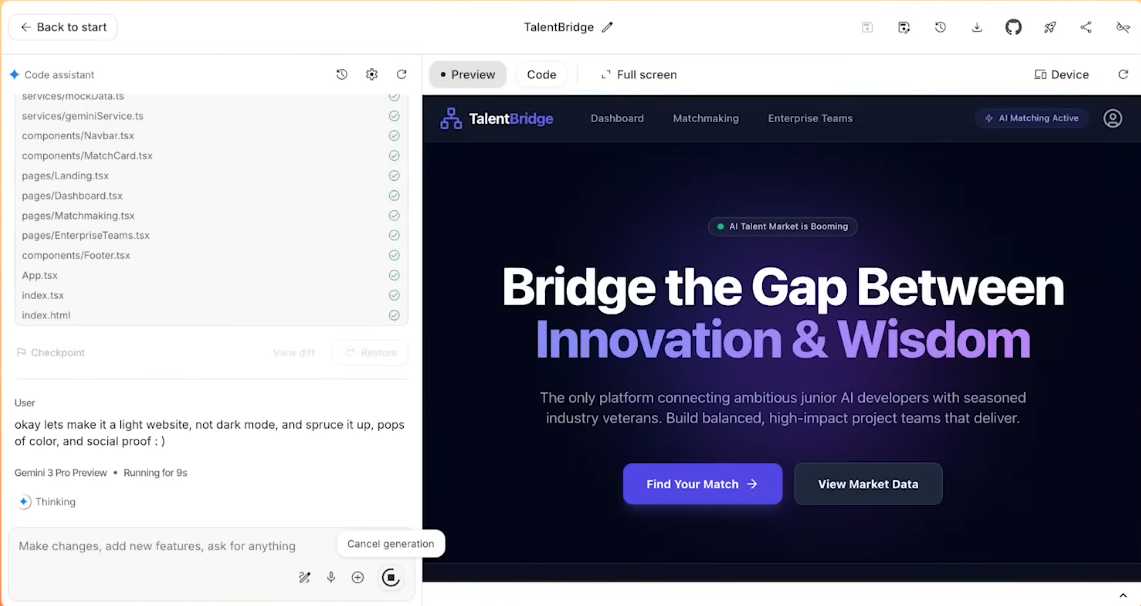
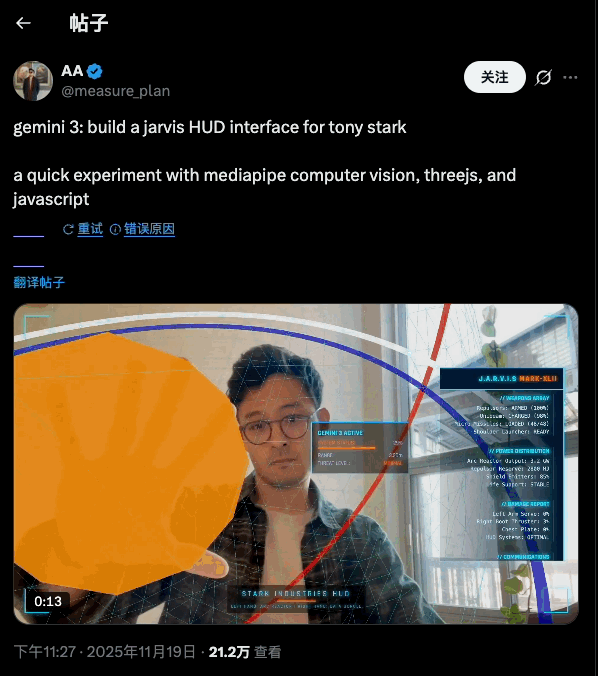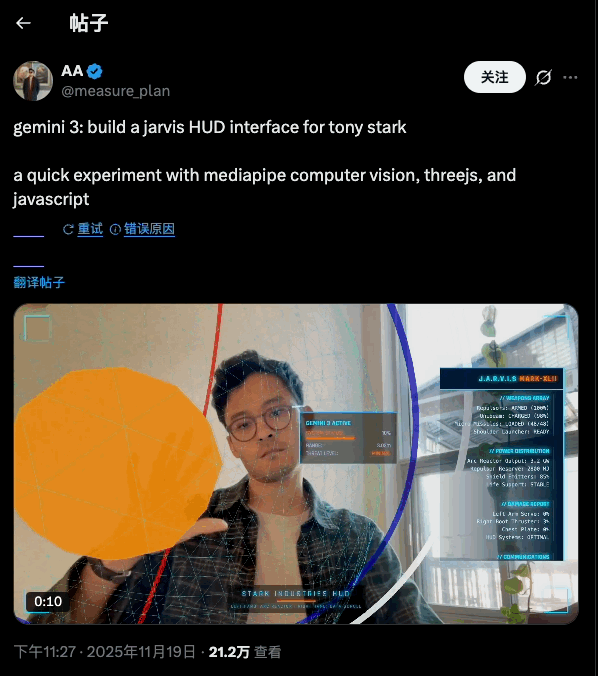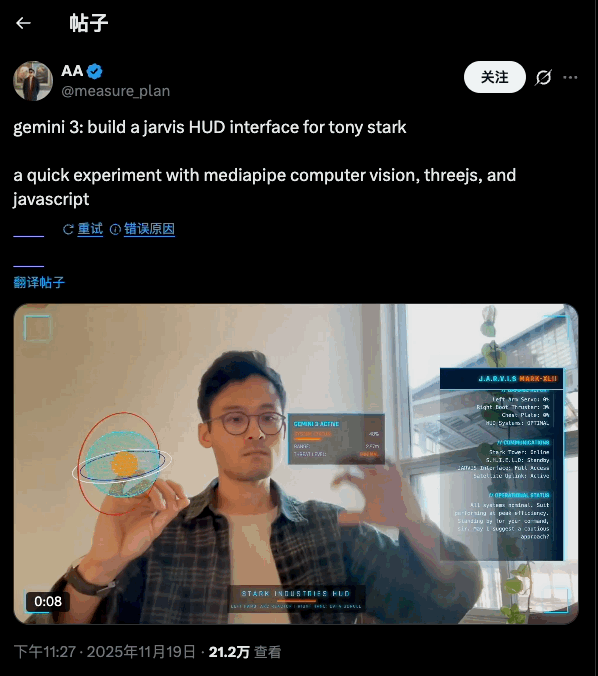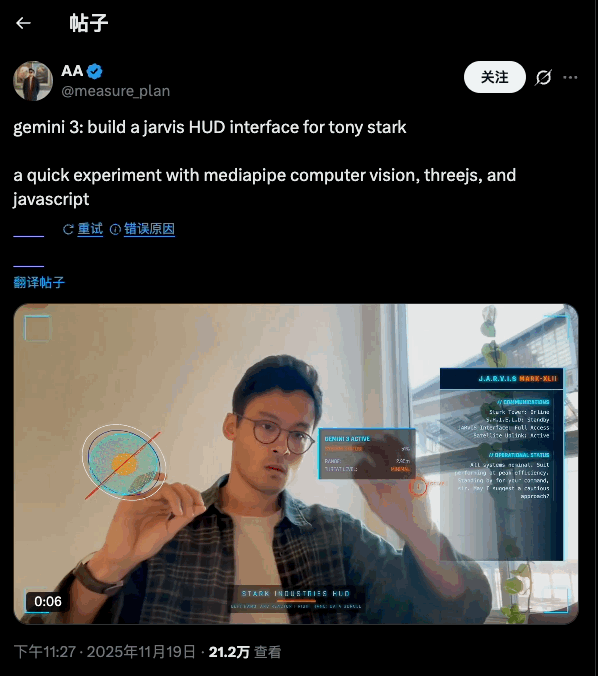
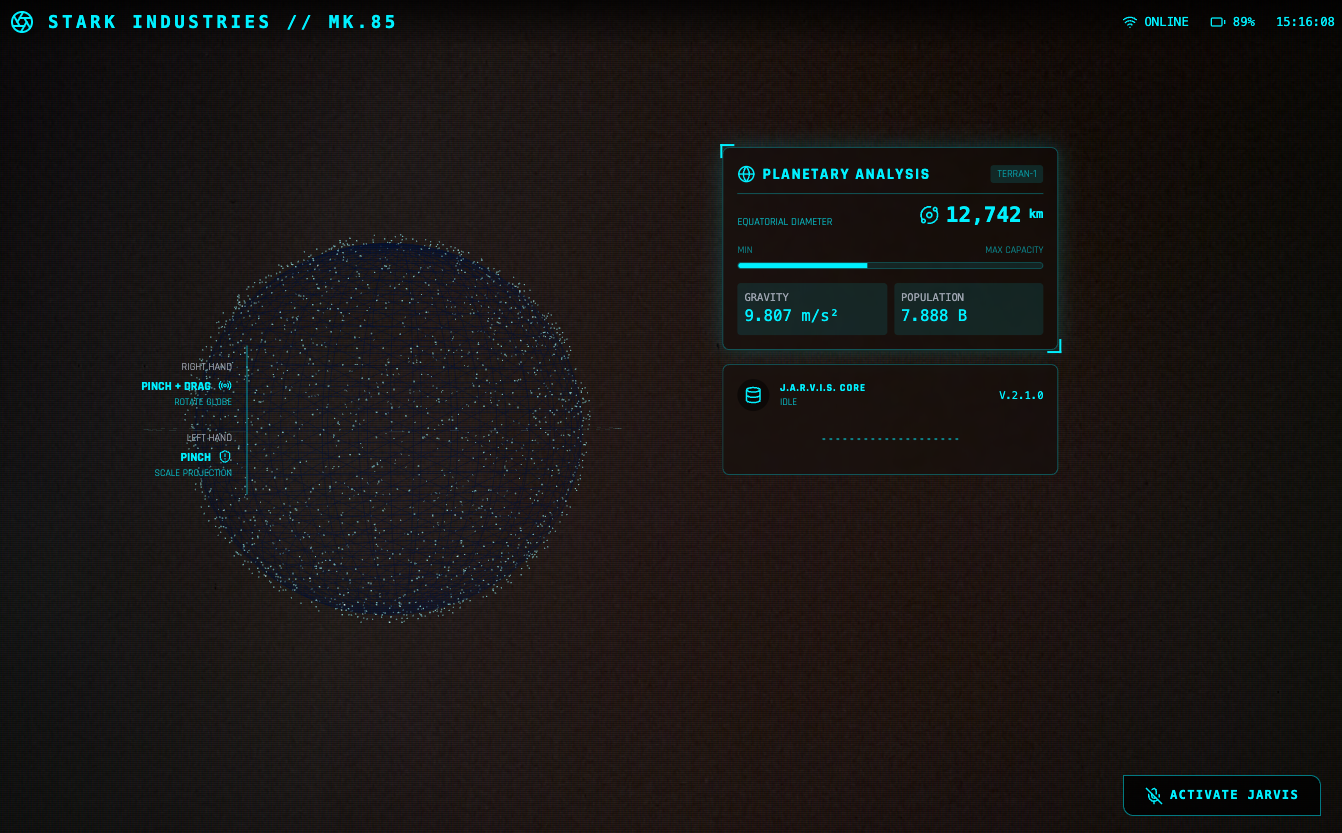
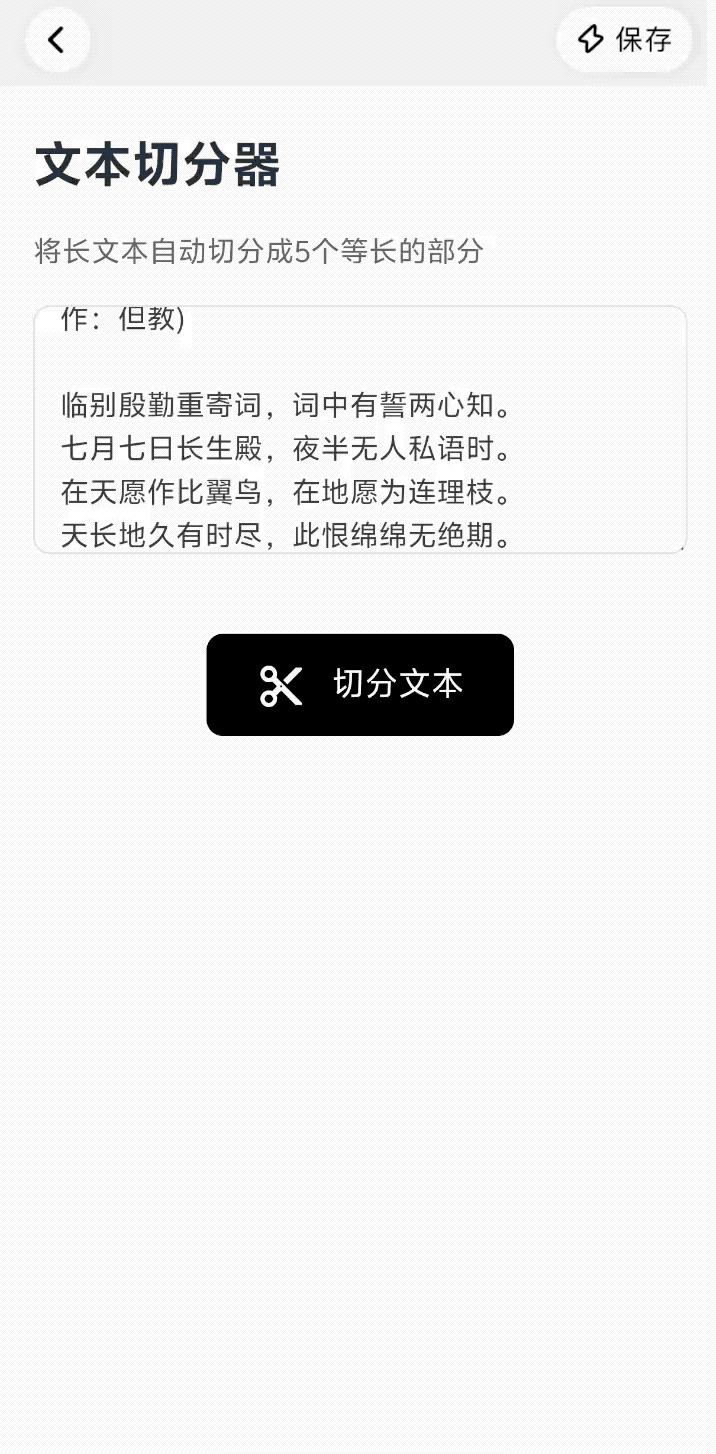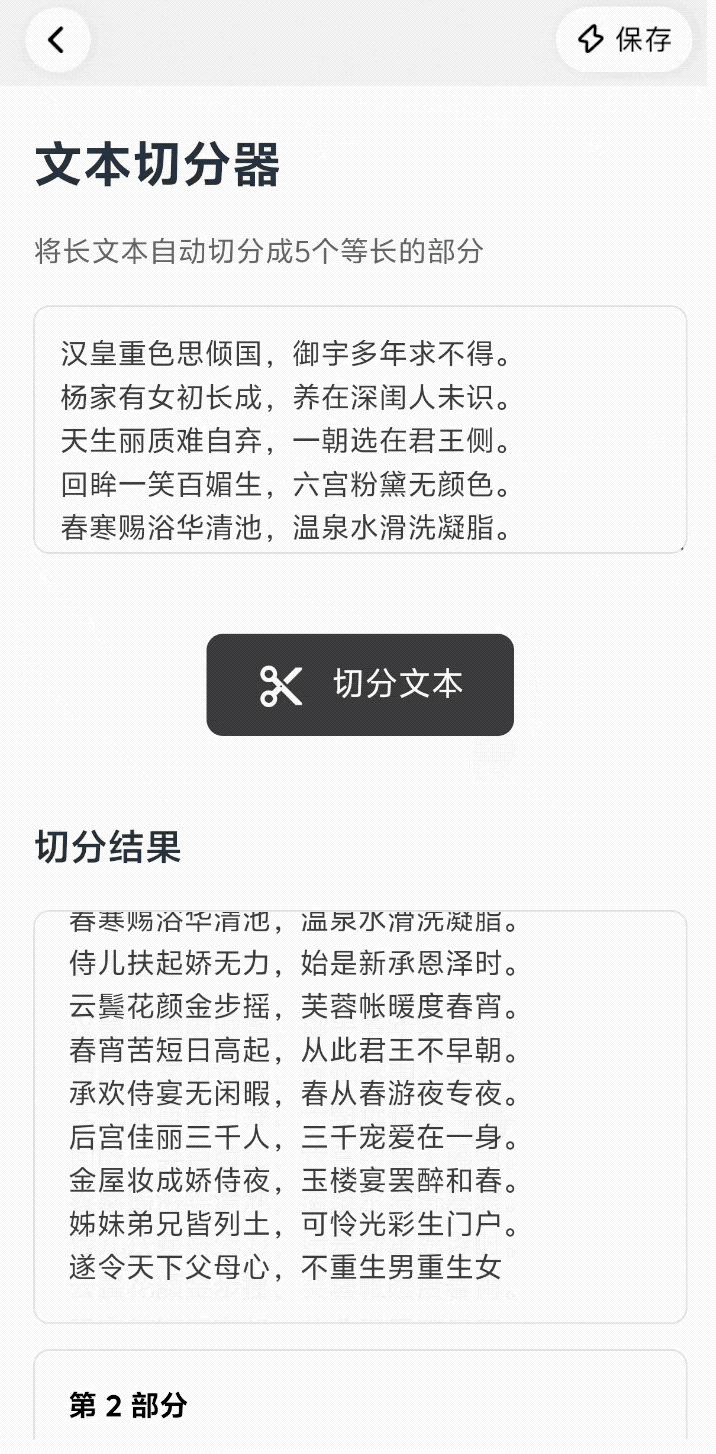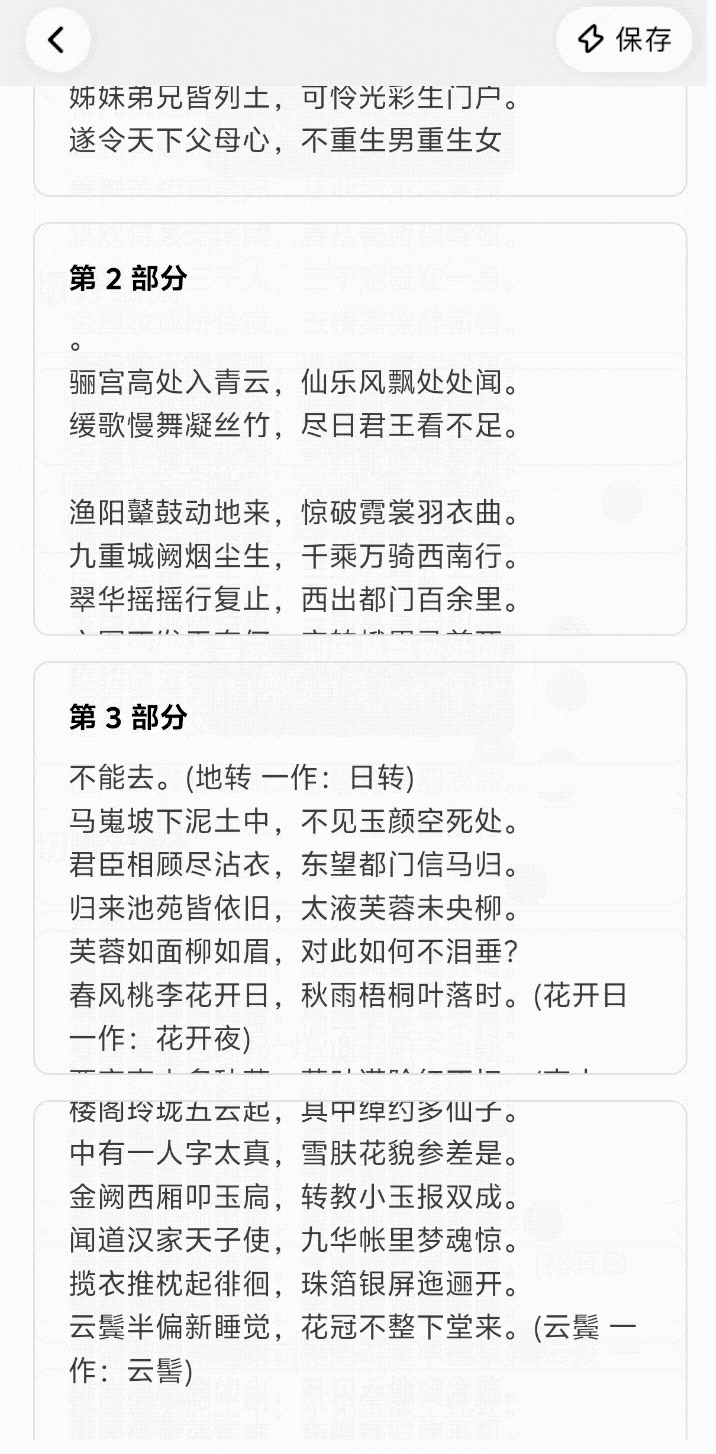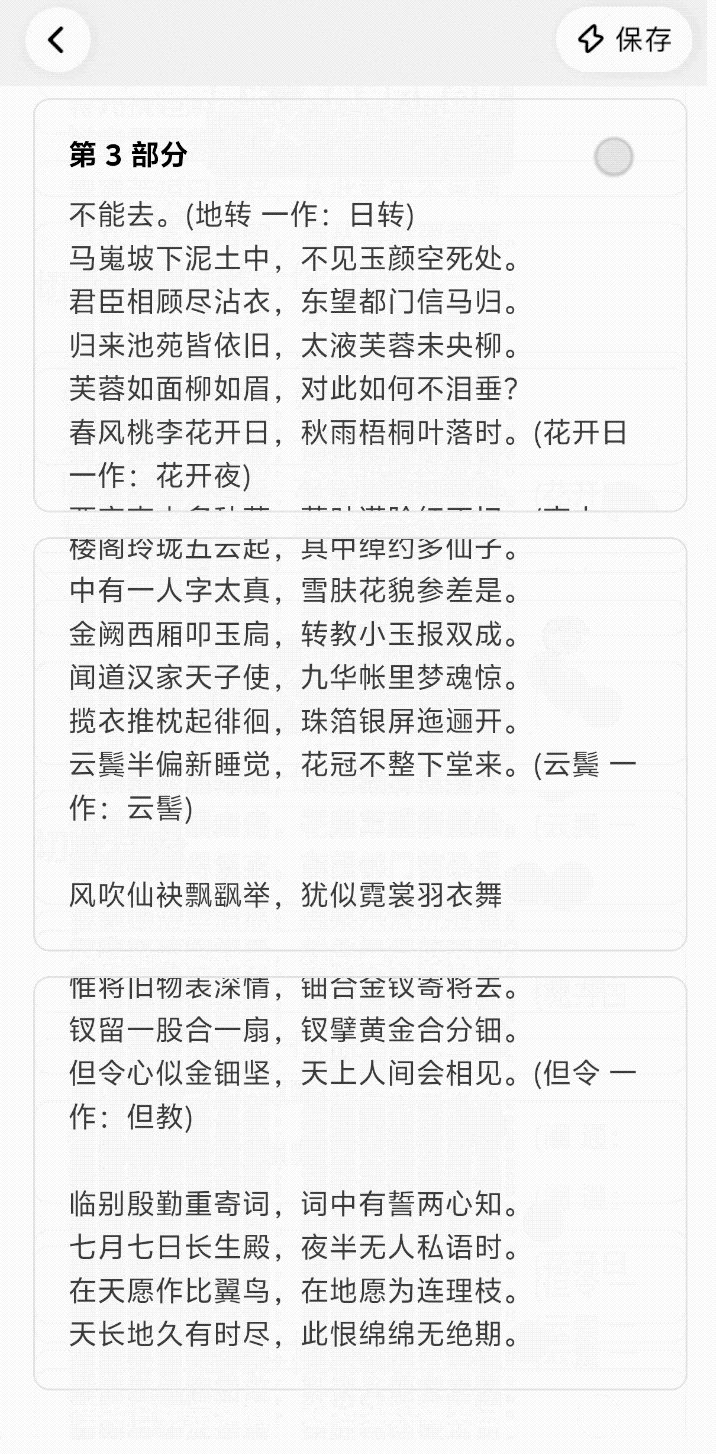
说实话, AI 生图工具有时候真的让人又爱又恨。
刚认识的时候(第一次生成),你会觉得它惊为天人,哪哪都好;可一旦你想跟它深入发展(做成系列图、落地进工作流),它就开始「掉链子」,陷入抽卡玄学。
这种「只能看不能打」的状态,真拿它干活就会无比「拧巴」,在 Nano Banana 这样的工具出现后,事情终于开始改变,原来 AI 是可以被更精确控制的。
现在,终于也有国产 AI 接力,进一步把这条路跑通。Vidu Q2 最新上线的文生图、参考生图、图像编辑功能就是这个路子:卷完「好看」,它开始死磕「稳定性」。
这次 Vidu Q2 直接把技能点全加在了「一致性」上。什么概念?就是把「人设崩坏」、「产品变形」、「画风突变」这些老大难问题统统按在地上摩擦。
简单说,它不只是想让你发个朋友圈炫技,而是真想让你拥有一套能「从头用到尾」的实用创作流。
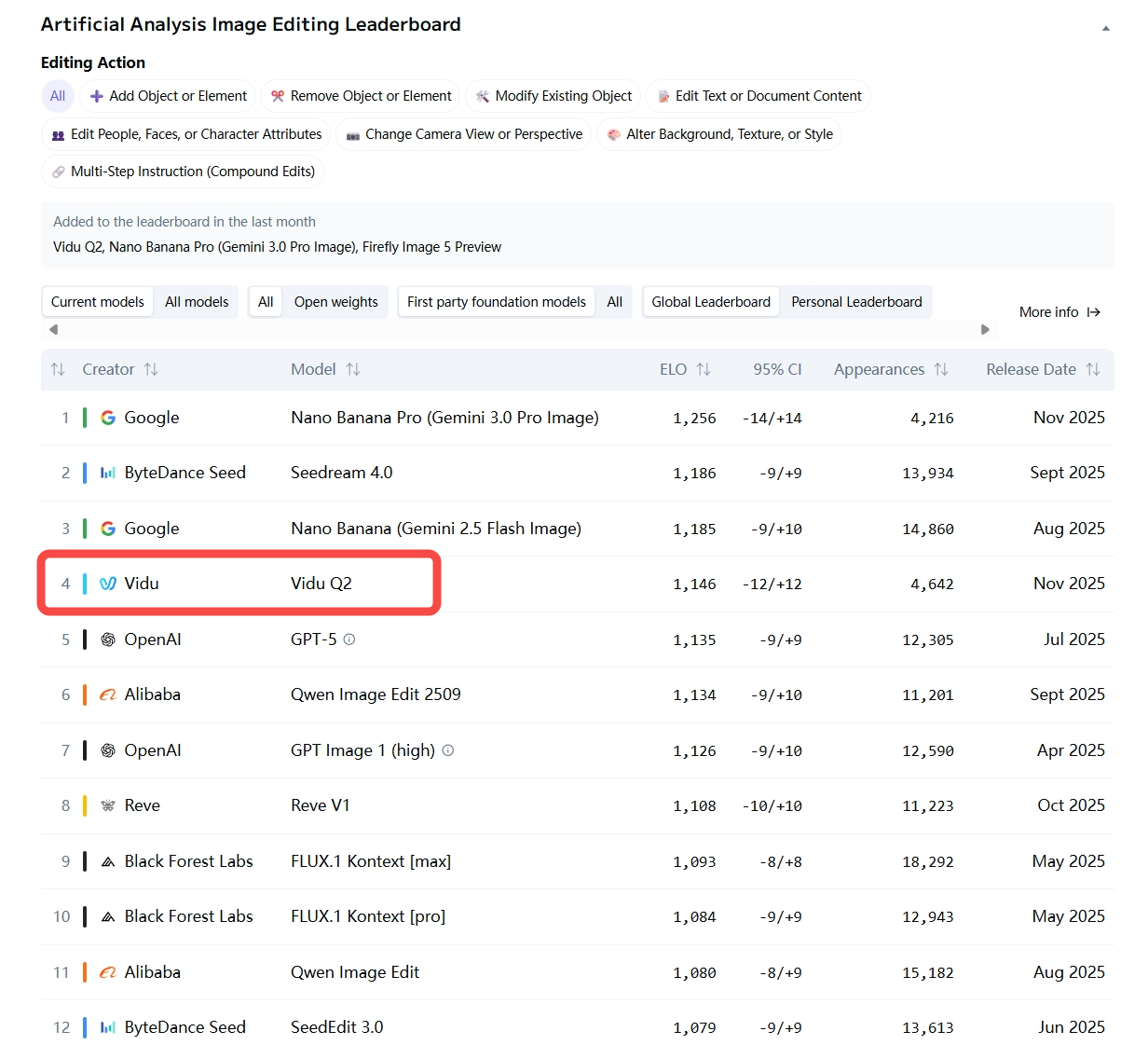
在最新的 AA 榜单里,Vidu Q2 首次上线的图像编辑能力甚至超越了 OpenAI 的 GPT-5,最难能可贵的是,作为成立才 2 年多的创业公司,用技术实力说话,跟 Google、字节这种大厂并列前三,追赶 Nana Banana Pro,直接把「省心」两个字拿捏了。
Vidu 还搞了一个长达 1 个月的「免费大礼包」,敞开大门让大家薅羊毛。即日起至 12 月 31 日,Vidu 会员生图「免费」,无论是参考生图、文生图还是图像编辑,统统随便造。标准版和专业版会员每月也有 300 张免费额度,旗舰版更是免费无限生图。
今天我们就趁着这个「无限续杯」的机会,拿 Vidu Q2 的生图功能狠狠考验一下,看看它到底能不能拯救我们的发际线。
开局一张图,剩下的全靠它「脑补」
Vidu 在一众 AI 工具中,是最早就把「围绕一张图持续参考创作」当成核心能力来打磨的。在国内多参生图中支持的输入图数量最多,一致性也最高。
在最近 Vidu Q2 的更新里,这项能力又被往前推了一大步:不仅支持更复杂的多参考组合,还大幅降低了生图门槛——设计师、导演、甚至是喜欢创作的普通用户,都可以用自己熟悉的方式提供主体图和环境参考,由模型一键复刻动作、位置、布局、纹理、光线、色彩等,自动去「对齐要求参考图、保持角色不变」。
多参生图
在多参生图场景下,我们给 Vidu Q2 参考生图的输入非常接近真实工作流:一张是最近的全运会「顶流」大湾鸡,另一张是希望出现的场景氛围,夕阳下外滩的观景台。
然后我就写了一句简短的提示词,剩下的全交给它。

结果出来,我直接「瑞思拜」。
它不是那种傻瓜式的把主体抠图贴上去,而是真的在这个场景里「重算」了光影。主体的光影方向会跟环境一致,动作也随着指令准确变化。
甚至我让它变成喷绘印在汽车上,连车身上的倒影色彩都给你算得明明白白。

更关键的是,多次生成不同构图和姿势时,许多都能保持高度一致,比如大湾鸡胸前的图案、头顶的彩色冠,这一点在传统靠 prompt 调参的生图流程里往往很难做到。
这就很灵性了。对于品牌方来说,以前要把一个 IP 形象放到不同场景里做海报,得建模、渲染、P 图,现在?几秒钟搞定,而且那种「违和感」完全消失了。
空间一致性
更绝的是 Vidu 对空间关系的理解能力,当我要求「大湾鸡穿梭在故宫雕花栏杆中」时,Vidu 并没有像其他 AI 那样跟栏杆穿模,或者变成恐怖片现场。
它居然先根据环境图「脑补」了故宫的空间结构,让大湾鸡自然地走在走廊空间中。

再来上个难度,让 AI 角色参考复杂武打动作。
过去 AI 角色无法准确还原你设计的复杂动作,不是动作变形就是人物在打斗过程中变了一个人。而现在通过 Vidu Q2 参考生图则解了 AI 创作者的燃眉之急,可以一键复刻动作,让你的 AI 主角也能拥有十八般武艺。
如下面的案例中,两个动漫主角精准还原了图 1 中的打斗姿势,同时人物服装、面部细节、空间位置关系都保持了极高的一致性。

这种对「空间」的理解,让参考生图不再只是贴背景,而是真正具备了为分镜、镜头调度服务的能力。
这种对空间的理解力,用来做电影分镜或者像最近很火的《疯狂动物城 2》那种合影海报,简直不要太好用。

比如下面的案例,同一张图+不同镜头提示词,即可生成足球少年踢球的特写、远景、足球特写等,并通过图生视频,剪辑为一个完整的叙事镜头。对于短剧动漫影视制作,省去了一个画面需要多次拍摄或者绘制大量分镜的环节,妥妥的生产力提效工具。

再通过 Vidu Q2 图生视频功能,输出两人在足球场上抢球的精彩视频:
在风格一致性方面,传统 AI 文生图功能想象力很好但是往往一致性表现很差,风格前后不一致、人物融合的情况屡见不鲜,而 Vidu Q2 不仅支持上百种动漫风格,而且还能在生成的连续多图中保持风格的一致性和故事的连贯性。
比如让 Vidu Q2 文生图几句话生成四格漫画,不仅风格、人物保持前后一致,细节稳定,而且几句话让它一次性拉出完整故事:

从这些案例可以看到,Vidu 在参考生图上的升级,并不是停留在「把图生得像」这一层,而是把「主体一致性」和「空间理解」一起纳入考量:一方面,它能围绕参考图,稳定地生成人物不同角度、不同氛围、不同风格、光线下的一整套画面;另一方面,又能把环境图当成真实空间来处理,而不是简单的背景贴图。
不只是玩具,是实打实的「实战神器」
如果说参考生图解决的是「第一张图怎么定」,那 Vidu Q2 全新上线的图像编辑则真正让这张图进入日常工作流,实现更加精细化的画面控制,满足实际商业化场景需求。
Vidu 在这一块的定位很直接:覆盖 90%的常见图片编辑场景——加元素、减元素、换背景、换颜色、调光线、变焦、比例切换,都可以用自然语言完成,在连续修改的过程中又始终保持主体的一致性。
在替换与局部编辑的测试里,我试着把一张车站广告换成马斯克,要是以前,我得抠图抠到眼瞎,但现在就几秒就能搞定,直接一键复刻。

以后看到爆款广告、爆款封面,可以像这样大批量一键复刻,4K 直出,直接上架,做广告、社媒不要太轻松。
类似的,下面的案例里,要求是为三个女孩加上酒杯——Q2 不仅完成了该要求,还根据光线涉及了酒杯的折射,完善了三个人的手部细节。
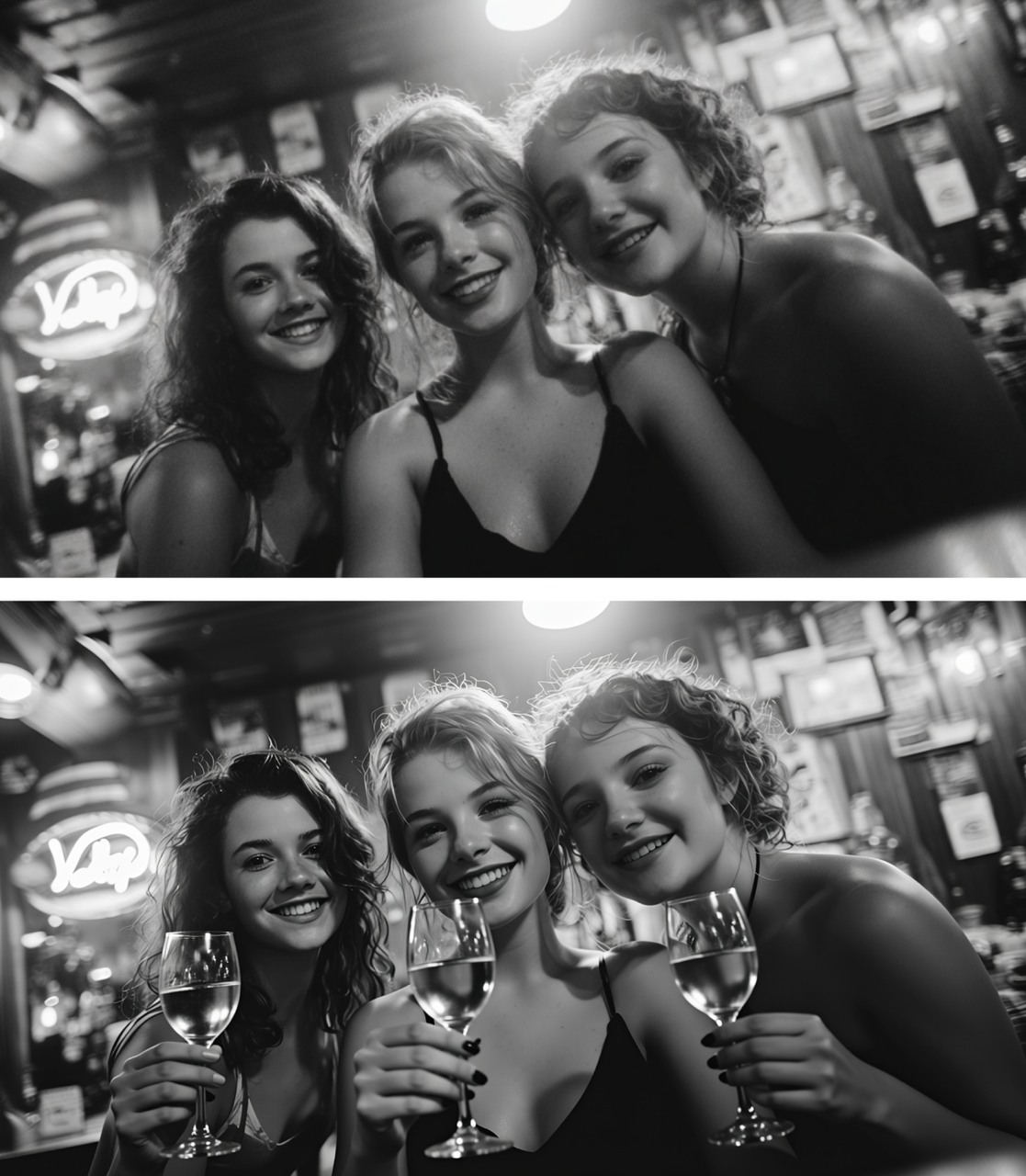
图片编辑是真正的「实战型」能力,尤其是电商或者社媒营销这样的场景。很多产品图的前期其实只有一个简单线稿:设计师给的是草图,运营要的是立刻就能上架的主图。
这就是图片编辑可以大展拳脚的时候,我们用 Vidu 做了一次完整的草图 → 上色 → 材质替换的演练。先是生成了家具的线稿图,然后直接一键用于参考生图,在 prompt 中指定好材料和风格。
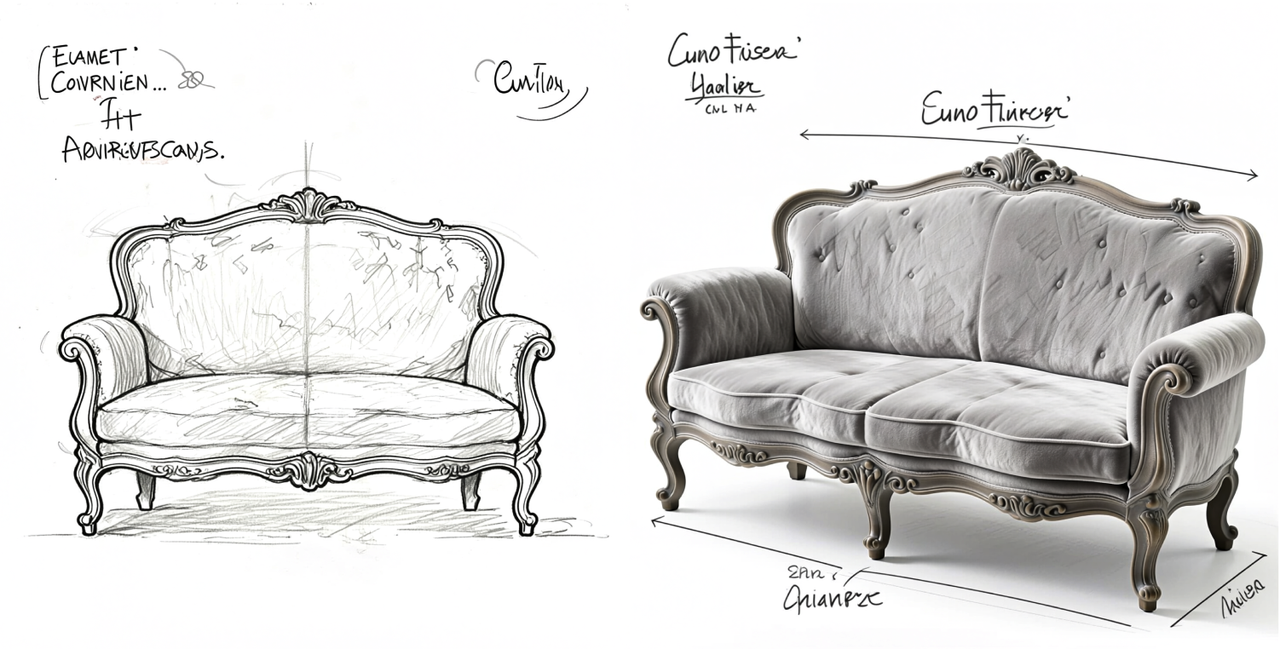
Vidu 通过材质渲染,一步到位,做出细节满满又准确的实物图。紧接着还是一键复用,变换家居风格的提示词,沙发在不同家居风格的实景展示就出来了。

同一商品想要变换材质,也可以轻松实现。

可以发现,Vidu Q2 在图像编辑上的能力,其实正是把「多参生图时代的底层能力」落到了实处:识别谁是画面里的主体,把他/她/它锁定住,然后允许你用大白话对其周围的一切做增删改,甚至跨越多张图和一段视频。
这就好比以前你是开手动挡得调各种参数,现在 Vidu 给你整了个自动驾驶。你只需要把心思花在创意上,剩下的粗活累活,它全包了。
这里面还涉及到另一个非常有用的能力:保存主体。我们可以将上述 Q2 文生图/参考生图/图像编辑后的图片一键保存为主体,把这个 IP「收进了角色库」,后续在 Vidu 的参考生视频中,都可以直接调用主体。
之后无论是换背景、换动作,还是把他/她放进新场景,只要选中这个角色、IP,模型都会严格保持人物一致,不会出现下一秒生成的主角和前一秒不一样的情况。
参考生图——保存主体——参考生视频,Vidu 打通了从灵感到成片的一站式工作流,再也不用在不同平台来回切换了,简直是短剧动漫,广告电商从业者的福音,目前 API 已同步上线。
AI 内卷,别谈「颠覆」,先谈「干活」
对于创作者来说,以前用 AI 干活儿是一种怎么样的体验?大概就是痛并快乐着:上一秒它给了你一张惊为天人的神图,下一秒让你在接下来的十小时里,因为复现不出那个眼神而心态崩盘。
在 AI 创作工具演进的十字路口上,我们观察到了两种不同的产品哲学。
Midjourney 这类产品像一台性能强劲的「引擎」,只有硬核极客才能驾驭那些复杂的参数和咒语般的 prompt,试图把单张图片的审美上限推到极致。
够酷,够极客,但也够折磨人。
而 Vidu Q2 选择了一条更务实、甚至看似「无聊」的路——做一台谁都能开的「量产车」。它不再执着于制造随机的惊喜,而是死磕「稳」字。

这种把所有步骤都帮你封装好的「傻瓜式」链路,才是真正的生产力。毕竟,对于那些被甲方催着改稿、被运营催着上线的团队来说,比起灵机一动的「随机性」,更加需要可交付的「确定性」。
也许在某些极端艺术风格的探索上,它或许不如那些参数党工具来得狂野自由,甚至因为太追求稳定,少了一些「意外之喜」的灵气。
但对于那些对于深受「抽卡」折磨的创作者,Vidu Q2 提供了一种久违的安全感。
当行业在谈论 AGI 的宏大叙事时,Vidu 低下头,不再只是给你造虚无缥缈的梦,先帮你把手里的砖搬稳了。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博



































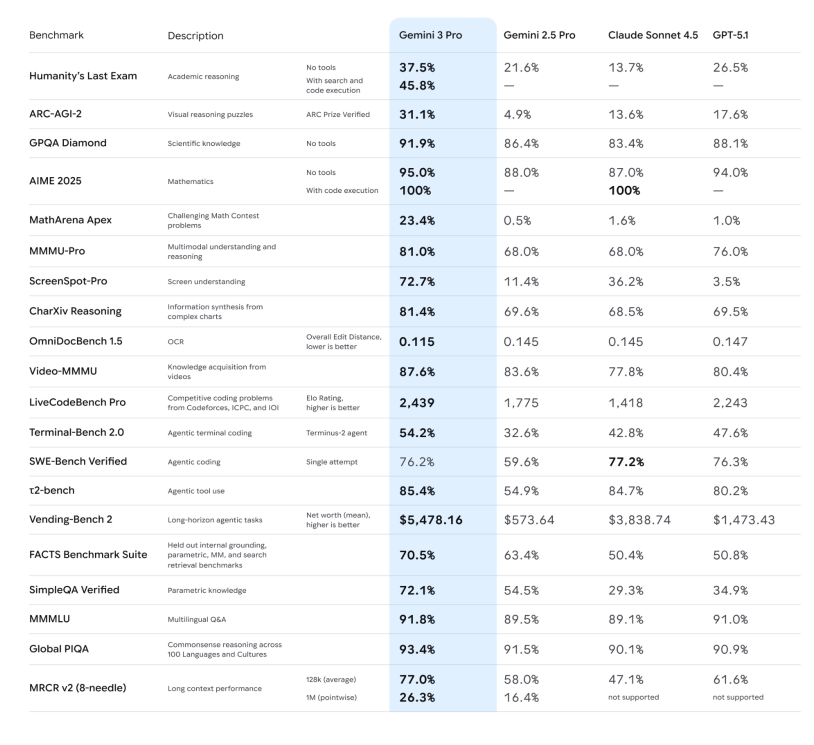 -推理能力:官方强调 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高难度推理和数学基准上,全部刷出了新高分,定位就是「博士级推理模型」。
-推理能力:官方强调 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高难度推理和数学基准上,全部刷出了新高分,定位就是「博士级推理模型」。