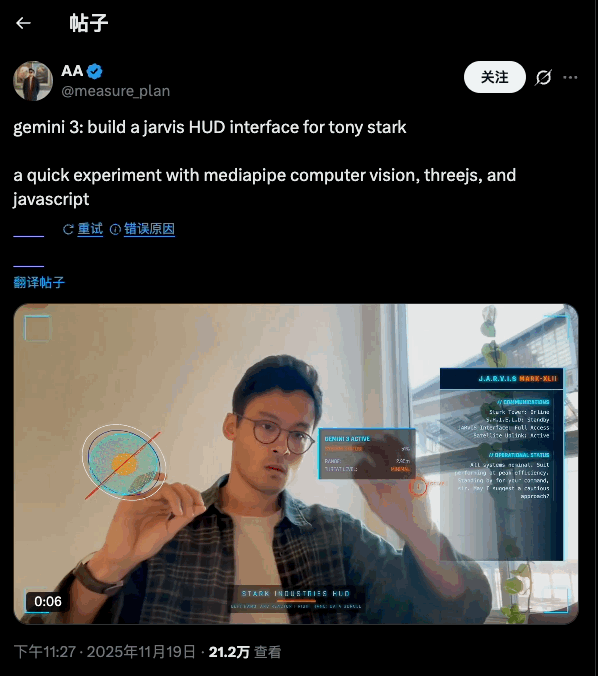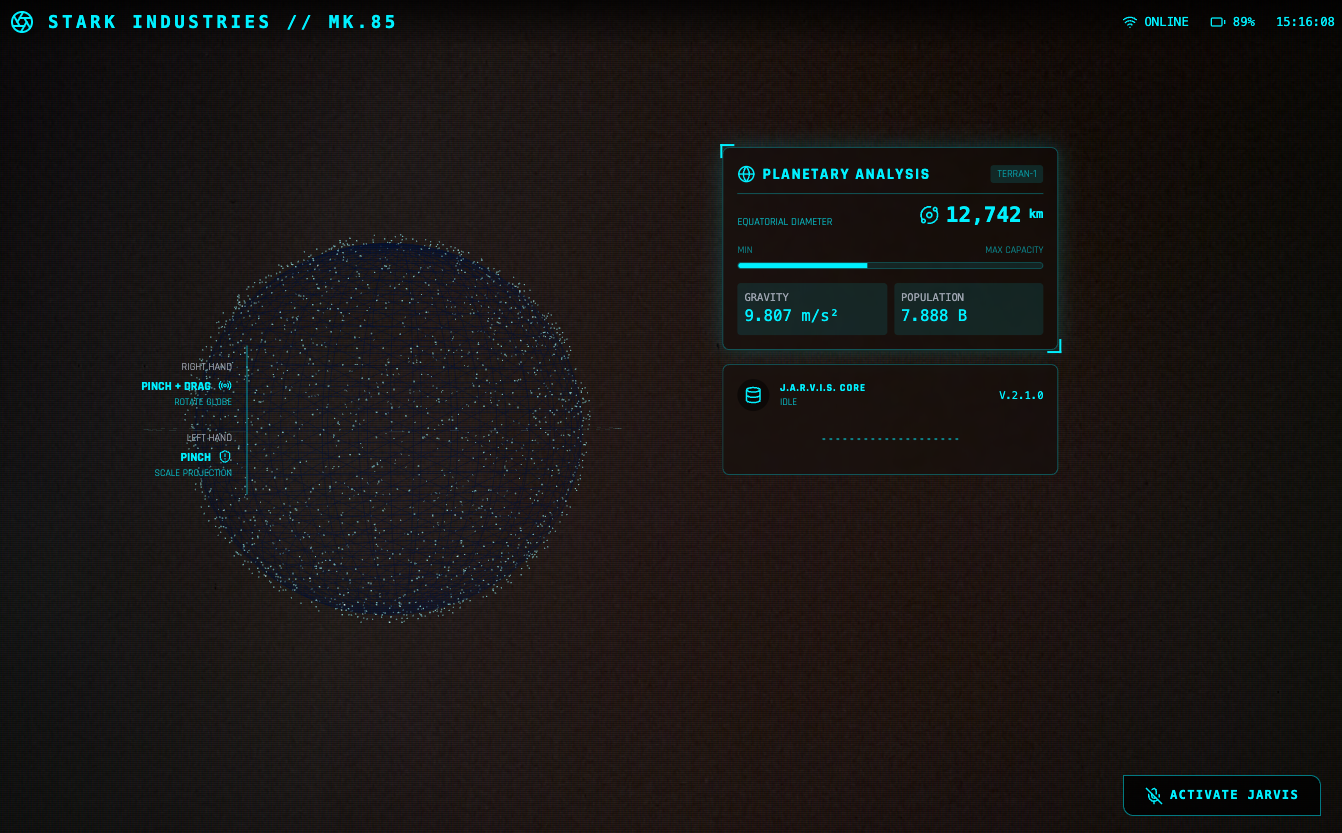
对于华为 MatePad Edge,爱范儿内部的一致观点是:
这就是二合一电脑最完美的形态。
华为给这台设备准备了两个界面,一个是典型的 MatePad 界面,另一个是今年刚推出的鸿蒙电脑界面,要用哪个就换哪个,两者都是满分体验。

当这样一台方案几乎完美的二合一产品被造了出来,一个更近一步的问题却等待回答:
电脑和平板变成了一个东西,然后呢?
MatePad Edge,首先是一个好「Pad」
不谈二合一形态,MatePad Edge 本身就是一台素质不错的平板。
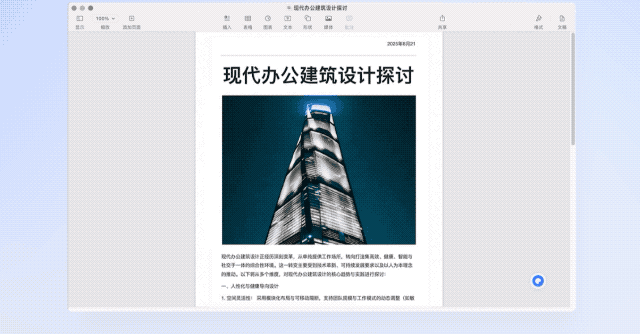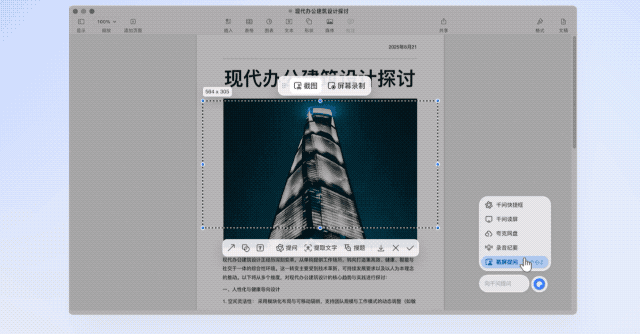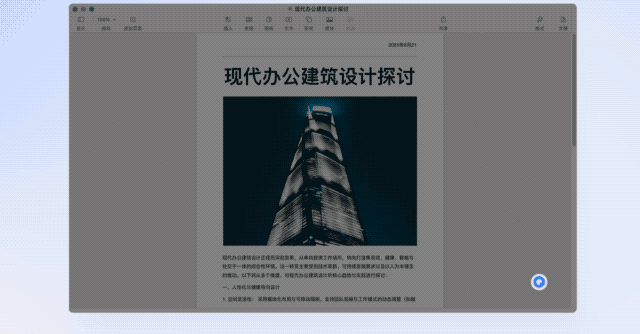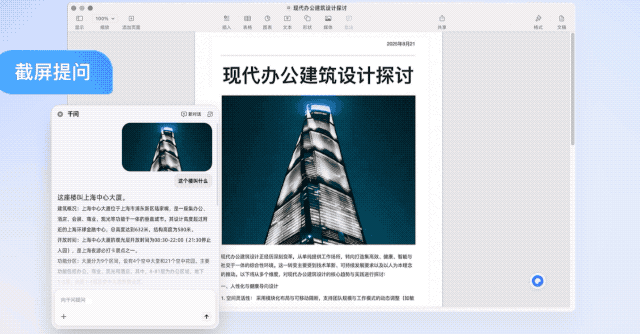
14.2 英寸、4.1mm 边框的 OLED 大屏极具冲击力,亮度可达 1000 nits,分辨率和色彩都在第一梯队。我们这台为柔光版,雾面处理能明显减少反光,户外观看更轻松。

就 5999 元起售的价格来看,MatePad Edge 称得上「买屏幕,送平板」了。
搭配这个优秀屏幕的,是高低分频的 6 扬声器配置,甚至为了进一步的影音体验,MatePad Edge 还支持和华为 FreeClip 耳夹耳机「联合发声」:平板外放视频时,耳机会补充环绕声道,实现 360° 的声场效果,营造一种家庭影院的氛围。
即使实测效果惊艳,这个功能的使用场景还是相对有限,在火车飞机这些公众场合不适合外放,回到家里有效果更好的电视和音响,更适合环境和设备有限的租房党,以及经常差旅的商务人士。
华为 MatePad Edge 类似微软 Surface,机身自带一个支架,张开的角度最大在 90 度左右,如果可以有一个更大的角度方便书写会更好。

MatePad Edge 不只是一台优秀的「爱奇艺启动器」,加上官方「星跃悬浮键盘」和完整的桌面系统,能解锁满血生产力。
这个键盘通过磁吸和 MatePad Edge 的支架部分吸附连接,屏幕悬浮于键盘之上,类似 iPad Pro 和妙控键盘模形态,这个键盘键程足够长,反馈舒适,而触控板面积够大,体验也远胜大部分笔记本产品。

不足之处在于,键盘和平板之间的磁吸力相当大,「合体」的时候容易因为吸附速度太快夹到手,取下平板的方式不太优雅,希望下一代产品能优化一下。

以及这个键盘的分量足足有 530 克,搭配 MatePad Edge 本体重量在 1.3 千克左右,比 MacBook Air 要更厚重。
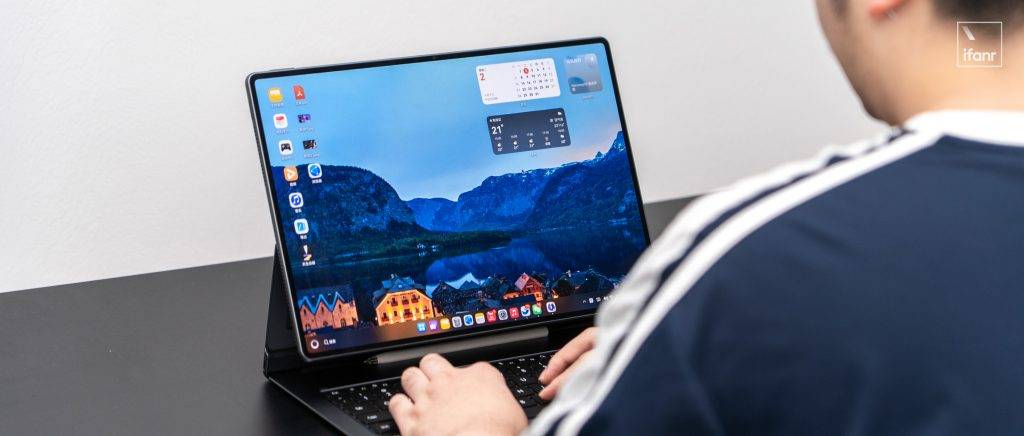
由于搭载一个完全的电脑系统,用 MatePad Edge 进行办公的很多操作逻辑都非常接近 Windows 或者 Mac,应付轻度办公,甚至用国产应用剪辑、看 CAD 都不成问题。
关于 MatePad Edge 的办公体验,我日常用电脑系统写稿,会开大量的浏览器页面写稿,午休会切换到平板模式看视频刷社媒,总体使用流畅,风扇不太会启动。

MatePad Edge 持续亮屏时间则有 5 小时左右,比我之前的 M3 MacBook Air 要略逊 2 个小时,和搭载高通骁龙 X Elite 的 Surface Pro 水平相当。
优秀的平板我们见得不少,MatePad Edge 最好玩的地方,还是这个双形态的体验。
得益于 MateBook Pro 同等级别的性能,华为直接将完整的电脑系统塞进了 MatePad Edge 中,四指轻扫屏幕或触控板,就能解锁完整的桌面界面——如果安装一个虚拟机,还能打开 Windows。
不过,开启 Windows 后,MatePad Edge 风扇会满力运行,分辨率也不够清晰,更多只能应对不时之需。
不妥协的二合一,但还能更好
第一次见到 MatePad Edge,同事端详了许久之后,问了一个非常有趣又典型的问题:
它运行的,究竟是一个平板系统还是电脑系统?
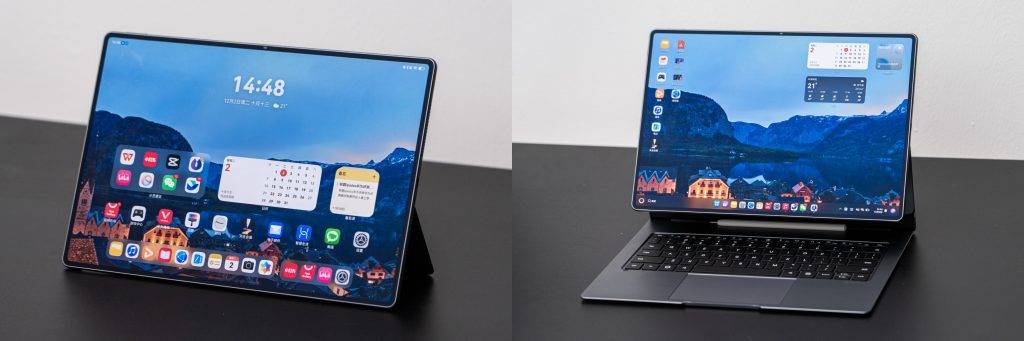
对于 iPad 和 Surface,我们能轻易地说出前者是一个传统的「平板系统」,后者是一个「电脑系统」,但对于 MatePad Edge,好像只能用「双系统」来形容。
实际上,它运行的只有一个系统——HarmonyOS,只是长了两个面孔,底层完全互通,文件和数据一致,大部分应用可以混用,将鸿蒙系统「一次开发,多端部署」的理念体现得淋漓尽致。
以往二合一设备的问题,就是「妥协」。
即使 iPadOS 26 已经吸收了不少桌面系统特性,它在文件管理和操作逻辑上都还是 iOS 这种封闭手机系统的逻辑;微软 Windows 11 则无法只使用手指交互。

早在 Windows 8,微软就尝试在一个系统中,塞进截然不同的磁贴触控界面和传统桌面界面,但 Windows 本质还是桌面键鼠系统,两套逻辑操作和设计割裂,最终被用户否定,又回归了传统桌面风格。
这两年才诞生的鸿蒙电脑,身上并没有这种历史包袱,特别是鸿蒙电脑,本身也是基于鸿蒙平板界面打造,两者之间的界限并没有那么分明。
不过,实际体验下来,MatePad Edge 并没有打磨得那么完美,在体验上还有不少进步空间。
比起 iPadOS,鸿蒙电脑已经算是一个正儿八经的桌面系统,系统的交互方式和 Windows 以及 Mac 基本一致,只是这个系统依旧还需要更多打磨,目前还是存在不少 Bug。
应用生态上,微信桌面版的完成度远高于手机鸿蒙版,可以给一个好评;大部分轻度办公和创作应用都有「国产版」可以平替,更致命的是没有一个足够好用的第三方浏览器应用。
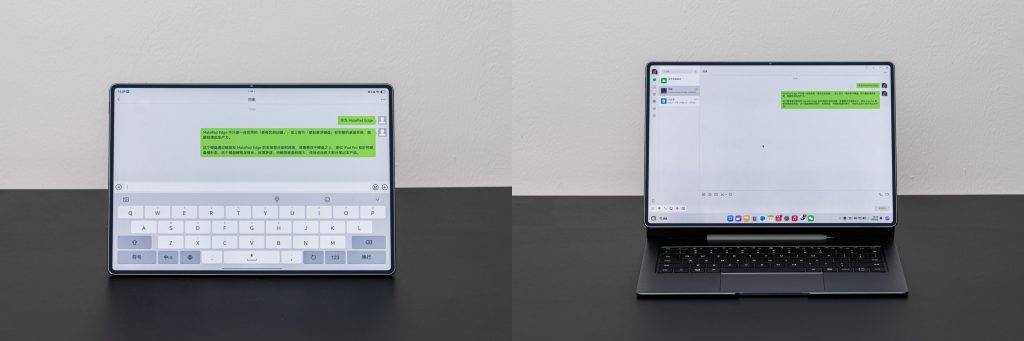
最大的痛点,就在于这个「切换」上:每次切换的过程,其实就是一次设备的重启,会关闭所有打开的应用。
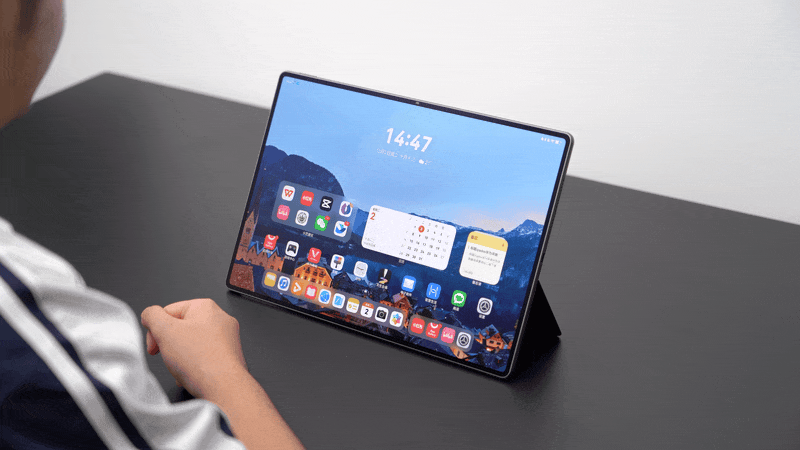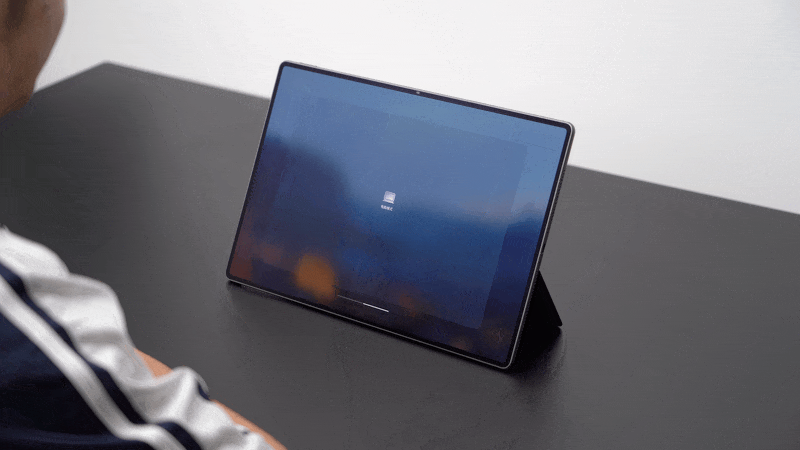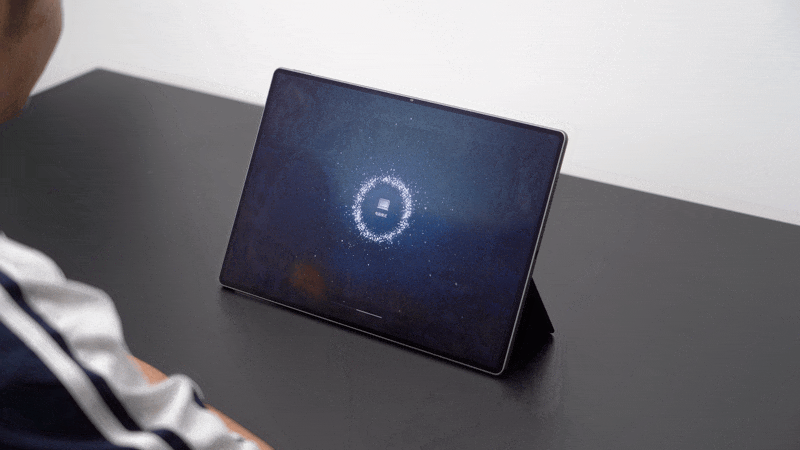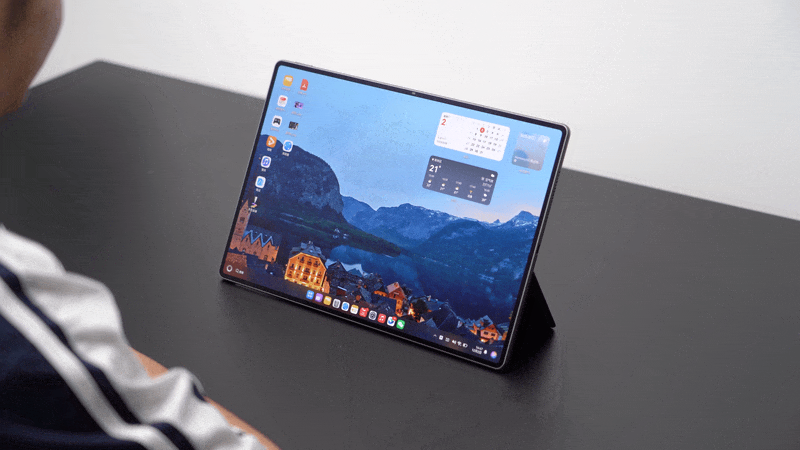
例如,我用鸿蒙电脑写稿,浏览器打开了一堆标签页,午休的时候我用平板模式看 B 站刷小红书,那么切换之后,我打开的浏览器和写的草稿会全部被关闭,即使回到电脑系统也不会恢复。
并且,由于两个系统的交互方式迥异,有一些应用——例如微信,会提供平板和桌面两个版本,不仅需要分别在商店下载,两者的数据也并不互通。
还有一些应用,像是哔哩哔哩和飞书,则干脆没有鸿蒙电脑版本,电脑模式只能用鼠标去点击硕大的标签按钮。
这种问题甚至存在于鸿蒙系统的服务之中。我在电脑模式想进行一些实体键盘的输入设置,却发现它的设置全部都只针对平板模式虚拟键盘。
我理解这两套系统之间有一些不相通的系统组件,交互方式也不甚相同,但对于一台强调「无缝体验」的设备来说,这些痛点让我更倾向于主要使用一种模式,一下子让「二合一」的价值大打折扣。
这些小毛病,更多是这个形态和系统过于青涩所致,相信随着时间推移,华为和应用开发者持续打磨,最终都能很好克服。
更重要的问题是,当 MatePad Edge 这台被公认为「最理想的二合一」真的问世了,我却还是没感觉这个形态能带来什么新的价值:日常办公的主要方式依旧是传统的鼠标和键盘,给人感觉和一台传统笔记本并无差别。
让触控屏,成为电脑
就在这个时候,我忽然想起来前段时间有两个朋友找我推荐平板电脑。
第一位朋友,他想买台平板在更大的屏幕上刷短视频和看剧,不过也问我要不要买一个键盘盖,满足工作处理表格和文档的偶尔需求。
最后他被平板系统 Excel 的糟心体验劝退,打算让平板当全职的娱乐工具,但这种「想给娱乐工具增加一点生产力」的需求,也给我带来了一些思考。
问题其实不是「把电脑变成平板的意义」,而是试图为「平板」这个形态,寻求一些新的价值,就像是苹果,我相信「MacBook 支持触控」,从来都小于「macOS 进入 iPad」的呼声。
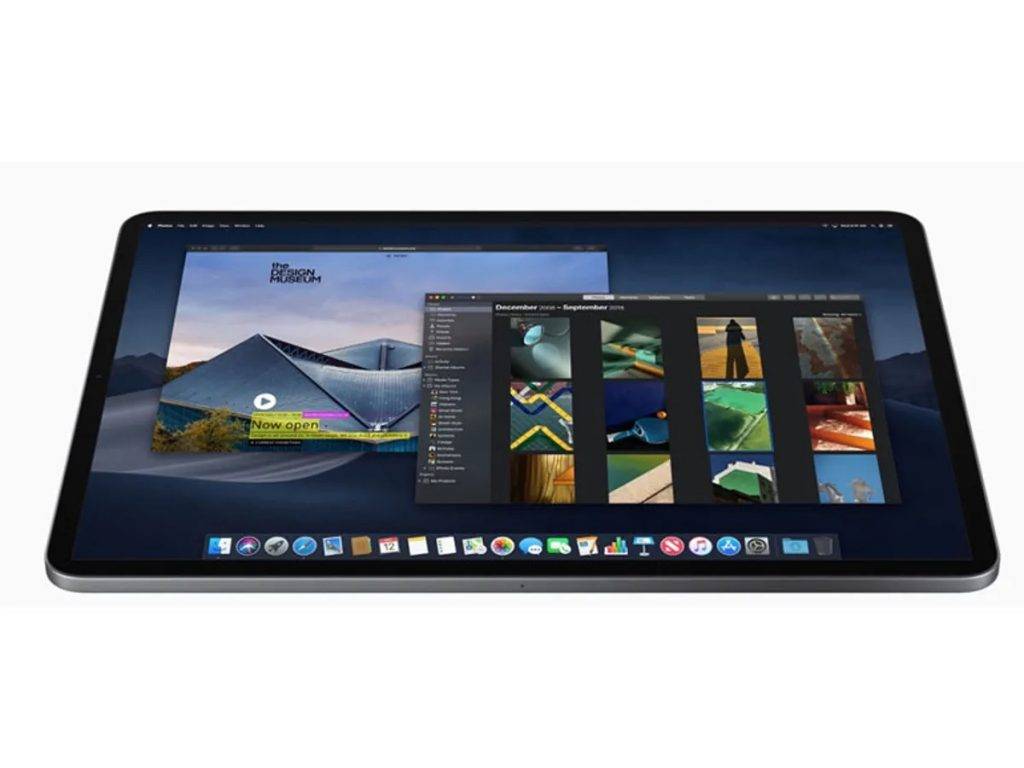
而 MatePad Edge 这个命名,其实也说明这首先是一台 Pad,再是电脑。
另一位朋友,他只有台式电脑,想要买一台能带着走的计算设备,于是选择了 iPad,不选 MacBook 的原因很简单:他是一位画师。
最近他也跟我分享,他爱上了 iPad 上的 Logic Pro X 玩音乐,然后决定买个 Mac mini 进行深度探索,不过更喜欢平时用 iPad,因为交互更简单直接,平时上手就能玩。
传统电脑还是大部分人的首选,但世上的职业不止三百六十行,工具也不应该只有一种。

之前在与爱范儿的访谈中,苹果高管 Kurt Knight 认为,「生产力」并非固定不变的概念,而是随着时代和用户需求不断演化。每位用户都有不同的工作方式,也就对应着不同的生产力场景。
像是学生、画师、飞行员等等需要用到便携大屏和手写输入的人员,平板 + 笔的搭配已经能胜任大部分的工作场景,加上键盘化身「桌面端」后,更是具有了进一步的生产力,电脑的出场机会更少。
随着抖音、小红书这些图文、短视频社交平台的大行其道,创作从未如此贴近所有人的生活,手机可以成为最佳的镜头,二合一平板本来也是消费这些内容的最佳载体,现在也能成为不错的生产工具。
从一个更长远的视角出发,「二合一」更具有「明日产品」的地位。
2018 年,苹果发布了一条 iPad Pro 的广告,片中 10 岁左右的主角带着 iPad 走遍城市,最后领居问她在用电脑干什么,她说出了那经典台词:
什么是电脑?

对于出生就被触控屏幕包围的年轻一代来说,平板电脑不仅是他们第一台拥有使用权的计算设备,还会是相当长时间里的唯一一台——网友不会解压」「不会用安装包」现象,也折射出电脑使用习惯的变迁。
我们曾经以为,等到这批新生代开始进入大学和工作,不得不用鼠标键盘的时候,他们的习惯和方式会被这种更高效率的老派模式替代。
但事实证明,触控交互反过来影响了产品形态。
在我们编辑部,MatePad Edge 的使用方式被分成了两派:
小时候只接触过电脑的同事,几乎不会想起这是一台能够触屏的平板;更伴随着平板电脑长大的年轻同事,虽然 80% 的工作时间都在用键鼠,也会自然地经常伸手点击屏幕,甚至换回 MacBook 后还有点不太习惯。

在海外,从小就用 iPad 和 ChromeBook 二合一学习的孩子们,从小就已经更习惯用这些设备做作业和上课;等他们长大,自然也会选择交互和形态更熟悉的产品——渐渐地,二合一设备就能蚕食传统笔记本的市场。
总而言之,芯片算力已经到达了一个新的阶段,「电脑」早已经不止是某种形态计算设备的专属名词,而是一种能力的体现。
历史或许会再一次重演:鼠标和图形界面诞生之初,工程师和开发者就认为,鼠标这种输入方式地效率比键盘命令行效率低下太多,图形界面还浪费性能。但最终,这两种革命性的技术成功让电脑出现在了更多人的桌面。
说到这里,MatePad Edge 的价值已经相当明显:
现阶段,它更多是一款「买一送一」性质的产品:如果你只是想买一台平板电脑,那 MatePad Edge 不仅是优秀的 Pad,还送你一个完整的鸿蒙电脑系统,以备生产力的不时之需,怎么看都挺划算。

尤其对于画师和学生来说,MatePad Edge 以及鸿蒙电脑适合作图和记笔记的任务,同时也兼具一些文稿和图像的处理能力,最适合不过。
放到整个行业,MatePad Edge 则给「二合一」这个有点走到死胡同的品类,撕开了一个新的口子,提供了一个新的思路。
而或许在一个更远的未来,更多人手上和桌面上的,都会是这样一台带着键盘的平板电脑,娱乐工作,触控键鼠,一台产品全部能做到,成为一台不加前缀的「电脑」。
(本文写作全程使用 MatePad Edge 撰稿)
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博








 「太长不看」版:
「太长不看」版:













 :
:









 」。
」。








































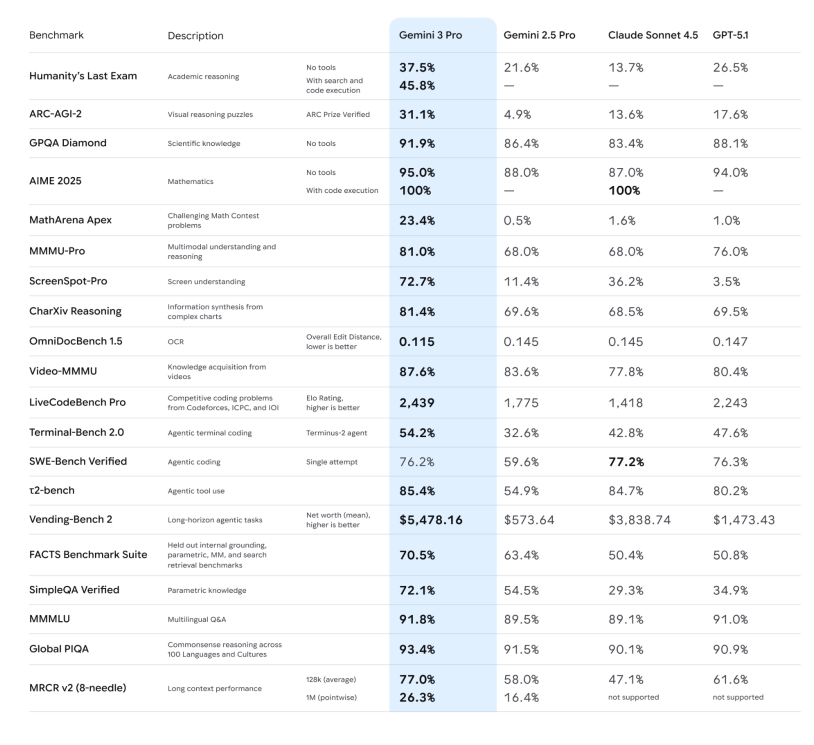 -推理能力:官方强调 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高难度推理和数学基准上,全部刷出了新高分,定位就是「博士级推理模型」。
-推理能力:官方强调 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高难度推理和数学基准上,全部刷出了新高分,定位就是「博士级推理模型」。