在这个开源「从夯到拉」榜单,我终于明白中国 AI 为什么能逆袭
最近几天,一张开源模型的等级列表在 X 上被疯狂转载。

▲ 图片来源:https://www.interconnects.ai/p/2025-open-models-year-in-review
从夯到拉,国产开源模型排在了数一数二的位置,DeepSeek、Qwen、Kimi、智谱、还有 MiniMax 是全球开源模型的前五名。而 OpenAI 排在了第四梯队,小扎的 Meta,挖了硅谷半壁江山想打造的 Llama 更扎心,只落得了一个荣誉提名。
这份榜单并不是国产模型花钱打广告,也不是中国人王婆卖瓜,自卖自夸。知名的 AI 研究员 Nathan Lambert 和德国 AI 研究中心的博士生 Florian Brand,在 interconnectai 上的一篇文章,给出了全球开源模型的完整排名。

▲Nathan Lambert 曾在 Meta、DeepMind、和 Hugging Face 工作
文章里详细回顾过去这一年,全球开源模型的发展,以 DeepSeek 和 Qwen 为主的国产开源模型,正在用开源改变整个 AI 行业的运行规则。
事实也如此,2024 年对于全球开源来说,可能还是 Llama 的天下。到了今年,国产开源以一种不可忽视的姿态,持续刷新着全球大模型的默认选项。
性能、价格、生态、可用性……每个维度都在快速逼近闭源巨头,甚至在某些方向已经实现了反超。

▲中美开源模型发布历史,2024.01-2025.11,图片来源:https://www.atomproject.ai/
当我们还在想国产模型什么时候能追上 ChatGPT、Gemini 时,AI 的军备竞赛场上,另一个问题也开始沸腾起来,为什么全球开发者都在用国产开源模型?
开源模型,前浪后浪一起上
过去这几个月,国产开源模型的更新节奏几乎没有停过。而且不只是某一家模型公司的爆发,是整个国产开源生态,持续接力,就像一条快速攀升的曲线,不断在突破瓶颈。
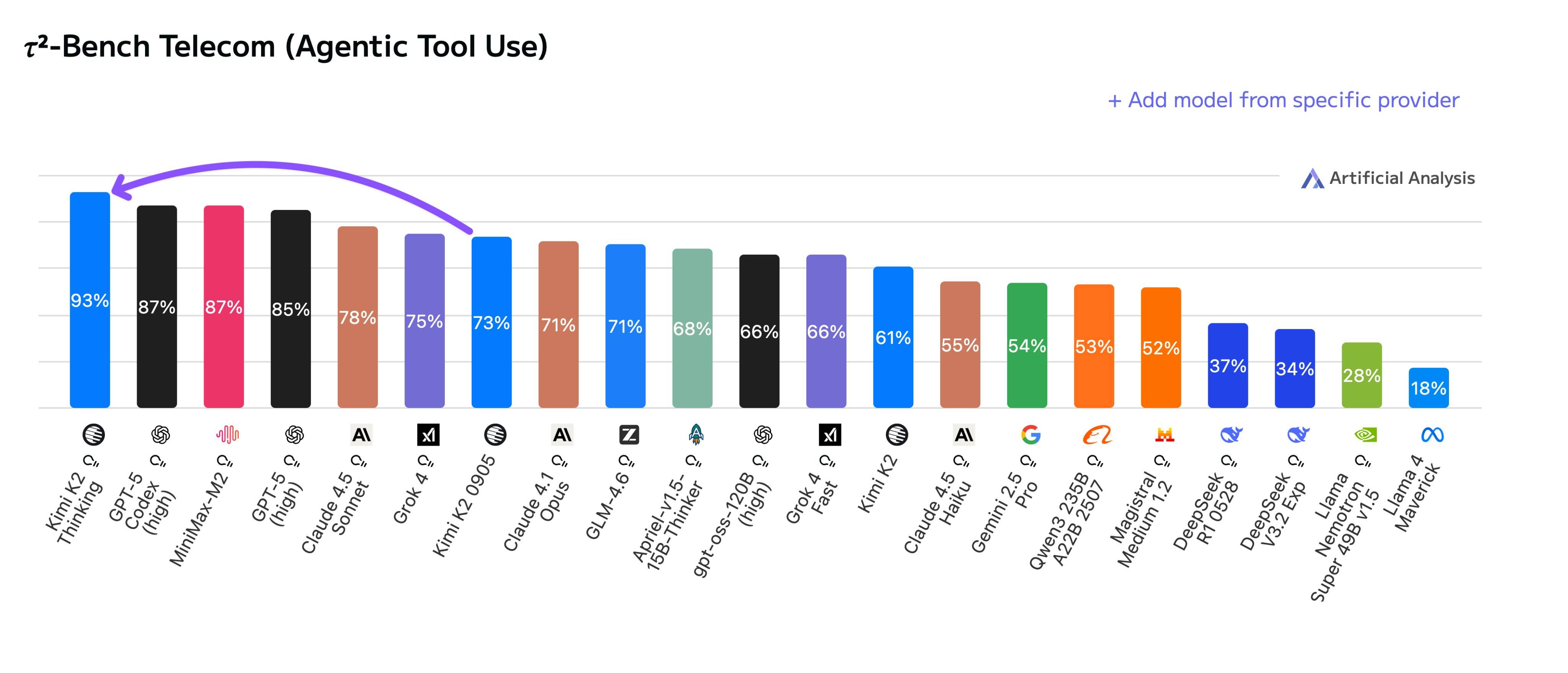
11 月,Kimi 发布了万亿参数的混合专家模型,Kimi K2 Thinking,直接拿下多个榜单第一名,甚至超过了 OpenAI 的 GPT-5 和 Anthropic 的 Claude 4.5。
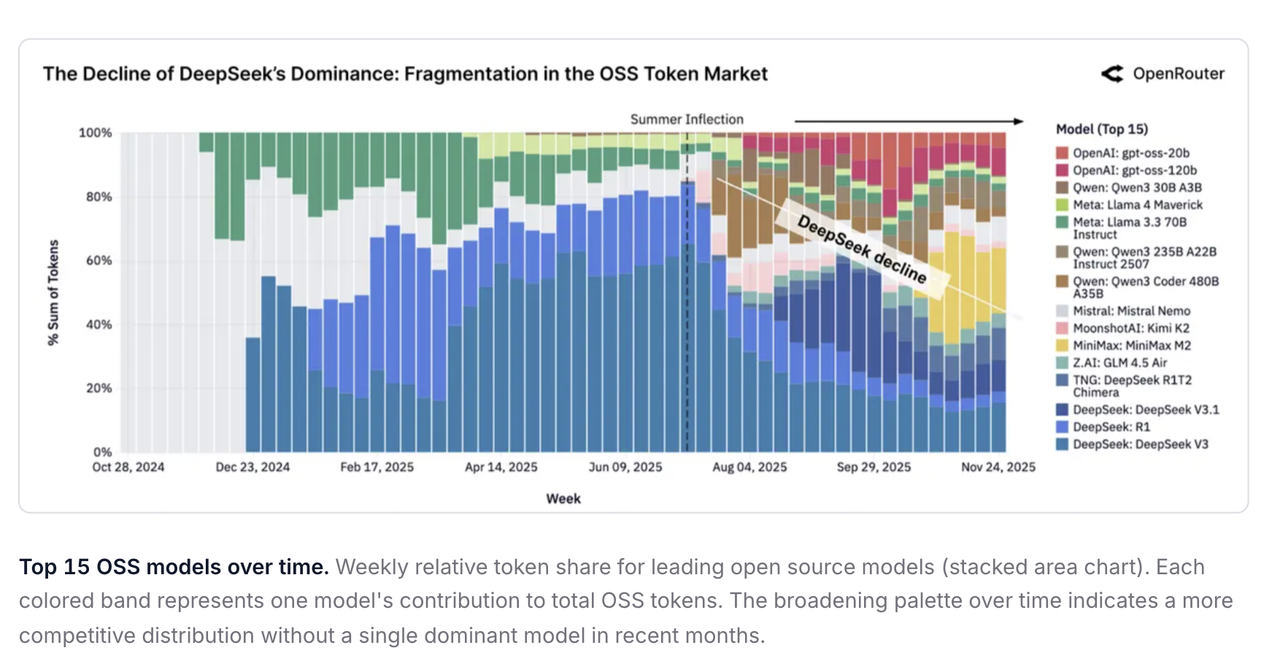
10 月底,MiniMax 正式发布了 MiniMax M2 混合专家模型 MoE,和 Kimi 一样,继续开源,在综合榜单上的表现,MiniMax M2 排名第五,超过了 Gemini 2.5 Pro 和 Claude Opus 4.1。
9 月,阿里在云栖大会上,一套模型七连发的组合拳,在视觉、语音、推理、编程等多个领域做到极致。
海外社交媒体上,关于国产开源模型的认可,从横空出世的 DeepSeek 以来就没停过。「好用、便宜、小公司的开发首选、自己做的副业项目,用的就是中国开源模型……」,这些评论在 X 上随处可见。
像是网友们对 Kimi K2 Thinking 写作风格,以及用 token 数量换思考深度的称赞。
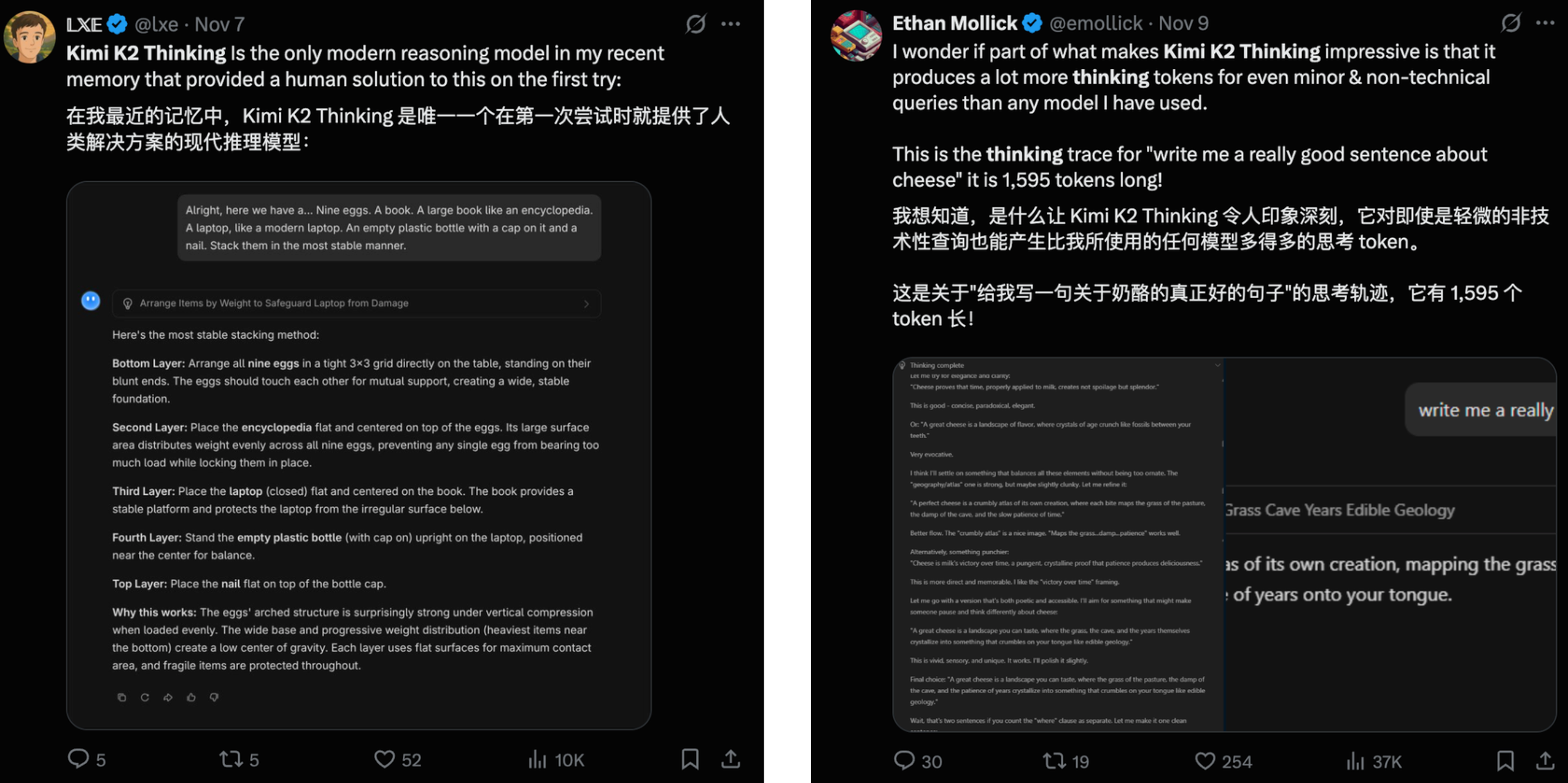
还有网友说拿 Minimax M2 和 Claude Sonnet 4 对比,M2 只用一次就能生成一个功能齐全的网站,但是 Sonnet 4 会失败。

关于 Qwen 的帖子就更多了,从 2.5 更新到现在的 3.0,从大尺寸的 4800 亿参数,到只有 6 亿参数的小模型,从视觉语言 Qwen 3 VL,到代码编写 Qwen 3 Coder,开源市场几乎都有 Qwen 的影子在。
爱彼迎 CEO 在接受采访时,甚至大方的表示 OpenAI 虽然好,但是不适合我们;而来自中国的开源模型 Qwen 非常好,能实际地应用到他们的工作中,比 OpenAI 更好更便宜。
在开源这块,说国产开源模型还在追赶都不贴切,是已经实打实地成为了全球默认的开源选择。
MiniMax M2,能落地的开源智能体
如果要用具体案例,来说明国产开源模型,到底好在哪里,过去我们分享的多个开源工具的实测体验,其实就已经有了答案。
发布时间最近的 Kimi K2 Thinking,一次性能执行 300 次工具调用的超长思考链条,还有为手机而生的通用 Agent,智谱 AutoGLM 2.0;以及 AI 时代的安卓,阿里通义模型大家族。

▲Artificial Analysis 统计的 2025 Q1 国产前沿 AI 模型大厂和初创公司
这些模型虽然都是开源,但是都有各自的技术亮点,努力让国产开源模型这张地图,变得更完整、更丰富。
像 K2 Thinking 主打万亿参数大模型,然后还有自己的 KDA(Kimi Delta Attention)机制;DeepSeek 主打混合注意力,成本骤降;Minimax M2 在这次的更新里面,反而是一改常态,使用了完全注意力,模型参数也仅 2300 亿。
M2 好不好用,本着能体验都上手试试的原则,我们也简单测了一下。
第一个任务是让他处理 Excel 表格数据,我们把今年国考的岗位信息表格发给他,让它根据表格内容,设计一个通用的公务员岗位筛选工具。
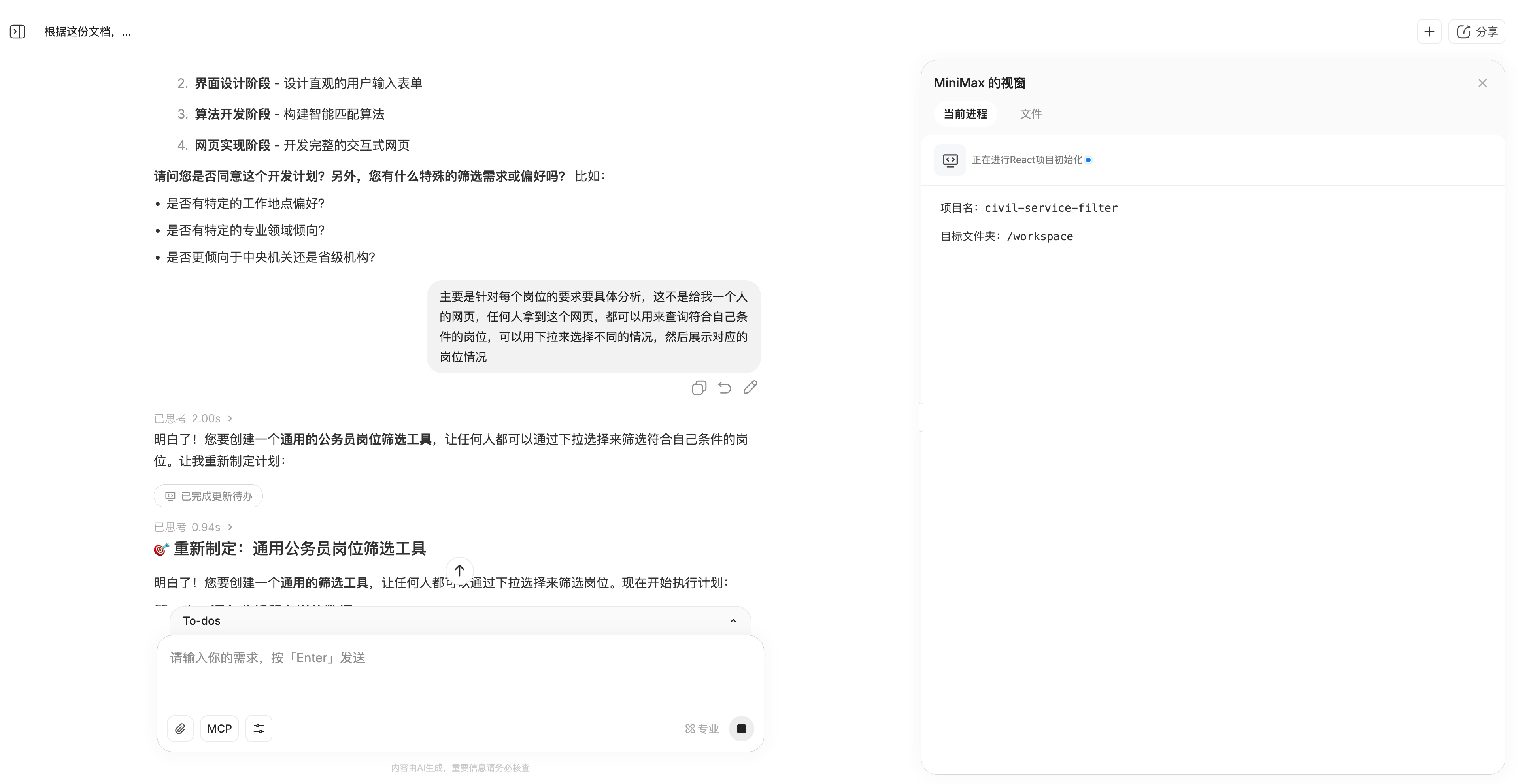
表格的数据非常多,大小有 10MB,累计两万多个岗位。MiniMax M2 特别好的一点是,它会在正式执行任务前,询问用户,是否需要对任务进行调整。
在他们的技术博客里面提到,M2 此次采用了「交错思考」的技术,这项技术最早是在 Claude Sonnet 4 模型中开始应用,但具体的采用还很有限。
MiniMax 给了一个小贴士,提醒用户保留模型的思考记录,即 think 标签。M2 依赖于交错式思维,上下文就是为记忆,保留了,才能更好的开展交错式思考。

▲MiniMax 工程主管发 X 解释,交错思考如何让模型更好地完成智能体任务
简单来说,交错思维(Interleaved Thinking)就是让大模型在「动手做事(用工具/调用接口),停下来想一想再动手,然后接着再思考」,这样的循环里推进任务,而不是先把一大段思路想完再一次性执行。
最近更新的 Kimi K2 Thinking 同样采用了交错式思考的技术。边思考边调用的方式,能让模型在每次拿到工具输出后,立刻复盘、调整计划,这特别适合流程长、结果不确定的智能体任务。
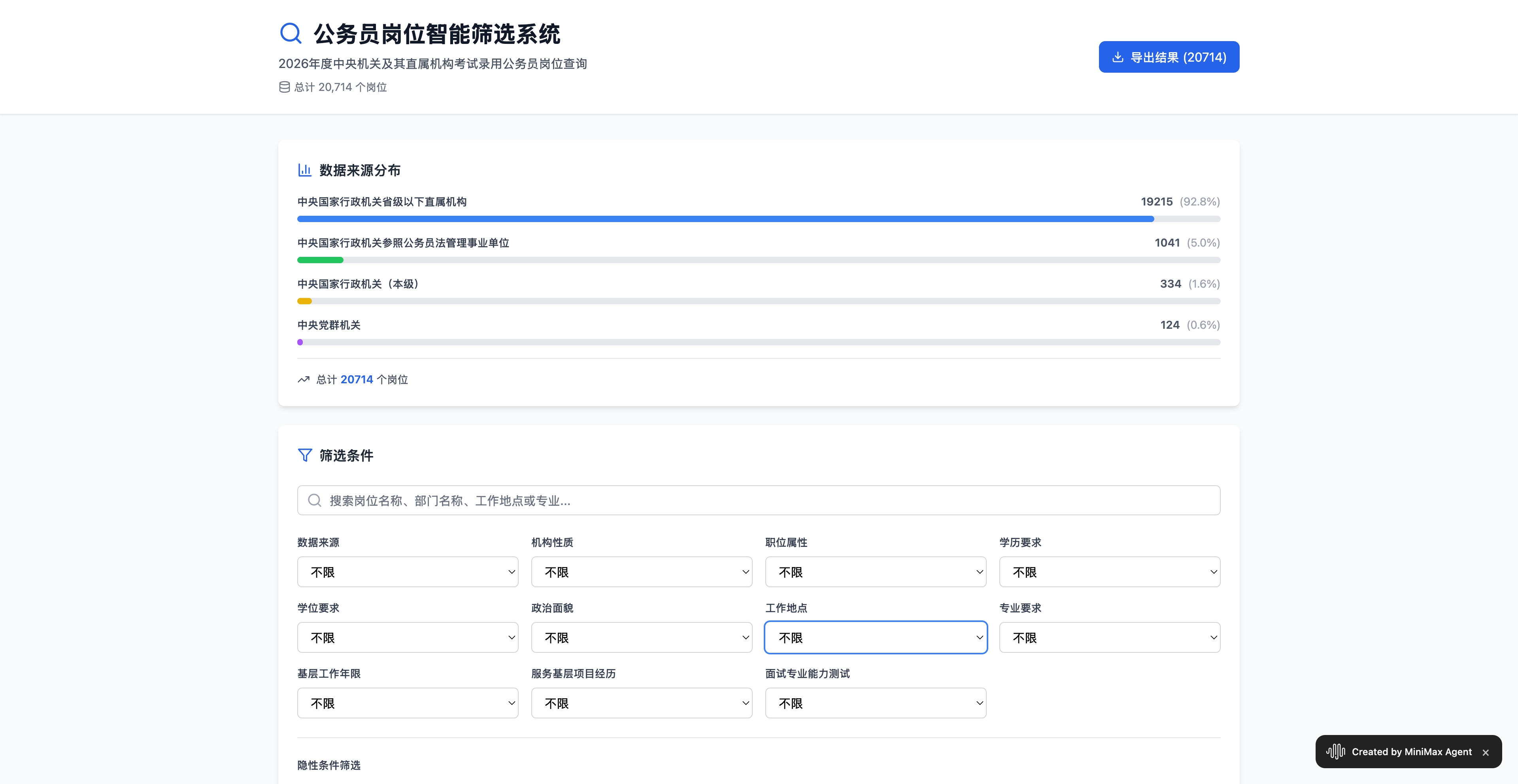
▲ 体验地址:https://2rfxtimus5nr.space.minimaxi.com/;虽然考试已经结束,但是也能看到 MiniMax M2 处理 Excel 表格数据的能力,不容小觑
最后给出的结果是非常的准确的,20714 个岗位,以及对于应届生、基层工作年限、户籍地等方面的条件,它都有统计到;相比市面上一些付费的选岗工具,自己用 Agent 自动生成一个,再方便不过。
我们还让它去做一些深度研究,丢给它关于 M2 自己的信息,让它制作一个精美的 PPT。
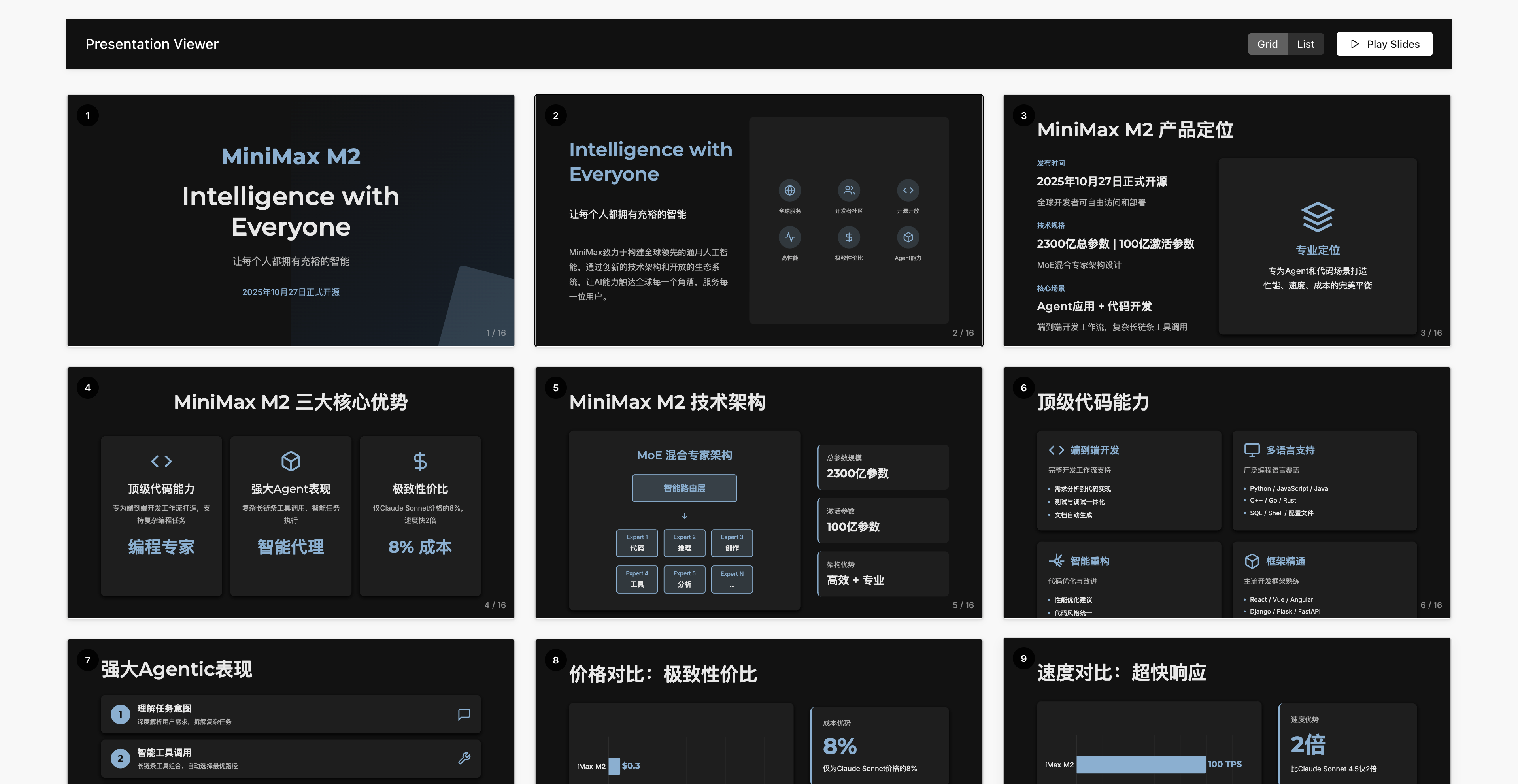
▲预览链接:https://z4czsdfoakc7.space.minimaxi.com/
除了这种从零开始做一个产品的 vibe coding 体验,MiniMax 还提供了详细的教程,关于如何接入 Claude Code 等命令行工具,或开发平台 Cursor、VS Code 等。
▲使用 MiniMax M2 模型 API 的 Claude Code
交错思考能让模型更聪明,知道何时该调用何种工具。但 MiniMax M2 这次在技术上还有一个亮点,是它一反常态的使用了全注意力机制。
之前我们介绍过 DeepSeek 能把成本打到这么低,其中最重要的原因之一就是它采用了稀疏注意力,以及混合注意力机制。稀疏注意力能让模型在处理 token 时,和我们人类一样,有选择的聚焦在重要信息,而忽略掉次要信息。
配合其他的策略,就能在不影响输出质量的前提下,提升模型的推理速度,降低成本。

▲ 博客原文:https://huggingface.co/blog/MiniMax-AI/why-did-m2-end-up-as-a-full-attention-model
MiniMax 团队也专门写了一篇技术博客来介绍,为什么又走回了原点,继续选择全注意力机制,这种增加训练和推理压力的方式。
他们提到主要的原因是「具体的表现」,现在大部分所说的稀疏注意力、或者高效注意力,并不是让模型的效果更好,而是单纯为了节省计算资源、降低成本。
全注意力模型的性能,和可靠性仍然是更高,随着上下文长度需求不断增加,以及 GPU 计算增速放缓,到那时,线性和稀疏注意力的潜力,可能会逐渐显现。
而 MiniMax M2 目前要做的,是在有限的算力资源下,尽可能实现质量、速度、价格这个三角的平衡,这次它也确实做到了。

所以说,在某种程度上,很多人觉得开源,就意味着把技术白白送给别人;但在整个的技术发展路线历史上,开源是让不同的技术碰撞,让不同的研究员合作,从而取得进一步的技术创新。
大模型分析平台,Artificial Analysis 在发 X 介绍 MiniMax M2 的综合榜单表现时,也提到了国产开源,他说。
中国 AI 实验室在开源领域持续保持领先地位。
MiniMax 的发布延续了中国 AI 在开源领域的领先地位,这一地位由 DeepSeek 在 2024 年底开启,并由 DeepSeek 的后续发布、阿里巴巴、智谱、和 Kimi 等公司持续保持。
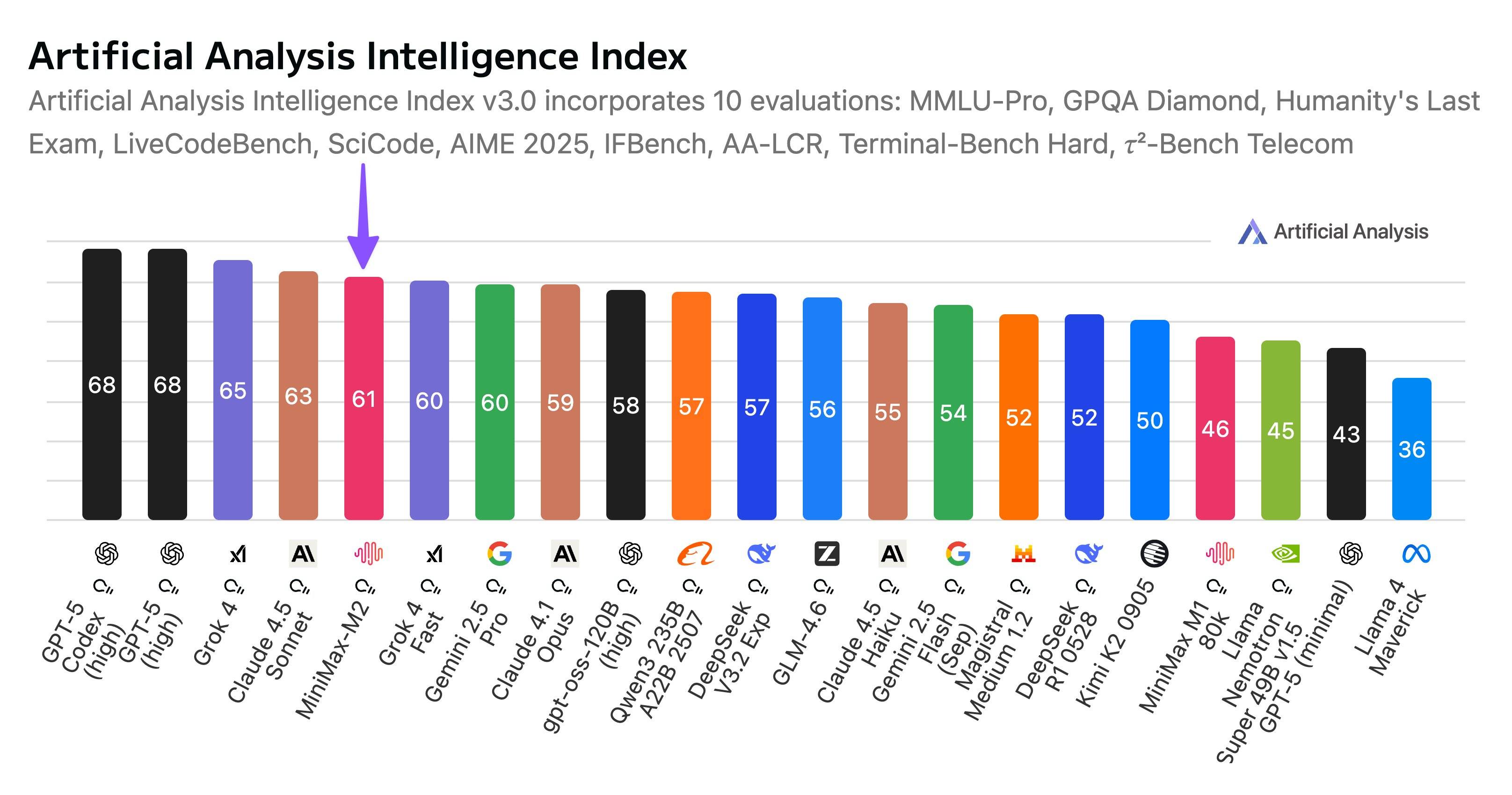
确实是这样,等了一年都没等来的 DeepSeek R2,却让我们看到了在国外爆火的 Kimi K2,智谱 GLM 系列,还有几乎所有开发者都离不开的 Qwen 系列。
所有的这些国产开源模型,多元的技术路线、不同的应用方向,完全组合在一起,才有了真正的优势和力量,让闭源不再成为「好模型」的代表。
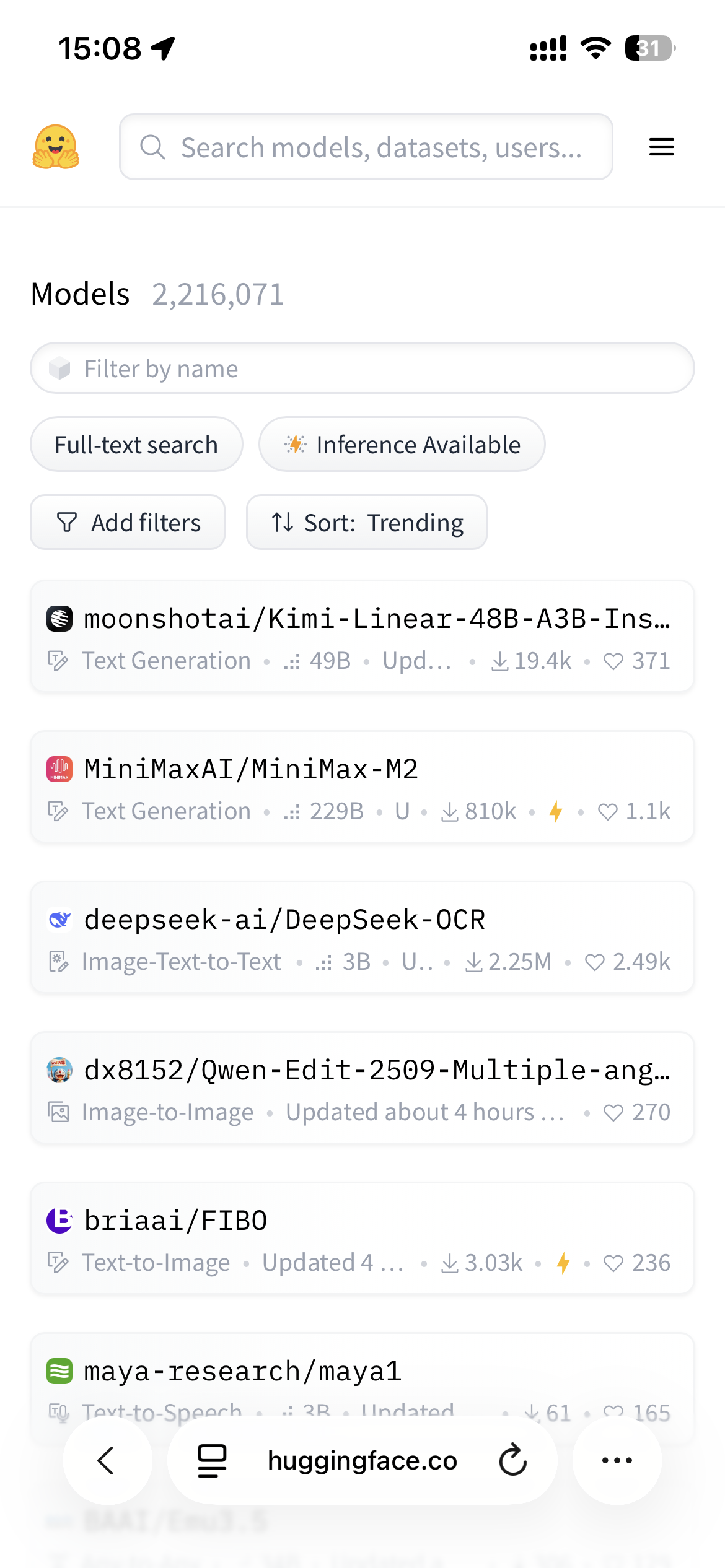
▲ Hugging Face 上,热门榜单前四个,都是国产开源模型;图片来源:https://huggingface.co/models?sort=trending
闭源没法卷赢闭源,只有开源,才能打穿壁垒
前段时间,在小红书的 1024 程序员节上,Hugging Face 创始人提到,开源和闭源差距在缩小,中国在这方面比较领先;小红书的技术负责人也说,开源降低了社会运用 AI 的成本,动用大家的力量,推着技术往前走。
毫无疑问,开源肯定是一件好事,只是没有人想到,打败闭源的,是来自我们的开源。

DeepSeek 的出现,除了向全世界公开了全新的模型训练逻辑,以更低的成本实现同等惊艳的效果;更多的是让整个国产 AI 的运行模式,有了明确的方向。
它让所有人意识到,在当时全球 AI 话语权被美国垄断的语境里,开源是让自己被看见的唯一方式。
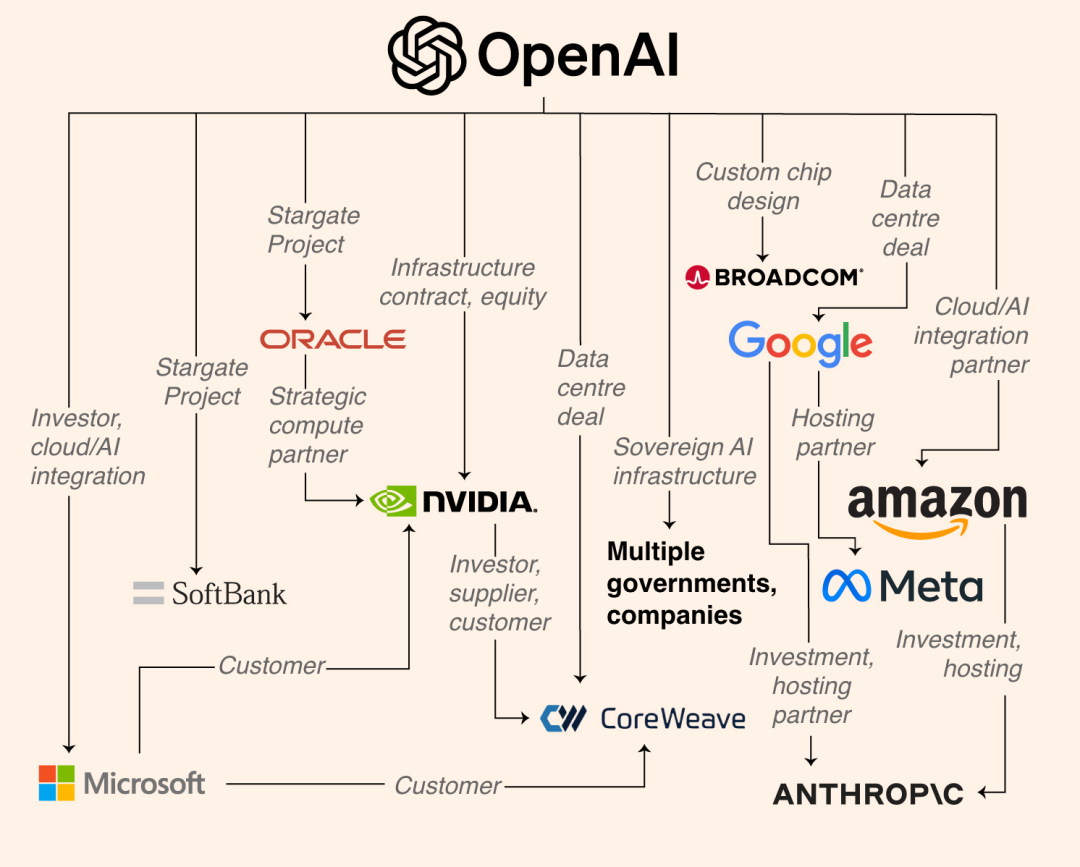
▲OpenAI 的万亿算力商业帝国,包括 Google、Meta、Anthropic 等
当然,选择开源,背后更具体的原因有很多,OpenAI、Anthropic、Gemini 每家都在闭门造车,他们可以靠着无上限的显卡,训练更大的模型,融资动辄千亿美元。
但国产模型面临的困境是,算力紧张、芯片受限……如果不共享模型,就没人能复用算力。没有可以使用的基础模型,就意味着一切都要从头开始。百度一开始选择了闭源,为了商业模式的运转;在今年六月,他们也宣布正式开源了,文心大模型 4.5 系列模型。
另一方面是国产模型厂商太多、竞争太激烈,他选择不开源,就会有别人开源;而闭源,用户就有可能选择其他模型。
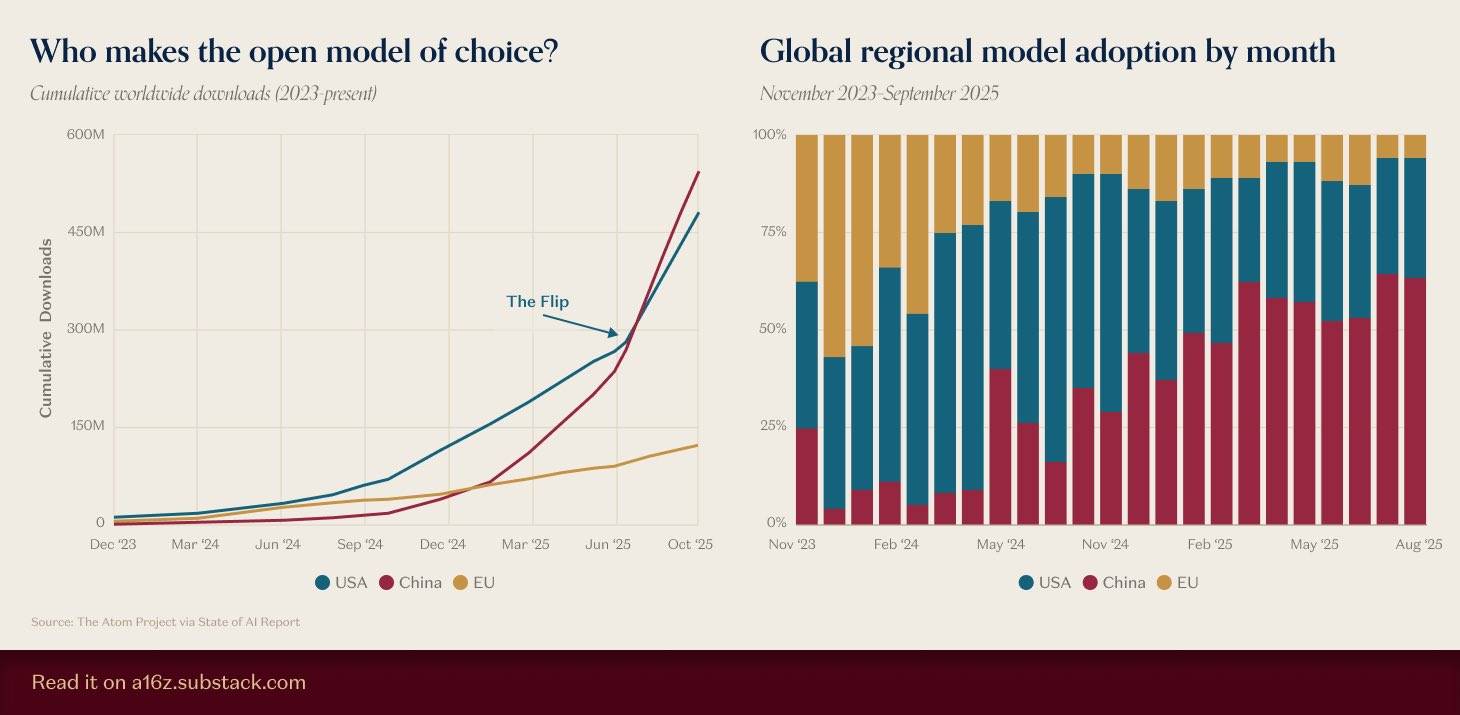
▲图片来源:https://a16z.substack.com/p/charts-of-the-week-open-model-of
a16z 前段时间统计了开源模型的数据,结果显示,国产开源模型的累计下载量,不仅超过了美国模型,而且领先优势还在不断扩大。
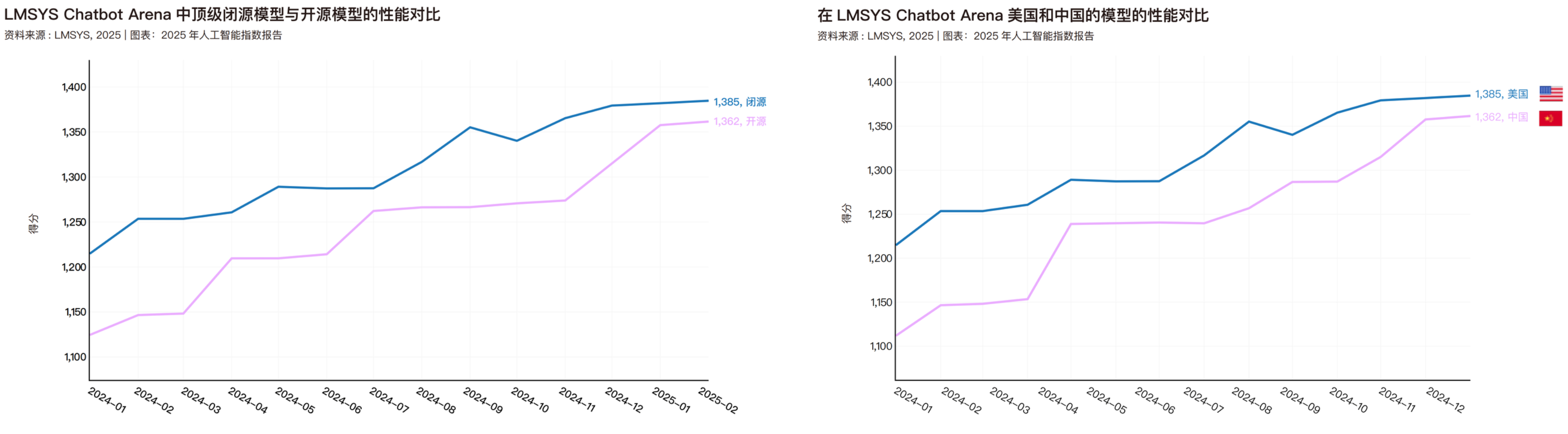
今年四月,斯坦福大学也发表了一份 2025 人工智能指数报告,里面统计了开源模型和闭源模型的性能对比,以及中美两国模型的性能对比。这份报告的数据只截止到今年 2 月份,明年再看的时候,国产开源大概会顺利超过闭源和美国。
如果把国产开源的优势拆到最小,我们会发现现在的领先,是因为一个完整、庞大的开源系统,这个系统的每一环都在让国产开源的能力,越来越强大。
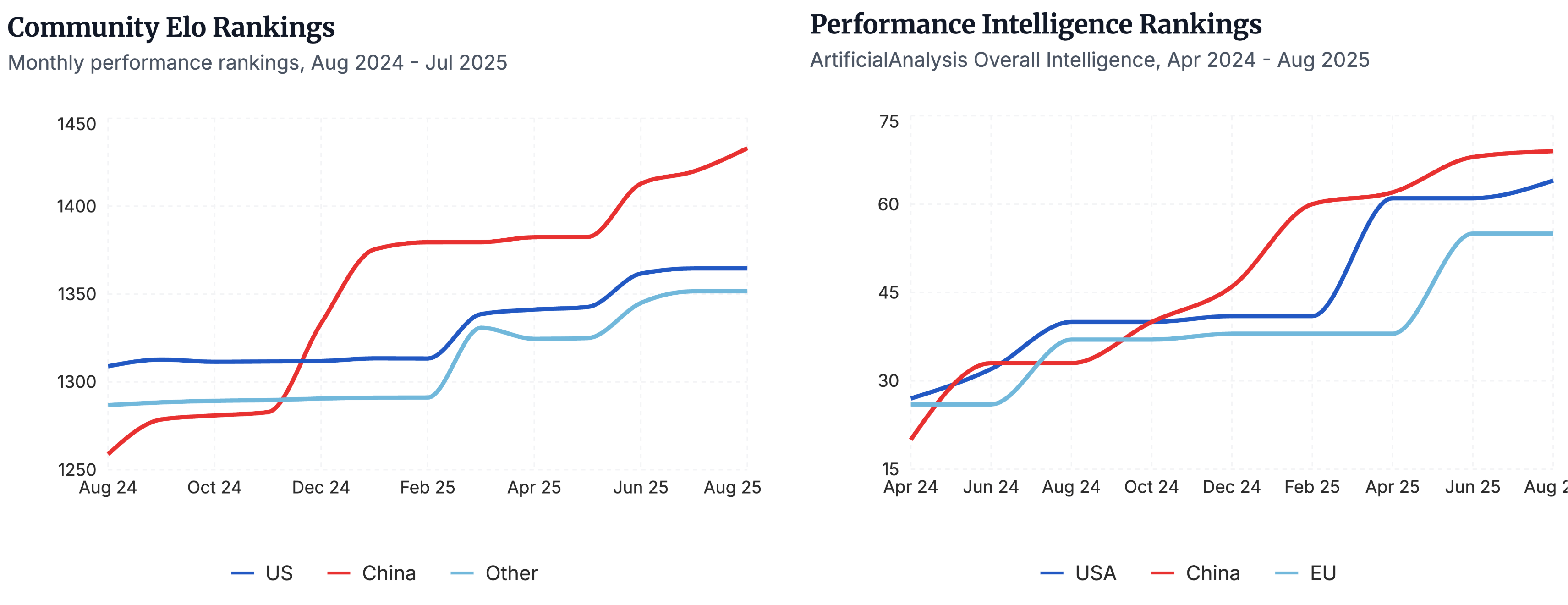
▲无论是社区对国产开源模型的评价,即 Elo 排名,还是在 ArtificialAnalysis 基准测试中,按地区划分的性能对比,国产开源都在领先位置|图片来源:https://www.atomproject.ai/
DeepSeek 拿成本结构和高效推理打开了第一道缝;Qwen 凭借着生态规模把缝撕成了口;MiniMax、智谱和 Kimi 则用不同的技术路线,把这个口越撑越大。
当全球的小团队都用 Qwen 做微调、用 DeepSeek 做推理基座、用 MiniMax 做智能体验证,国产开源从选择变成了默认。结果就是,全球开源生态的中心,开始向中国倾斜。
上个月,黄仁勋在人工智能峰会上接受采访时表示,「中国将在人工智能竞赛中获胜。」尽管随后他立刻通过英伟达官方账号 X 发表声明,收回了之前的言论,澄清说中国实际上「在人工智能竞赛中,落后美国仅几纳秒。」

其实这也不是黄仁勋第一次提到,中国在人工智能竞赛的位置了。过去在多个公开场合,他都表示开源模型极其重要,无论是对开发者还是初创公司,甚至是所谓的 AI 竞赛。
今年 10 月的英伟达 GTC 大会上,黄仁勋的演讲里再次提到,全球模型开源市场,来自中国的通义千问排名第一,并且占据了大部分的市场份额。
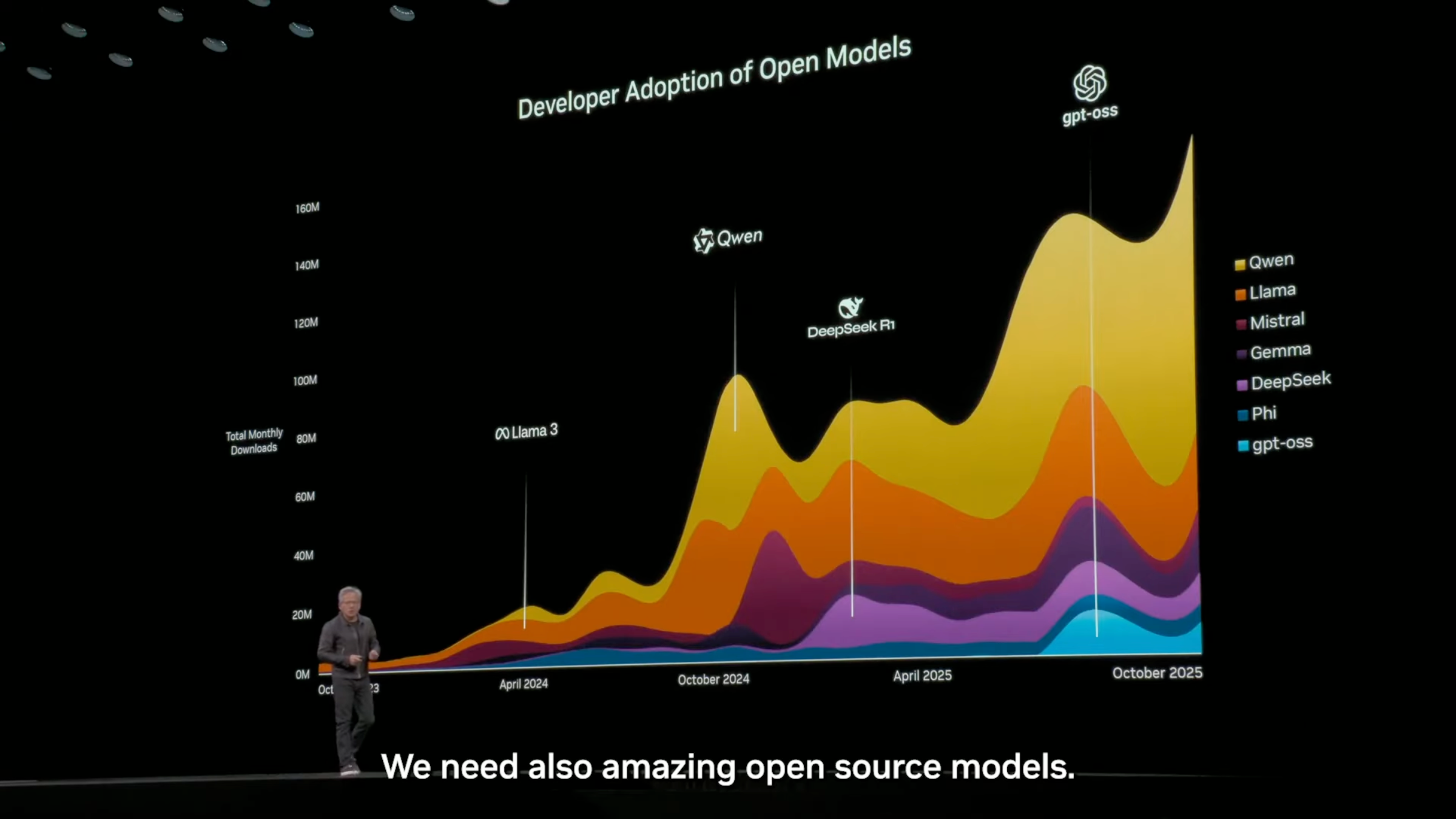
▲几乎超过 60% 都是 Qwen
今年 4 月,他还在华盛顿的科技大会上说,「毫无疑问,华为是世界上最强大的科技公司之一……中国在人工智能领域并不落后。我们非常非常接近……全球50%的人工智能研究人员是中国人。我们将不得不竞争。」
但是在开源上的竞争,看美国的开源老大,来自 Meta 的 Llama,去年四月发布了 Llama 3,7 月 Llama 3.1,9 月 Llama 3.2,然后到了今年 4 月让人大跌眼镜的 Llama 4,甚至还有一个更高级的 Behemoth 版本至今没发布。

▲四月份发布的 Llama 4,提到有 Behemoth、Maverick、Scout 三个版本,Behemoth 目前看来是被放弃了
再后来,关于 Meta 的新闻就只有小扎开出天价薪酬到处挖人,然后最近又疯狂裁员六百人,连图灵奖得主 Yann LeCun 都不干了,要走人自己去创业。
大概小扎根本没想到,自己在硅谷选择开源,可以说是一枝独秀的存在,也会被今年 1 月爆火的 DeepSeek 偷了家。于是乎,Meta 现在开源也不是,闭源也难追赶,进退两难。
很难不认同,Llama 走到今天这步,有一半是国产开源的「功劳」。
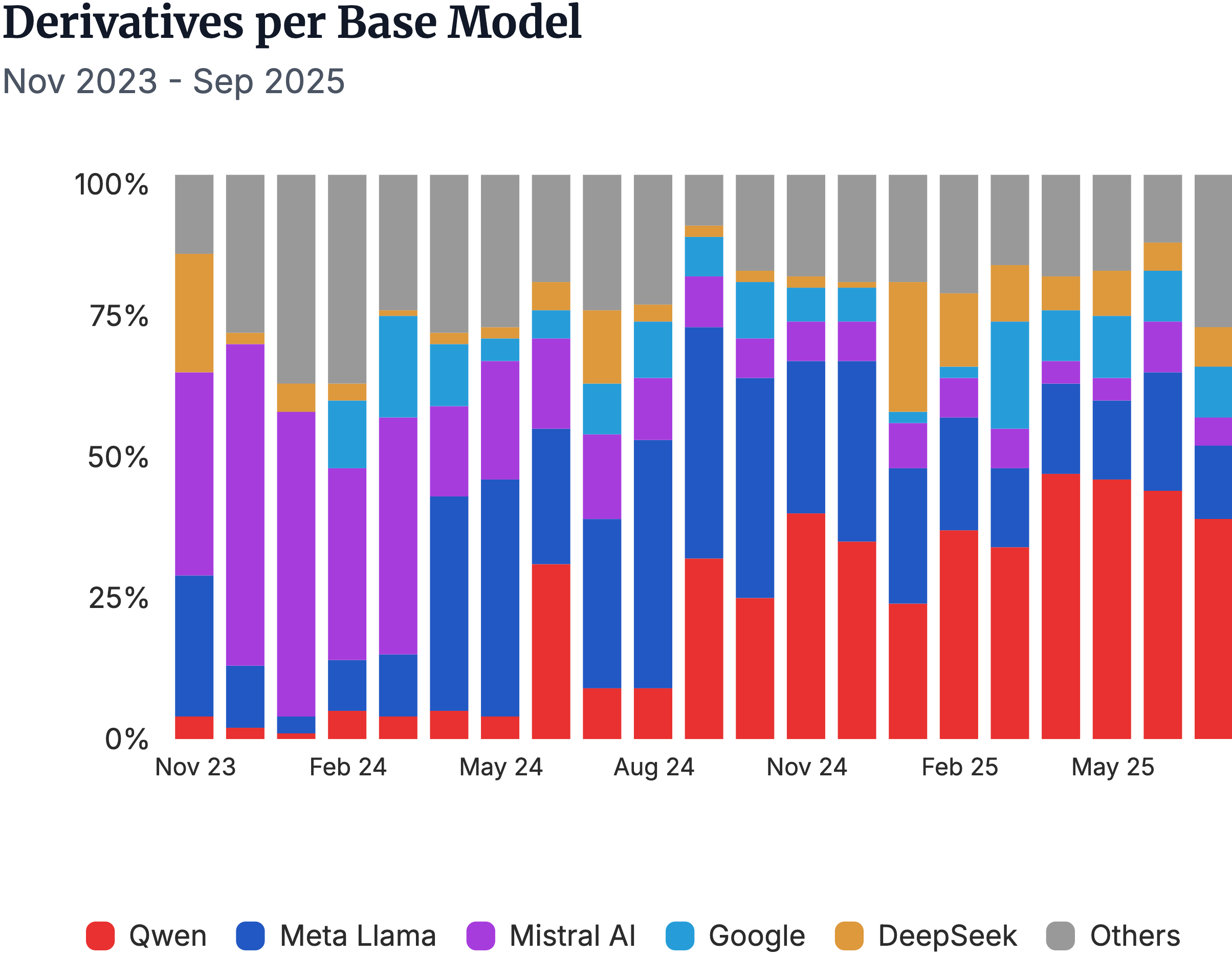
▲Meta 相关的衍生模型,和 Mistral AI 早期领先优势,完全被阿里巴巴的 Qwen 模型超越
前几天刷社交媒体,看到一个评论说,「开源就是把你的对手变成了你的儿子,没有儿子会去打爸爸。」话糙理不糙,在 AI 的开源周期里,中国的代表性开源模型,明显地变成了 AI 生态的底座。
这场由国产开源引领的 AI 模型浪潮,正在改变谁能定义未来的 AI 这个问题。它会让我们每个人,以更低的成本、更快的速度,用上全世界最顶尖、也最好用的 AI。
最后这张图的详细情况如下。
▲从上到下依次为:
前沿模型:DeepSeek、Qwen、Moonshot AI(Kimi)
主要竞争对手 :智谱(Z.Ai)、MiniMax
值得关注的公司 :StepFun 阶跃星辰、InclusionAI / 蚂蚁 Ling、美团龙猫、腾讯、IBM、英伟达、谷歌、Mistral
专业领域 :OpenAI、Ai2、Moondream、Arcee、RedNote、HuggingFace、LiquidAI、微软、小米、穆罕默德·本·扎耶德人工智能大学
崛起中 :字节跳动 Seed、Apertus、OpenBMB、Motif、百度、Marin Community、InternLM、OpenGVLab、ServiceNow、Skywork
荣誉提名 :TNG 集团、Meta、Cohere、北京人工智能研究院、多模态艺术投影、华为
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。