AI 大神 Karpathy 2025 年度总结刷屏:AI 既是天才也是智障,这 6 个转折最关键

最近各种年度回顾陆续上线, OpenAI 的前联合创始人 Andrej Karpathy 也交出了自己对大模型的年度总结
就在今年早些时候,他在 YC 的一场演讲刷爆了全网,提出了不少新的观点:
- 软件 3.0 已来: 从最初的人写代码(1.0),到喂数据训练模型(2.0),现在我们进入了直接对模型「念咒语」(Prompt)的 3.0 时代。
- LLM 是新操作系统: 它不是像自来水一样的普通商品,而是一个负责调度内存(Context Window)和 CPU(推理算力)的复杂 OS。
- Agent 的十年: 别指望 AI Agent 一年就成熟,从 99% 到 99.999% 的可靠性,我们需要走上十年。
Karpathy 今天这篇《2025 年度总结》,他再次向我我们剖析了这一年 AI 究竟长出了什么样的「脑子」。
以下是对 Karpathy 年度总结的精译,APPSO 在不改变原意的基础上做了更多通俗解读。
如果想看原文可以点击 https://karpathy.bearblog.dev/year-in-review-2025/
https://karpathy.bearblog.dev/year-in-review-2025/
2025 年是 LLM(大语言模型)发展强劲且充满变数的一年。以下是我列出的几点个人认为值得注意且稍感意外的「范式转变」——这些变化不仅重塑了行业版图,更在概念层面上狠狠地冲击了我的认知。
 太长不看版:
太长不看版:
2025 年既让人兴奋,又有点让人措手不及。
LLM 正在作为一种新型智能涌现,它同时比我预期的要聪明得多,也比我预期的要笨得多。
无论如何,它们极其有用。我认为即使以目前的能力,行业甚至还没挖掘出其潜力的 10%。同时,还有太多的想法可以尝试,从概念上讲,这个领域感觉依然广阔。正如我今年早些时候提到的,我同时(表面上矛盾地)相信:我们将看到持续快速的进步,但前方仍有大量艰苦的工作要做。
系好安全带,我们要发车了。
1. RLVR:教 AI 像做奥数题一样「思考」
在解释这个复杂的基础概念之前,先看看以前是大模型训练是怎么做的?
在 2025 年初,各大实验室训练 LLM 的「老三样」配方非常稳定:
1. 预训练(Pretraining):像 GPT-3 那样,让 AI 读遍全网文章,学会说话。
2. 监督微调(SFT):找人写好标准答案,教 AI 怎么回答问题。
3. 人类反馈强化学习(RLHF):让 AI 生成几个答案,人来打分,教它讨人喜欢。
现在发生了什么变化?
2025 年,我们在这个配方里加了一味猛药:RLVR(从可验证奖励中进行强化学习)。
这是什么意思?
简单来说,就是不再让人来打分(人太慢且主观),而是让 AI 去做那些「有标准答案」的任务,比如数学题或写代码。对就是对,错就是错,机器能自动验证。
在数百万次的自我博弈和试错中,模型自发地演化出了看似「推理」的策略。它们学会了先把大问题拆解成小步骤,甚至学会了「回过头来检查」这种高级技巧(参考 DeepSeek R1 论文)。
核心对比:
- 旧范式(RLHF): 像是教小孩写作文。因为没有标准答案,AI 很难知道自己哪一步想错了,只能模仿人类的语气。
- 新范式(RLVR): 像是把 AI 关进奥数训练营。不用教它具体怎么想,只要给它足够多的题和对错反馈,它自己就能摸索出解题套路。
这一招太好用了,以至于 2025 年大部分算力都被这只「吞金兽」吃掉了。结果就是:模型并没有变大,但训练时间变长了。 我们还获得了一个新旋钮:让 AI 思考得久一点。OpenAI 的 o1 是开端,而 o3 则是真正的拐点。
2. 幽灵 vs 动物:AI 不是「电子宠物」
2025 年,我和整个行业终于从直觉上理解了 LLM 智能的「形状」。
一个惊悚的比喻:我们不是在像养宠物一样「进化/养育动物」,我们是在「召唤幽灵」。
为什么这么说?
因为 AI 的一切都和生物不同。人类的大脑是为了在丛林里活下来、为了繁衍后代而优化的;而 LLM 的大脑是为了模仿人类文字、在数学题里拿分、在竞技场里骗赞而优化的。
参差不齐的智能(Jagged Intelligence):
正是因为 RLVR(可验证奖励)的存在,AI 的能力在某些领域(如数学、编程)会突然飙升成刺状。这就导致了一种极其滑稽的现象:
- 它同时是一个绝世天才(秒解高数题);
- 又是一个智障小学生(会被简单的逻辑陷阱骗得团团转)。
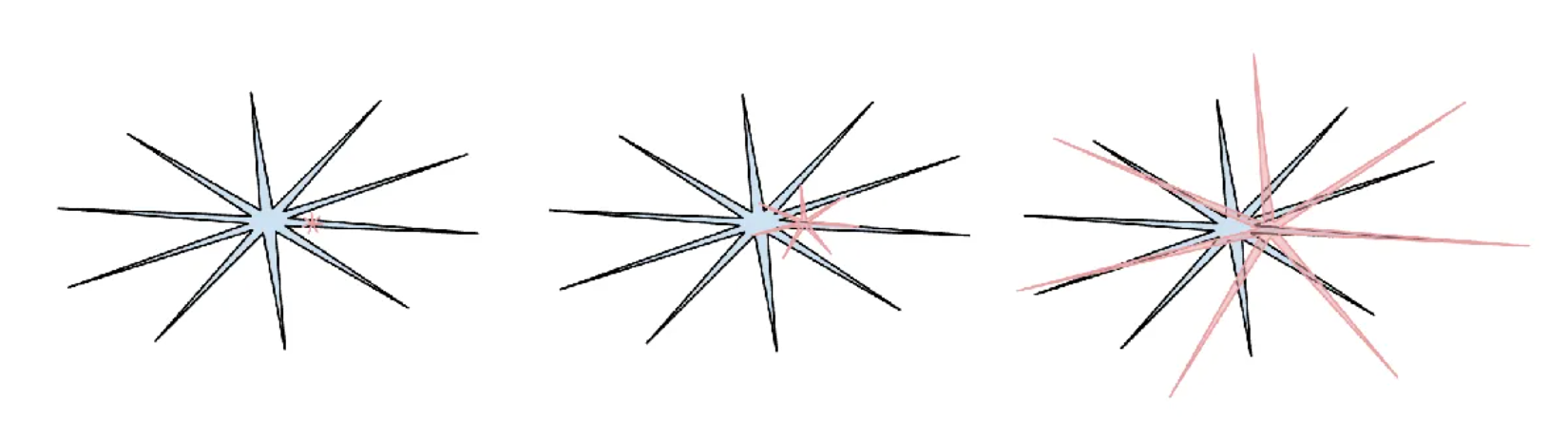
▲这里 Karpathy 引用了一张梗图:人类智能是圆润的蓝色圆圈,AI 智能是像海胆一样满是尖刺的红色图形。这很形象.
这也解释了为什么我对现在的「跑分榜单」(Benchmarks)失去了信任。
什么是「刷榜」的本质?
既然榜单是可验证的,那就可以用 RLVR 针对性训练。现在的实验室都在搞「应试教育」,把 AI 的能力尖刺专门往考题上长。「在测试集上训练」已经不仅仅是作弊,而成了一门新的艺术形式。
3. Cursor:不仅是编辑器,更是「包工头」
Cursor 今年的爆火,揭示了一个新真相:LLM 应用层比我们想象的要厚。
大家开始谈论「医疗界的 Cursor」、「法律界的 Cursor」。这些应用到底做了什么?
- 「上下文工程师」: 帮你整理好所有背景资料喂给 AI。
- 「工头」: 在后台偷偷指挥多个 LLM 干活,把复杂任务拆解,还要帮你省钱。
- 「遥控器」: 给你一个调节「自主性」的滑块,决定放手让 AI 干多少。
预测:大模型实验室(如 OpenAI)会负责培养「全科大学生」;而应用开发商(如 Cursor)则负责给这些学生提供私有数据和工具,把他们组建成「专业施工队」。
4. Claude Code:住在你电脑里的「赛博幽灵」
Claude Code (CC) 的出现让我眼前一亮。它不仅仅是一个能写代码的 Agent(智能体),更重要的是:它活在你的电脑里。
对比来看,我认为OpenAI 搞错了方向。
OpenAI 早期的 Agent 都在云端跑(ChatGPT),离你的真实环境太远。虽然云端智能体听起来像是 AGI 的终局,但在当前这个「参差不齐」的过渡阶段,本地才是王道。
为什么本地很重要?
因为你的代码、你的配置、你的密钥、你的混乱环境,都在本地。Anthropic(Claude 的母公司)搞对了优先级,他们把 AI 塞进了一个小小的命令行界面(CLI)里。
它不再是你浏览器里的一个网页(像 Google 那样),它变成了一个寄宿在你电脑里的「赛博幽灵」,随时准备帮你干活。这才是未来 AI 交互的样子。
5. Vibe Coding
什么是 Vibe Coding?
这是我在推特上随口造的一个词(居然火了):意思是写代码不再需要你真的懂语法,你只需要用英语描述你的「意图」和「感觉」,剩下的交给 AI。
这带来了什么改变?
- 对于普通人: 编程的门槛彻底消失了。
- 对于专家: 代码变得像纸巾一样「廉价、一次性、用完即弃」。
举个例子,我为了找一个 Bug,可能会让 AI 现场写一个专门的 App 来测试,测完就删。放在以前,为了找个 Bug 专门写个 App?疯了吧!但在 2025 年,代码是免费的。
Vibe Coding 将会彻底重塑软件行业,也会改写程序员的招聘 JD。
6. Nano Banana:AI 终于有了自己的「脸」

为什么现在的 AI 交互很反人类?
不管是 ChatGPT 还是 Claude,我们还在用「打字」跟它们聊天。这就像 80 年代还在用 DOS 命令行的黑底白字。
事实是: 计算机喜欢文本,但人类讨厌读文本。人类是视觉动物,我们喜欢看图、看表、看视频。
Google Gemini Nano banana(这是一个虚构的模型代号,指代某种多模态交互模型)是 2025 年的另一个范式转变。它暗示了未来的 LLM GUI(图形界面) 是什么样子的。
未来的 AI 不应该给你吐一堆字,它应该直接给你画一张图、生成一个网页、弹出一个交互面板。 这不仅仅是「画图」,而是将文本生成、逻辑推理和视觉表达纠缠在一起的混合能力。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。