之前测试了 Midjourney V6 在石膏、大理石、黄金材质 下的表现,出品非常好,并且品质表现很稳定。今天忽然想测试一下,同样的题材在不锈钢材质下的表现如何。
因为上述三种材质的漫反射对形态的干扰很小,AI 的训练素材应该也大部分是以这类非镜面材质的图库为主,所以我猜测,同样的雕像在抛光/镜面不锈钢下的表现,很可能会因为镜面反射对形态的干扰,产生许多错误。
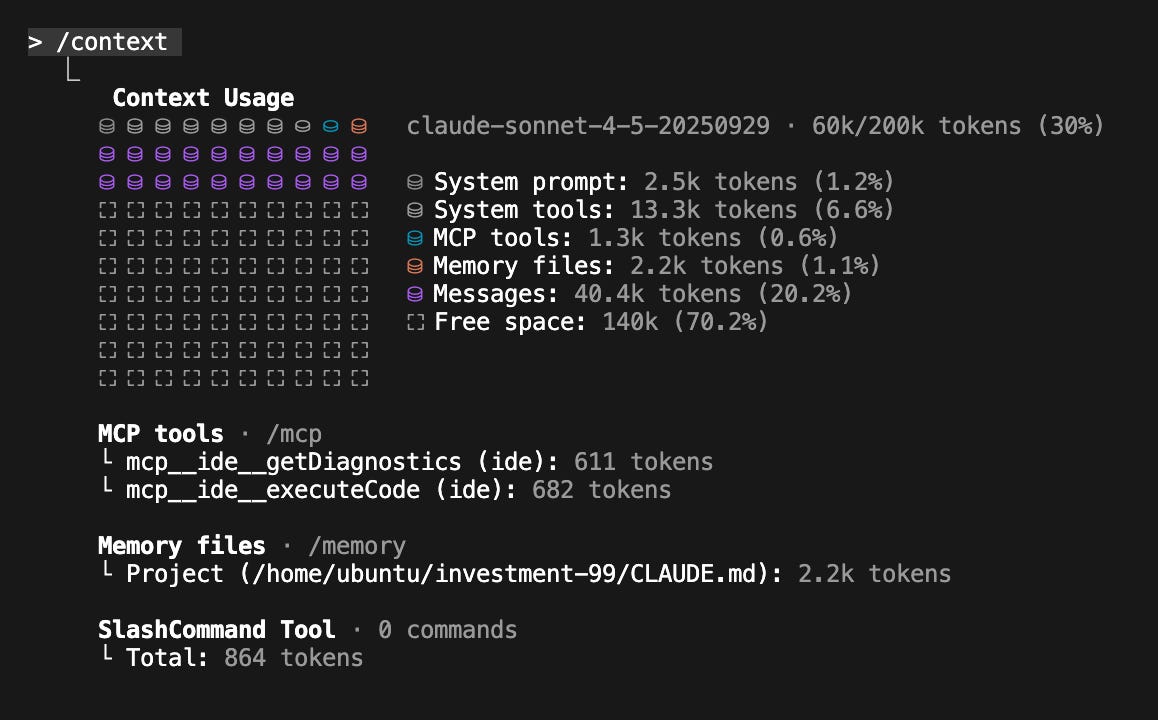
以下实测例图,均可点击查看 原始尺寸高清大图 。
Prompt
可以看到,镜面不锈钢材质在没有手部参与的情况下,表现非常出色。形态、比例与动态都在镜面材质下,显得更为出色,细节的呈现也非常舒服。
Prompt
这一组我着实测试了很多轮,才终于能挑选出这两张还看得过去的成品。期间最容易出现问题的点有:
1、手的比例和手指的形态、数量;
2、画面未完整呈现 prompt 所制定的内容;
3、不锈钢、羽毛、岩浆、火焰四种材质的不恰当混合。
我感觉目前的
V6 Alpha 虽然在光影关系和质感的表达上非常强,但在较复杂的 prompt 的情况下,非常容易出现不合适的混合。
Prompt
这一组实例中,明显可以看到
MJ 对于 Mirrored Stainless Steel 这个关键词的错误执行。虽然质感的表现非常好,但它根本不是镜面不锈钢。同时,岩浆、黑曜石这些关键词也几乎没有呈现,仅有部份反光似乎呈现出了对「Lava」一词的反馈。从最终结果来看,质感的表达是明显跑题了。
Prompt
当我把其中「白色羽毛」的描述,修改成「红色羽毛」后,可见材质之间的干扰就几乎消失了。大概是镜面材质中高光的部份容易和白色材质产生混淆,所以在颜色明显有区分的描述下,不锈钢的质感表达就非常舒服了。
这一点猜测,在最后一组失误实例中,可见到更离谱的跑题。
Prompt
这一组和上上组的 prompt 是完全一样的,区别有:
1、选择方案发散路径时,选择了有躯体的版本,有起伏的形态更有利于表达镜面材质;
2、更大面积的曲面形态,似乎会有更少的概率出现材质跑题的情况。
我不确定以上猜测的概率,但在实际测试中的感受就是:
如果人物以全身、半身的形态来呈现,那么镜面不锈钢的表达错误非常少见;但如果选择只有脸部特写的方案深入,材质跑偏的概率明显更大。
Prompt
同时,因为以上的所有测试中,手的比例和手指的形态、数量一直都在出问题,所以我单独对「手」做了几轮测试。在高反射材质描述下,「手」出问题的概率非常非常大。必须一轮一轮地精挑细选,在看着还行的方案上一次次地 Vary 才能偶遇到一两个,看着没什么大毛病的「手」。
同时,因为高反射的干扰,高光和白色很容易让不锈钢材质呈现出磨砂质感。
Prompt
这就是上文说到的跑题千里的材质表达。
同是 Polished stainless steel 这个词,但无论是躯体还是面部,都完全没有 Polish 的意思。整体观感更像是光滑的石头,它的质感表达完全被白色羽毛给搞混了。但同时,羽毛也呈现出石雕的质感,完全不是羽毛的质感,和上面几组实例的羽毛完全不是一类表现。
本轮测试总计生成了 659 份方案,筛选出以上 19 张我认为可以的成品图。
在我看来,这个比例过于低了。
希望在
V6 的正式版本中,能优化这方面算法。






 Bust photo, polished stainless steel goddess sculpture, real feathered wings, black rock, magma and flame, dark clouds –ar 3:4 –style raw –v 6
Bust photo, polished stainless steel goddess sculpture, real feathered wings, black rock, magma and flame, dark clouds –ar 3:4 –style raw –v 6















