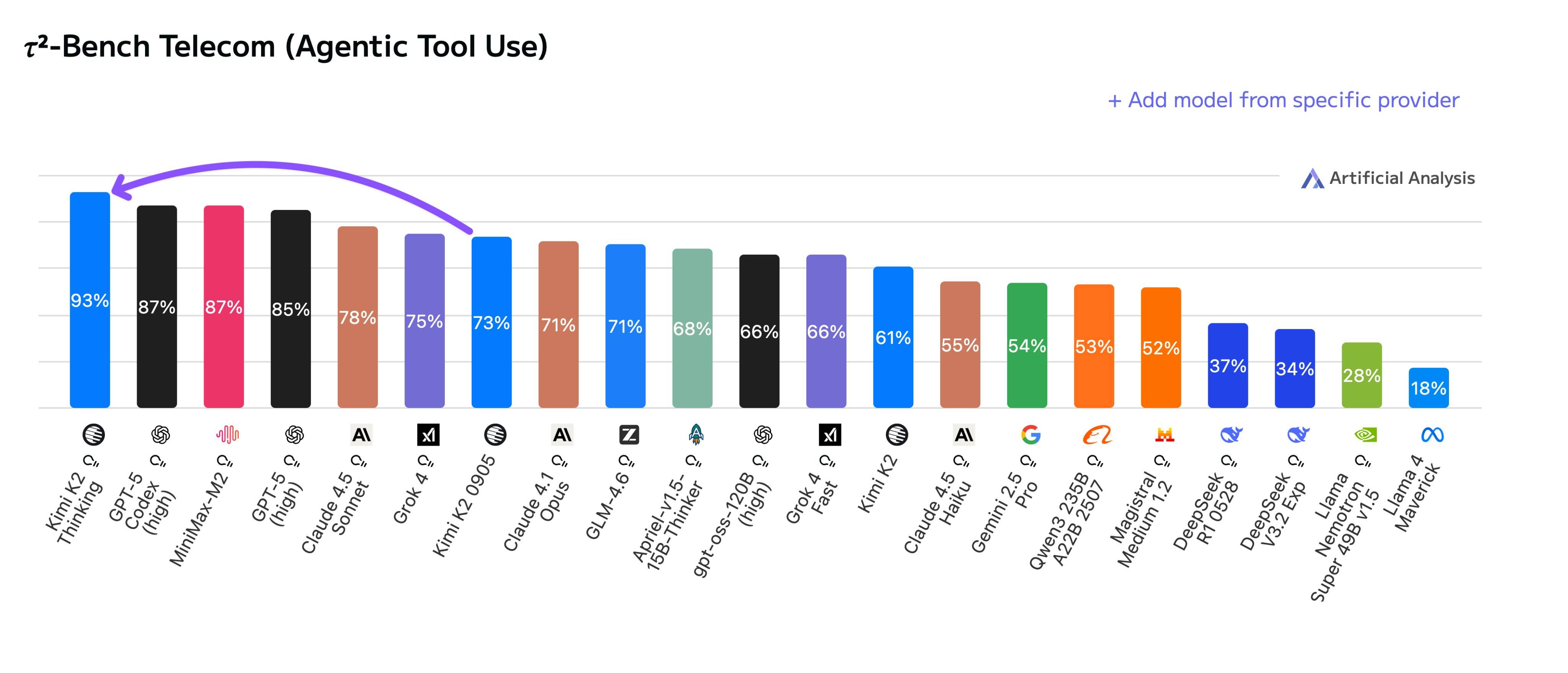
我想重走《长安的荔枝》路,千问「办事」直接把「通关文牒」给订好了

刚刚过去的 2025 年,可以说是 Agent 爆发的一年。
特别是各种能自主「执行任务」的 Agent,甚至能够模仿人类操作手机,只是惊艳之余,Agent 实际能完成的事情仍然有限。
背后的原因,除了模型能力尚待提升,更难以逾越的是现实中那一道道封闭的 App 壁垒:由于不同生态间相对独立、数据互不相通,AI 即使听得懂指令,也无法实际拉取服务,甚至还会被 App 提供方封禁。
面对这种「有心无力」的行业困境,阿里破局的尝试很巧妙——从自己的生态做起。
今天千问 App 大更新,一口气上线400多项新功能,集成了阿里系丰富的服务生态,走出了一条不一样的 Agent 路线。

凭借这个覆盖衣食住行的阿里生态,千问成为了世界上第一个能调用多种生活服务,真正把下单键搬到对话框的 AI 助手。
重走《长安的荔枝》路,千问把小红书不存在的攻略给我做了出来
千问办事的一个核心功能是「任务助理」,能够处理更复杂的信息,也能真正执行一些任务。
比如说,定制一条独一无二的旅游线路。
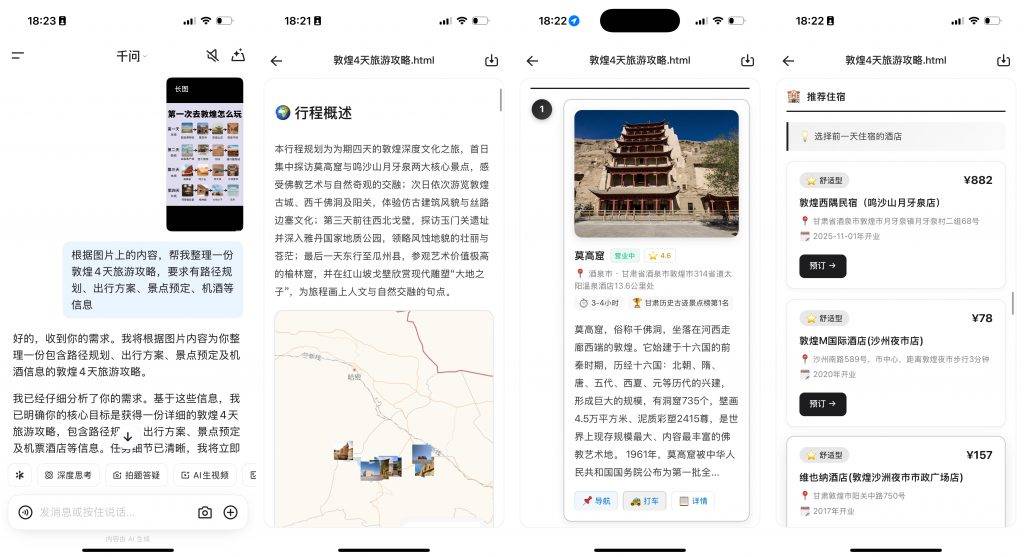
普通的旅游攻略,上小红书找找就有,但我这人就偏不想走寻常路。我是个狂热影迷,之前看了《长安的荔枝》后,就特别想走一走李善德那条从广州到西安「荔枝道」。
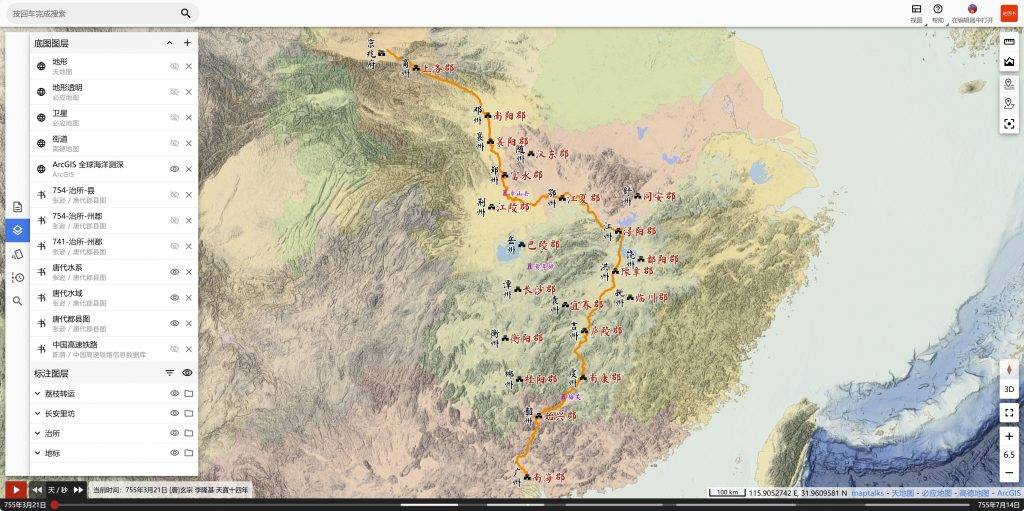
▲ 图源:知乎@地图书
这次我就给千问「办事」上点难度,看能不能满足我这个小众的旅行需求。
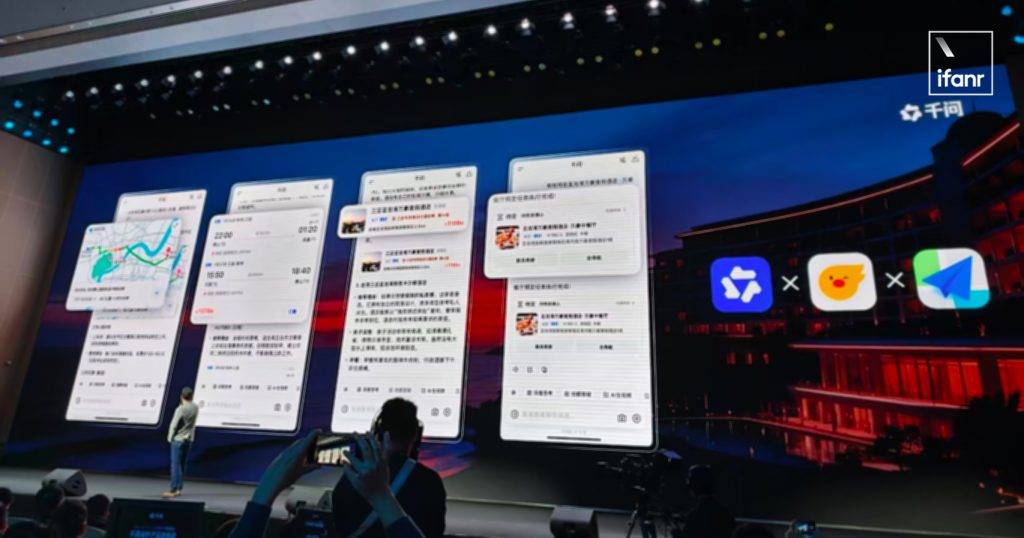
这条路线的规划难度极高,首先古「荔枝道」至少有四条,全长超 1600 公里,不仅要筛选出最具观赏性的路段,还要在短短 7 天内搞定沿途复杂的交通和住宿。

这种需求搁在以前,即便你是资深驴友,也得在几个 App 之间反复横跳,耗费几天才能理清头绪。
但千问只用了不到 5 分钟,就把整个路线和行程安排交付到我手上:从广州出发,经江西,直抵陕西,这刚好就是小说中主角最终选择的路线。
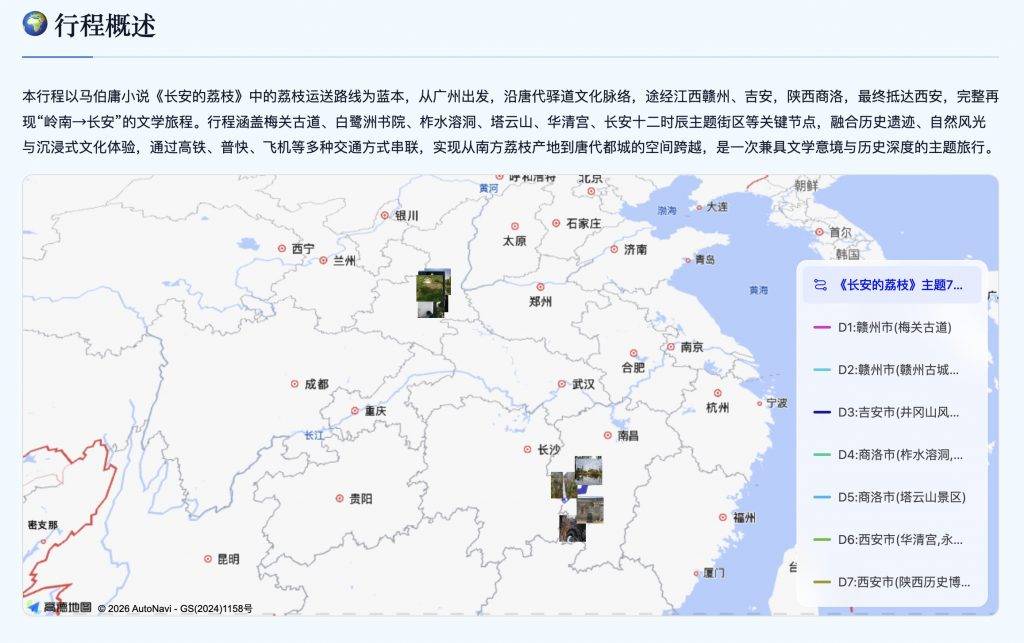
千问选择的景点还颇具品味,兼具人文和自然风光:江西选择了梅关古道和井冈山这样的著名风景区、陕西则聚焦在华清宫、永庆坊这些唐代古址,紧扣「长安的荔枝」主题。
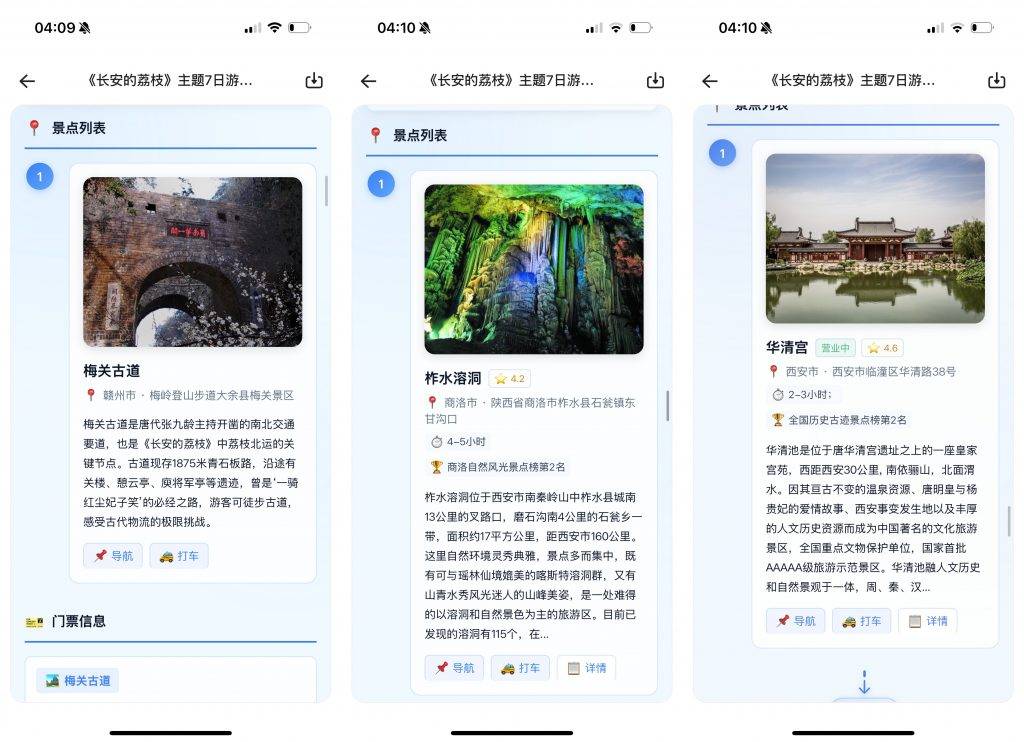
但这还不是千问最「杀手级」的体验。
路线安排只是基础,它规划行程的同时,还能直接把「手」伸进了飞猪和高德的后台,将景点、交通、酒店的预订信息一并附上,坐哪趟火车,订哪家酒店,全部仔仔细细安排明白。
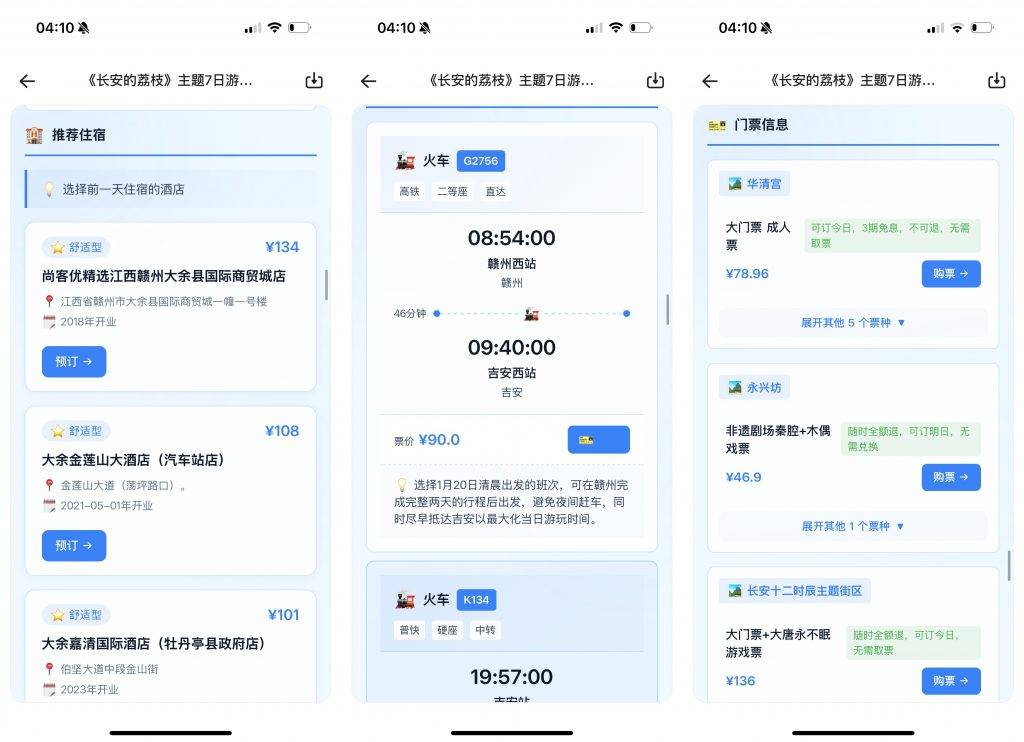
它甩给你的不再是冷冰冰的文字建议,而是真正的飞猪和高德地图服务,点开就能看到详情,全部等着用户下单。
![]()
这也是千问这个新形态给我印象最深的地方——直接联动阿里的各种服务,不仅是超级「大脑」,还长出「手脚」,帮用户把事情办了。
以往,想要自己定制一条旅游线路,用户不可避免往返平台做攻略和预订,消耗不少时间精力,现在一句话,千问就能帮你把事情安排妥当,用户唯一要做的事情,就是最后的付款。
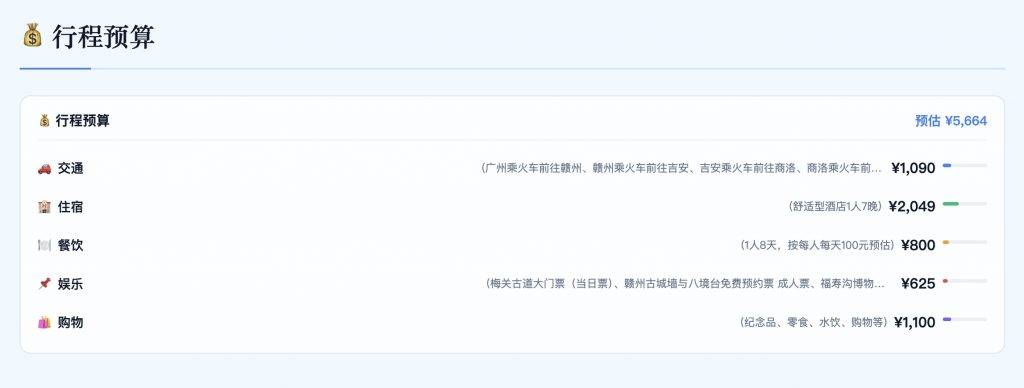
除了飞猪和高德,千问办事还集成了淘宝、闪购和支付宝。
「点外卖」已经成了 Agent 能力的练兵场,对于千问来说自然不再话下。我直接给它上强度:
帮我买 100 杯咖啡,要 30 杯冰美式,30 杯生椰拿铁,20 杯拿铁、20 杯橙 C 美式,全部要冰的。
即便是人类,点 100 杯不同种类的咖啡,也免不了一番繁琐操作,而且因为点单数量限制,还得在不同店铺间来回下单。
和旅游攻略一样,千问的「任务助理」只需 3 分钟,就能把所有需要的商品「加购物车」,只待用户下单付款。
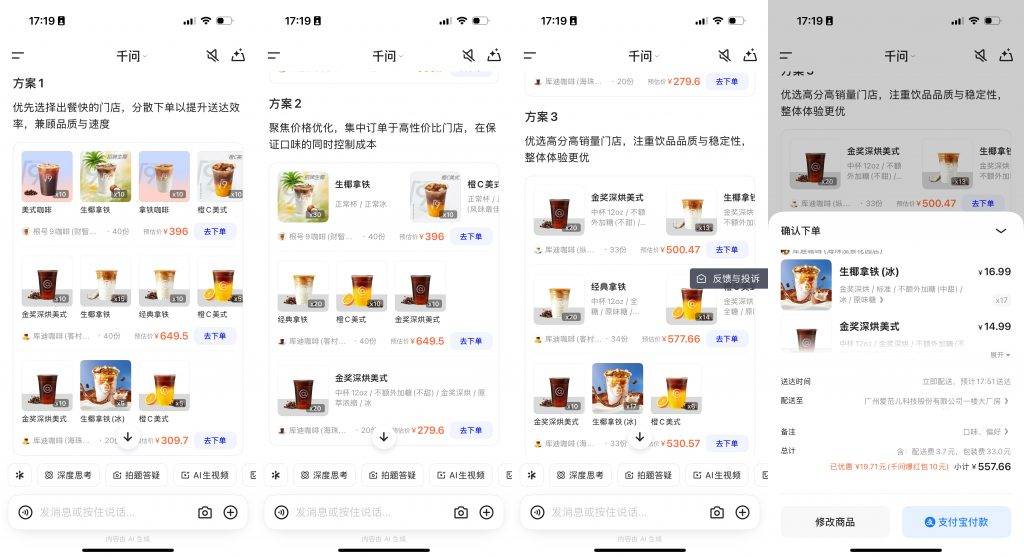
比起单纯点外卖,让 AI 帮我们比价、选购的网购能力,更符合用户期待,也成为 AI Agent 的必争之地。
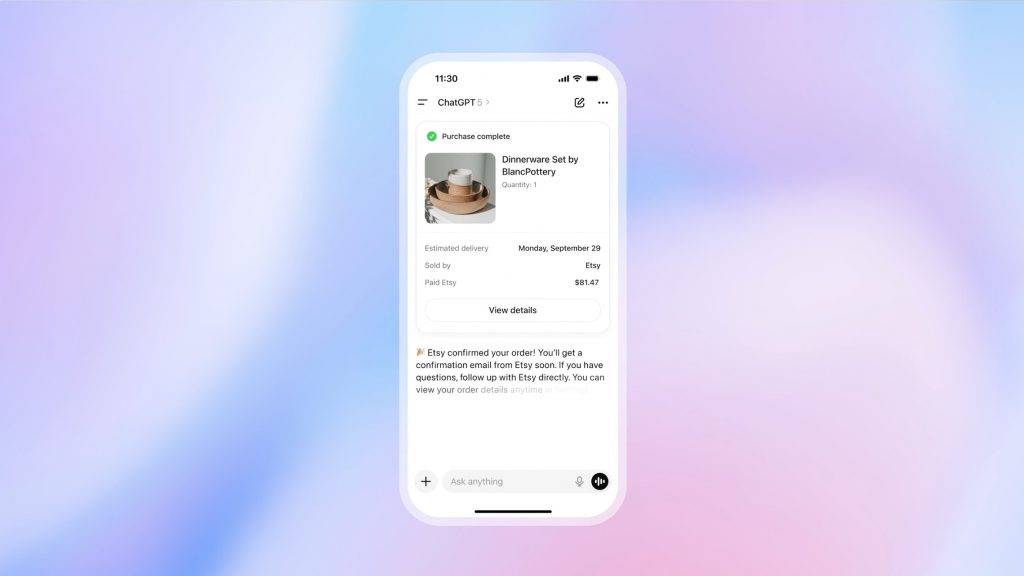
▲ ChatGPT 与 Etsy 的集成
像买电视这样选择繁多、需要在各个平台反复比对,且需求因人而异的购物场景,非常适合交给千问来处理。
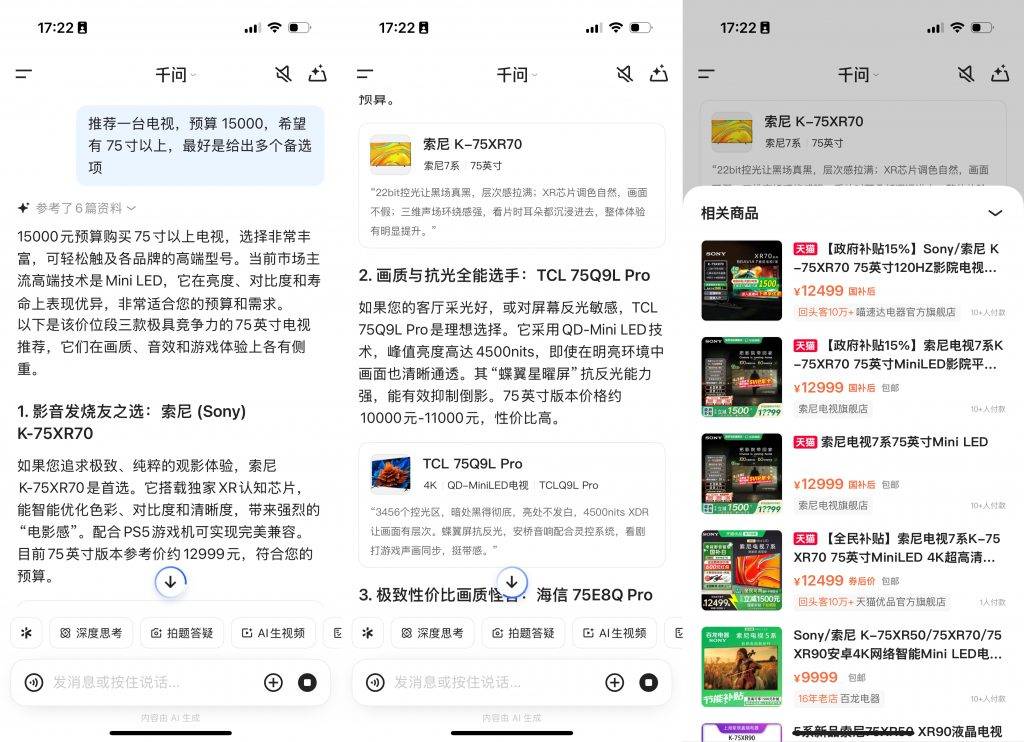
只要明确大致的预期,千问就能直接附上两三张具体的淘宝商品卡片,佐以详尽的推荐理由,消费决策的难度一下子变得很低。
它可不是从浩如烟海的电视型号中随机抽出几个敷衍了事,而是根据电视的核心参数,以及不同的场景需要进行甄选。我还专门用一样的需求反复测试,千问每次的推荐产品和理由都基本一致。
作为一位长期关注电子产品的科技编辑,我认为千问给出的选购建议相当靠谱。
提到阿里系平台,自然绕不开支付宝。
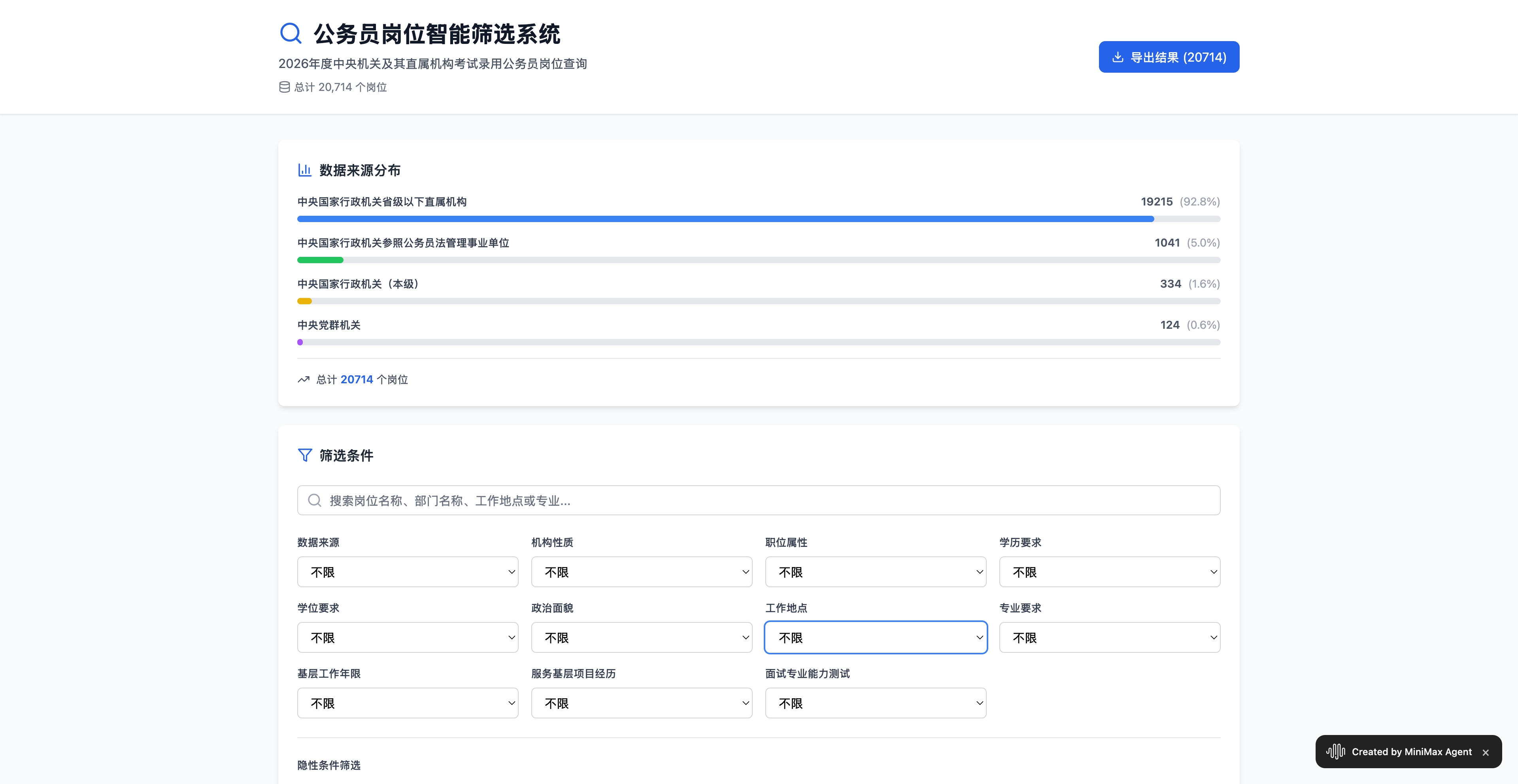
作为一个整合了丰富生活与民生服务的平台,支付宝的加入让千问能够处理 50 多项政务事务,实现真正的「一站式办事」能力。
![]()
可以这么说,千问或许是世界上唯一一个能直接将公积金提取入口带到你面前的 AI 机器人。
要让这些能力真正落地,千问 AI 的智能理解与阿里生态的丰富服务缺一不可:前者提供「大脑」,后者提供「手脚」。
过去三年,尽管各家 AI 在「大脑」能力上不断升级,但实际落地场景依然有限。要实现真正突破,AI 必须长出「手脚」,能够亲自动手办事。
凭借 20 多年的互联网生态积累,以及自研强大模型的加持,阿里无疑最适合迈出这关键的一步。
AI 的「办事」时代来了
体验完千问的这次更新,我发现 AI 真的开始接管现实世界的「办事权」了。
在千问推出「办事」功能之前,行业对 AI Agent 办事能力的探索主要走了两条路线:一是「模拟用户」,二是「开放接口」。但这两种模式都有很多限制,无法让 AI 丝滑给用户提供服务。
在这两种模式都陷入僵局时,阿里千问走出了第三条路:直接把服务,做进 Agent 里。
我在使用过程中,能清晰感知到这种「原生」带来的质感差异。
它生成的不是干巴巴的跳转链接,而是功能完备的服务卡片。这种体验,就像在飞猪里看酒店、在淘宝里看购物车一样自然流畅。
并且,大部分生成的结果,都是用户可以直接用支付宝下单,点一杯奶茶最快只需要 30 秒。
更重要的是,这在很大程度上规避了隐私雷区。因为从头到尾,数据都只在阿里这一套账号体系内流转,没有流出第一方,这种安全感是第三方插件无法给予的。
我认为,千问办事目前展现的能力,还只是冰山一角,随着服务集成进一步深入,还会释放出更多潜力。
如果把视角拉大到全球科技版图,你会发现千问的这次抢跑,实则踩准了一个全球科技公司都在角逐的关键节点:AI 电商(Agent Commerce)。
就在四天前,大洋彼岸的 Google 刚刚宣布与沃尔玛等零售商达成 AI 购物合作,试图通过 UCP 协议组建一个「开放联盟」。而现在,阿里已经凭借千问后来居上,成为了全球首个实现多品类、全链路 AI 购物的科技公司。
![]()
这并非偶然,背后是两种不同技术路线的必然结果。
与 Google 试图连接外部松散盟友的模式不同,千问展现的是一种极致的「垂直整合」能力:底层是千问大模型作为大脑,上层则直接打通了淘宝的商品库、支付宝的支付体系以及高德饿了么的履约网络。
正是这种「模型+生态」的深度协同,让阿里率先解决了 AI Agent 落地中最棘手的两个难题——「决策信任」与「支付断点」。
当其他 AI 还在通过跳转外部链接来规避责任时,千问已经在一个 App 内闭环完成了从搜索、决策到支付、履约的全过程。
这一赛道的拥挤程度,足以证明其价值。OpenAI 不久前推出了「即时结账」,Perplexity 宣布联手 PayPal,微软也在对话中嵌入购物推荐。麦肯锡更是预测,在智能体商业的推动下,2030 年全球零售市场的潜在增量将达到 3 万亿至 5 万亿美元。
在这场万亿级的竞争中,阿里利用自身独有的生态壁垒,抢先完成了「搜索-决策-支付-履约」的完整拼图,在将 AI 转化为实际消费力的道路上,拿到了第一张入场券。
更令人兴奋的,是这种「全链路打通」背后的可能性。
从鼠标点击(Click)到手指触控(Touch),再到如今以千问为代表的 AI ,我们正站在第三次人机交互改革新的十字路口。
LUI(语言用户界面)正在取代 GUI(图形用户界面),语言已然在成为新的操作系统,从这个角度看来,千问不再是一个单纯的 APP,更有可能成为某种系统级的存在。
还记得,乔布斯在 2007 年发布第一代 iPhone 时,他演示了用 Google Map 定位星巴克并拨打电话订咖啡——那是一个时代的开端。
而今天,我们只需要对千问说一句话,就能在半小时后真实收到 500 杯包含复杂需求的奶茶。这就是 AI 真正长出「手脚」、打破 App 孤岛的开端。
试想一下,当 AI 真正拥有了跨应用的数据视野,它能做的事情将远超「买东西」的范畴:
它或许能根据你在淘票票的观影历史,结合豆瓣评分,从上万部新片中精准筛选出你最可能喜欢的电影;
它或许能根据你在淘宝购买的教辅资料,自动规划学习路径,甚至联动夸克整理出错题集。

这并非凭空画饼,而是基于「生态数据打通」这一技术逻辑的合理推演。此前,不管是比尔 · 盖茨还是马斯克,都曾预言 AI 将终结 App 时代。
当 AI 不再被一个个 App 的围墙阻隔,当数据开始在生态内自由流动,我们得到的将不再是一个冰冷的工具,而是一个真正懂你、能帮你在这个信息过载的世界里高效「办事」的数字分身。
这,或许才是 AI「办事时代」真正的终局。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。