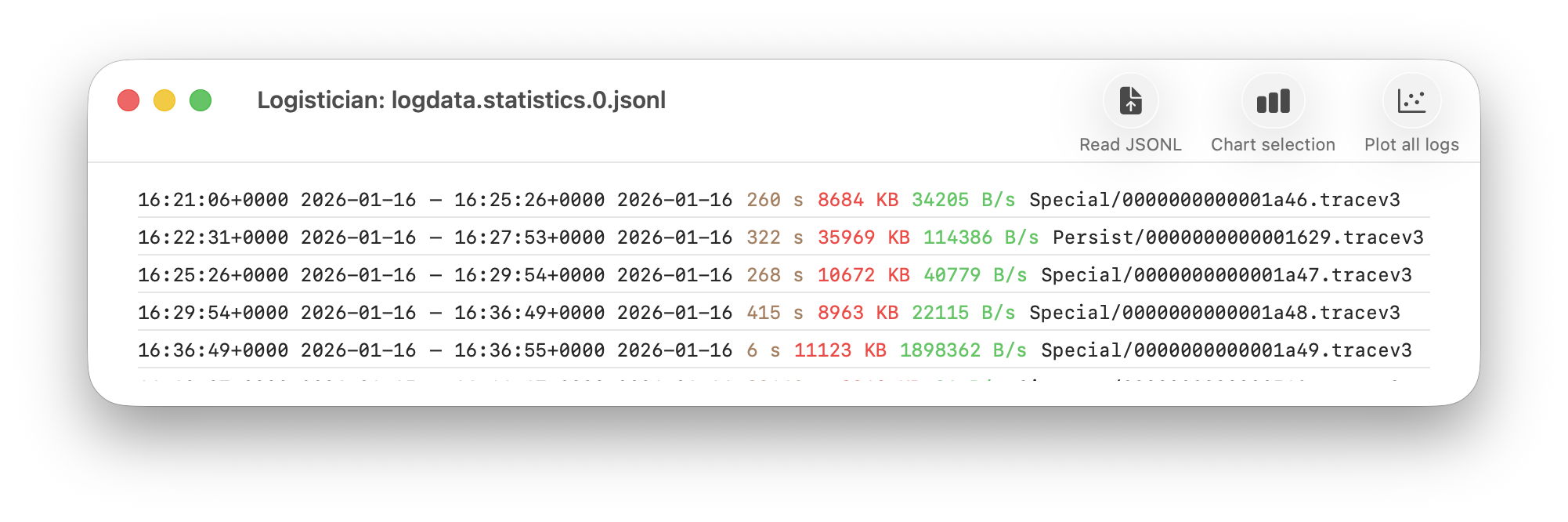
How long does the log keep entries?
One of the most contentious questions arising from yesterday’s critical examination of ChatGPT’s recommendations, is how long does the Unified log keep entries before they’re purged? ChatGPT seemed confident that some at least can be retained for more than a month, even as long as a year. Can they?
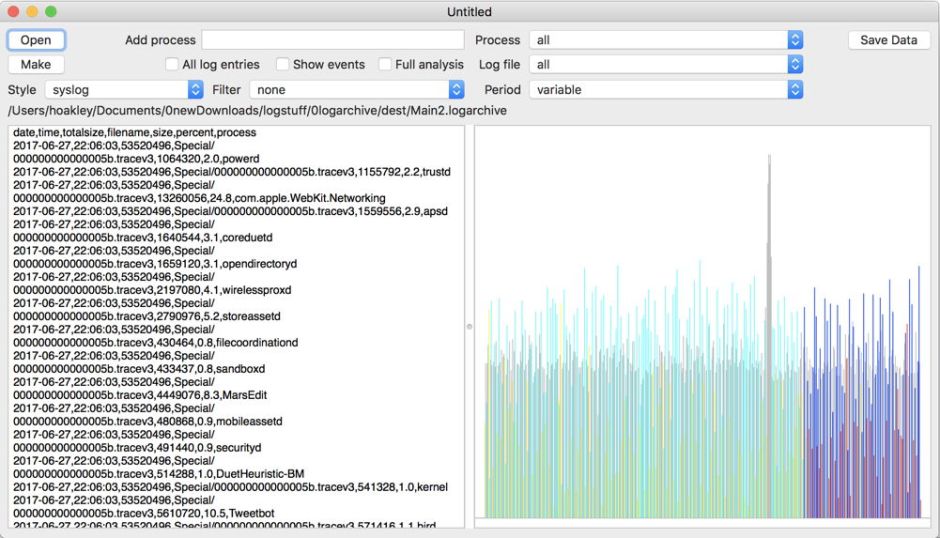
Traditional text logs are removed after a fixed period of time. One popular method is to archive the past day’s log in the early hours of each morning, as part of routine housekeeping. Those daily archives are then kept for several days before being deleted during housekeeping. That’s far too simple and restrictive for the Mac’s Unified log.
Apple’s logs, in macOS and all its devices, are stored in proprietary tracev3 files, sorted into three folders:
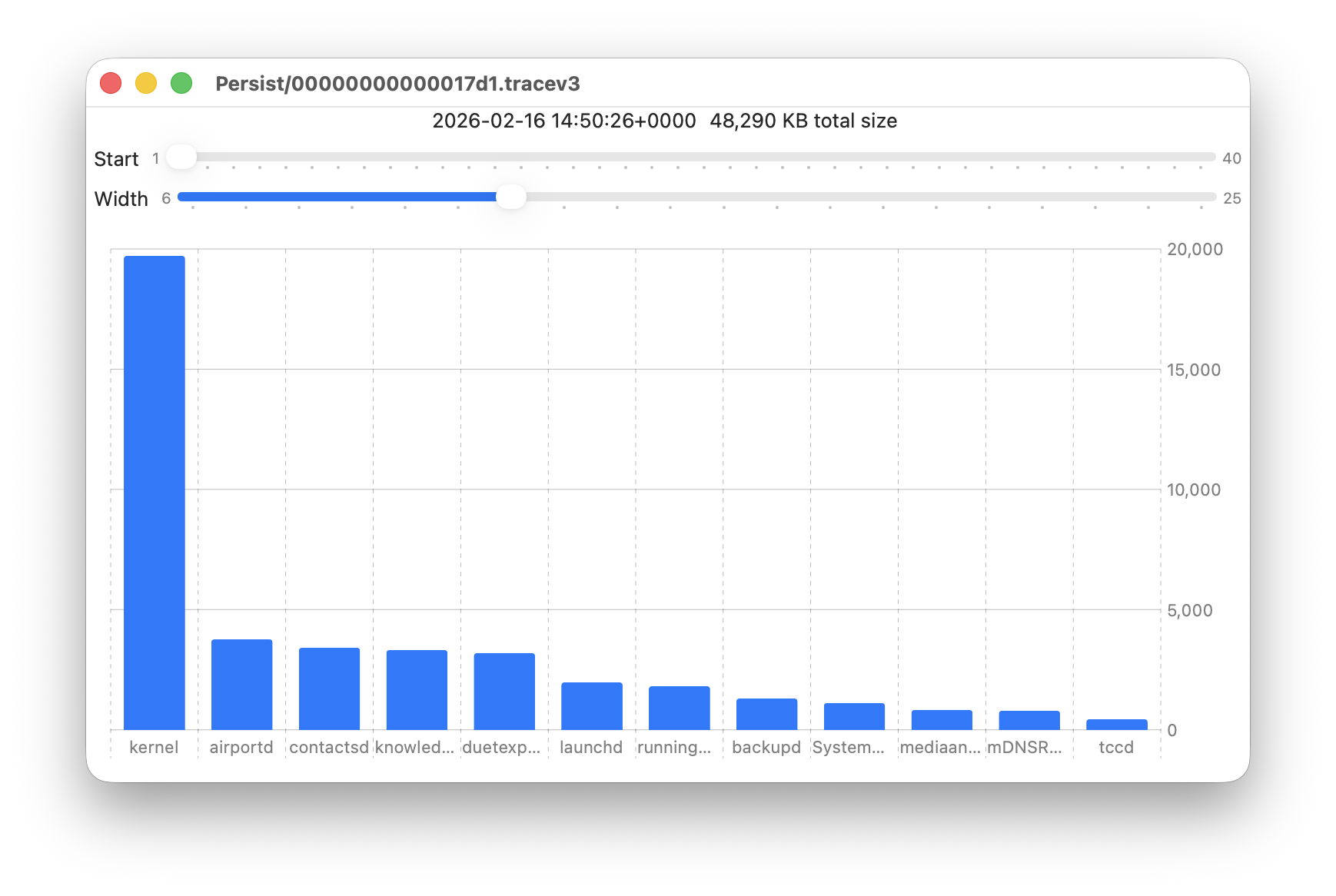
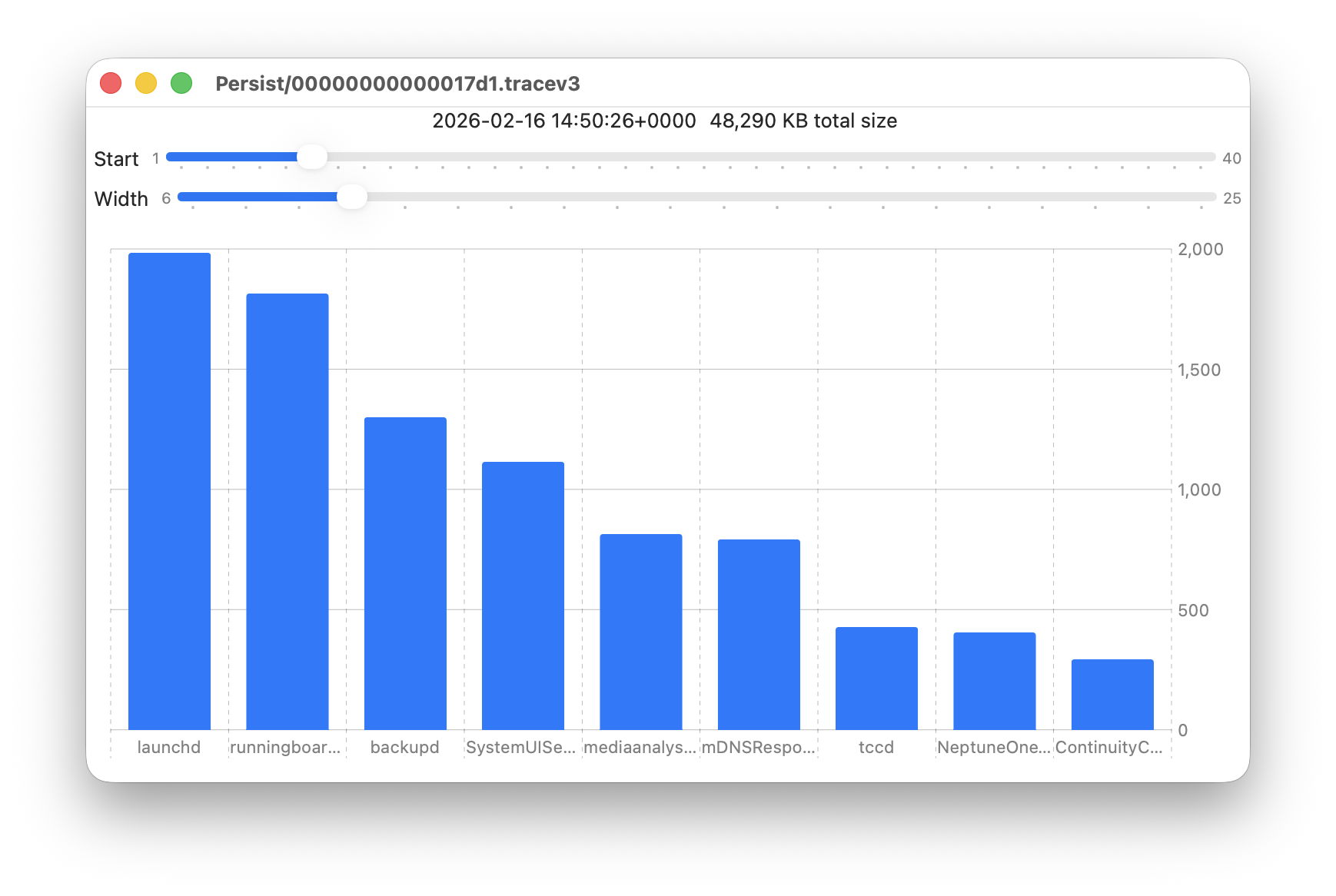
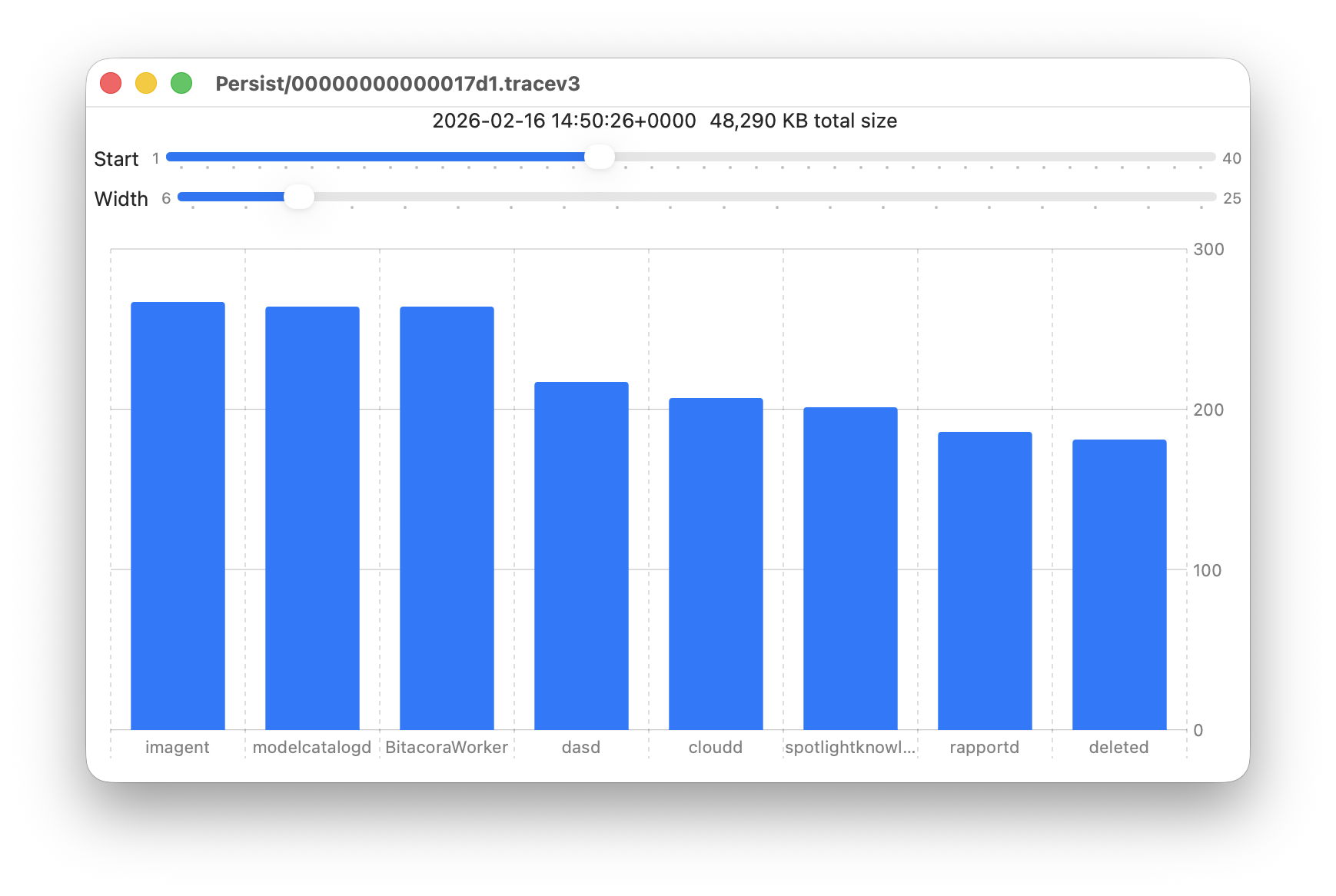
- Persist, containing the bulk of log entries, retained to keep their total size to about 525 MB in about 50-55 files;
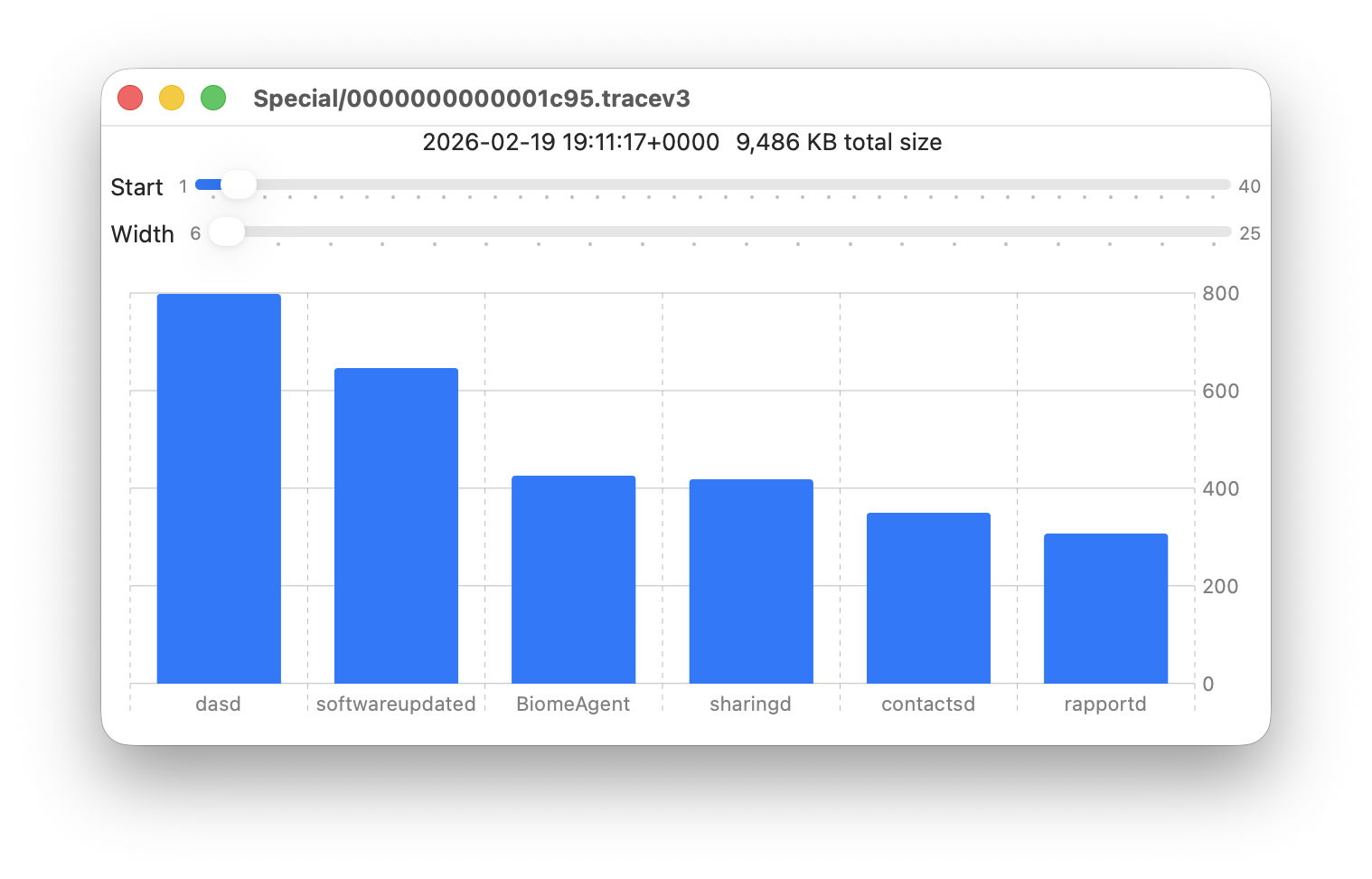
- Special, including fault and error categories, whose entries are slowly purged over time until none remain in the oldest log files, so have a variable total size and number.
- Signpost, used for performance measurements, which also undergo slow purging until they vanish.
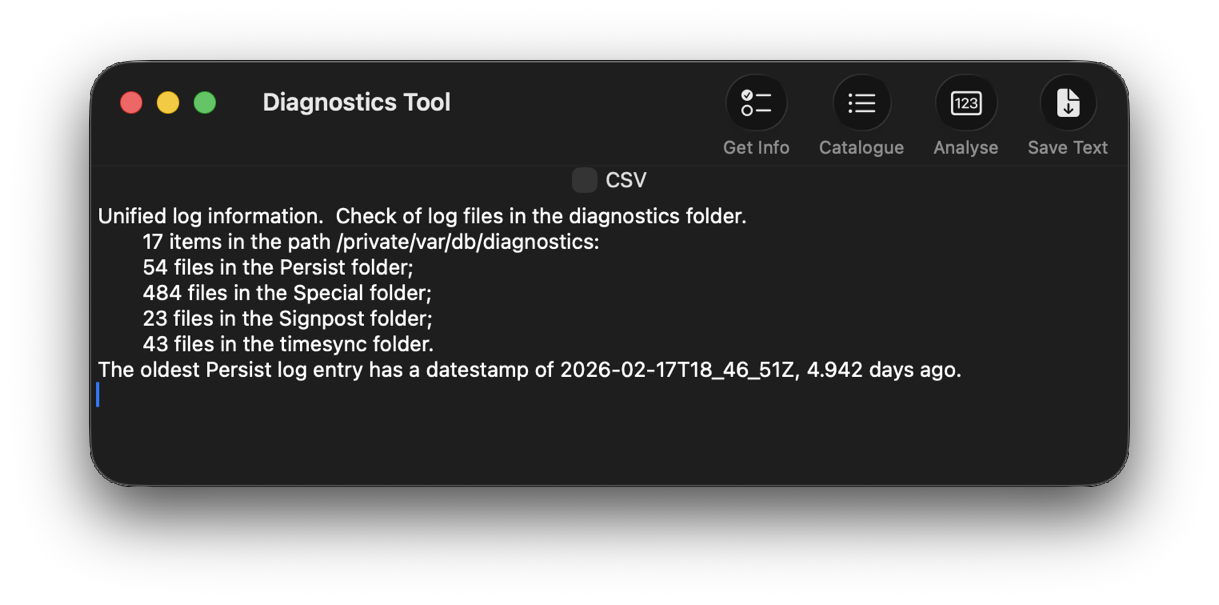
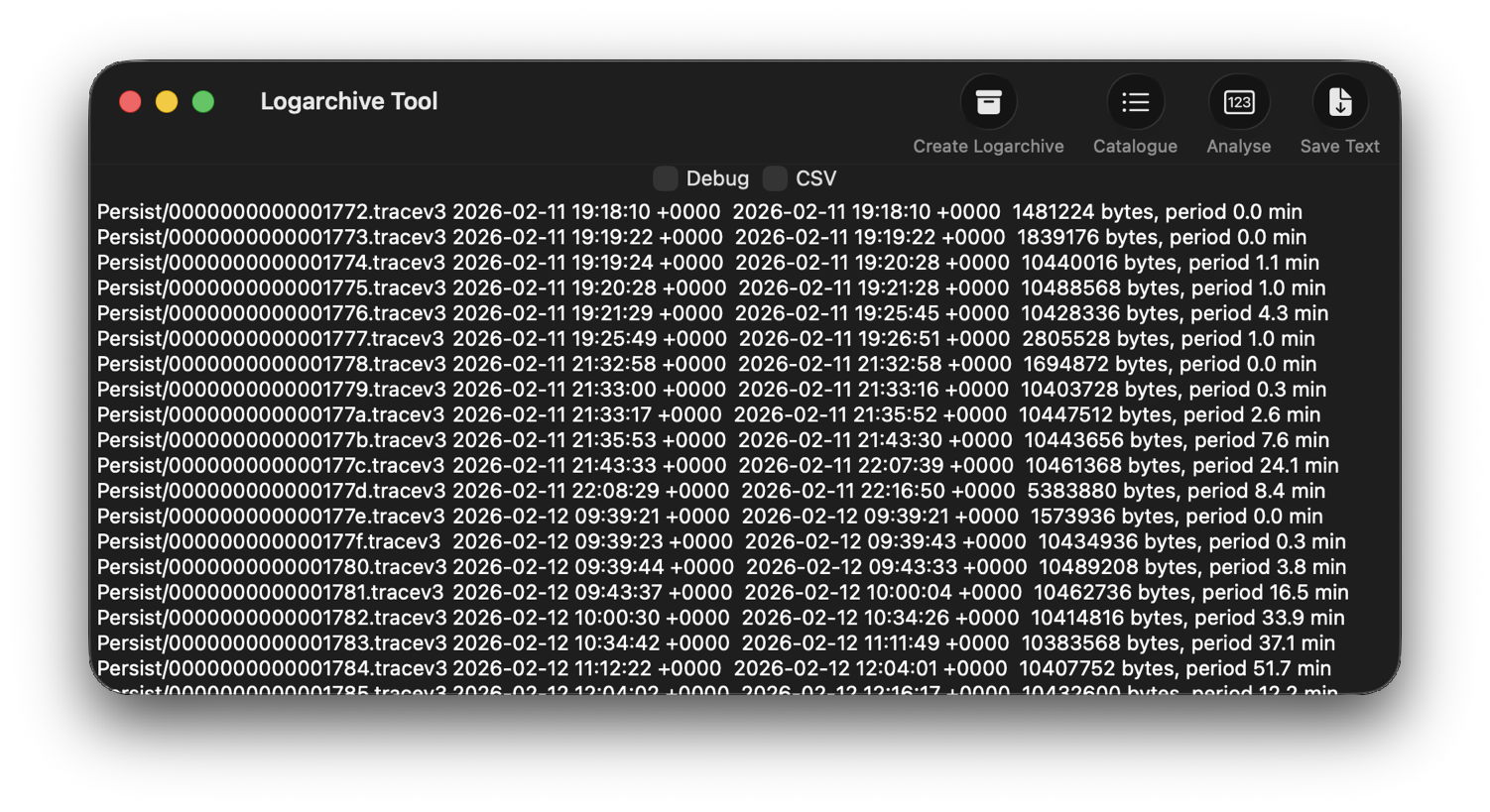
One simple way to estimate the period for which log entries are retained is to find the date of creation of the oldest log file in each of those folders. On a Mac mini M4 Pro run largely during the daytime, those dates were
- Persist, earliest date of creation 7 March 2026 at 16:54
- Special, 9 February 2026 at 19:41
- Signpost, 3 March 2026 at 16:41
when checked on 10 March. Those indicate a full log record is available for the previous 3 days, followed by a steady decline with age to the oldest entry 31 days ago. That compares with statistical data available in my app Logistician going back as far as 14 January, although all entries between then and 9 February have now been removed and lost.
Retrieving old log entries
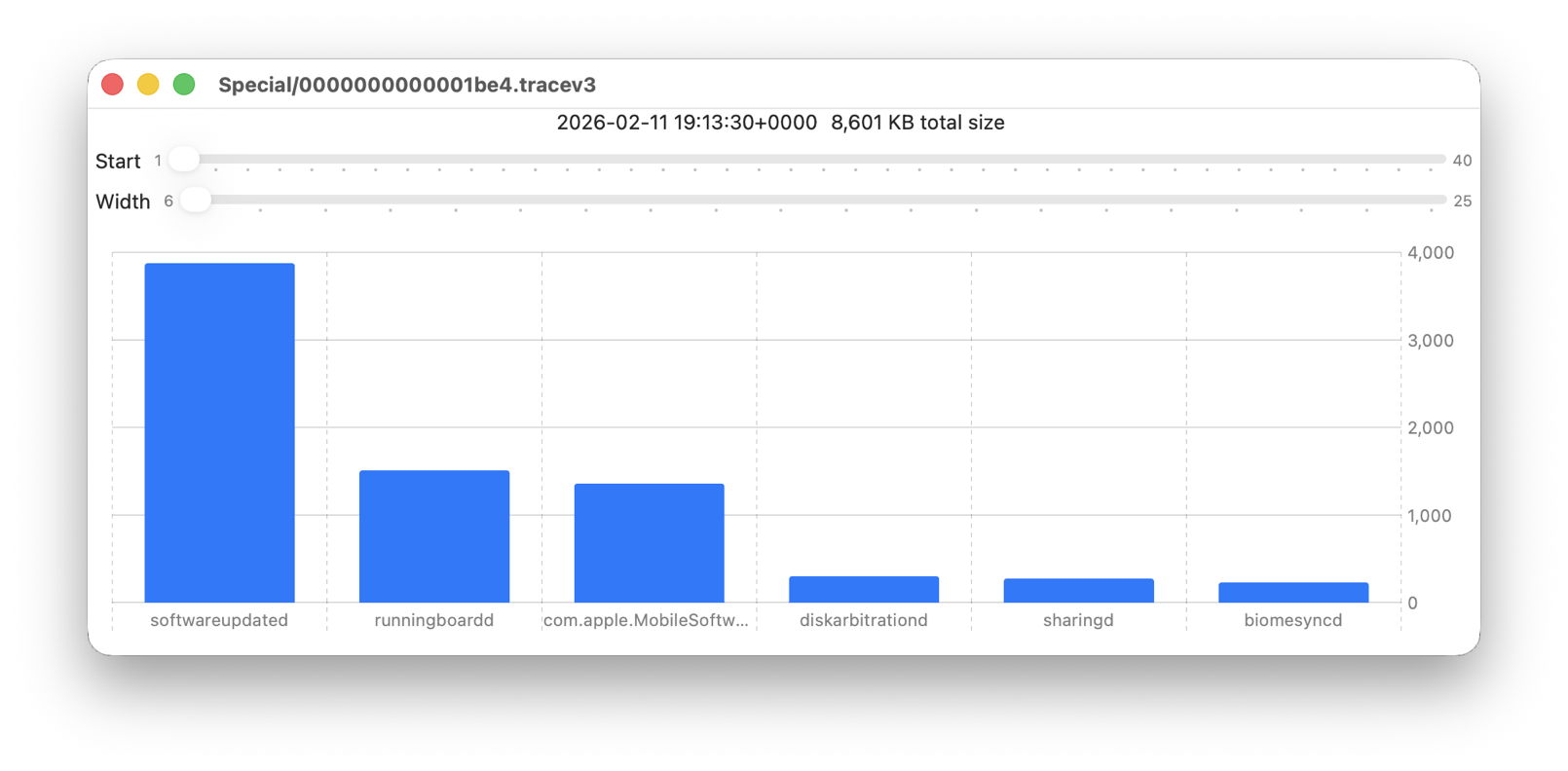
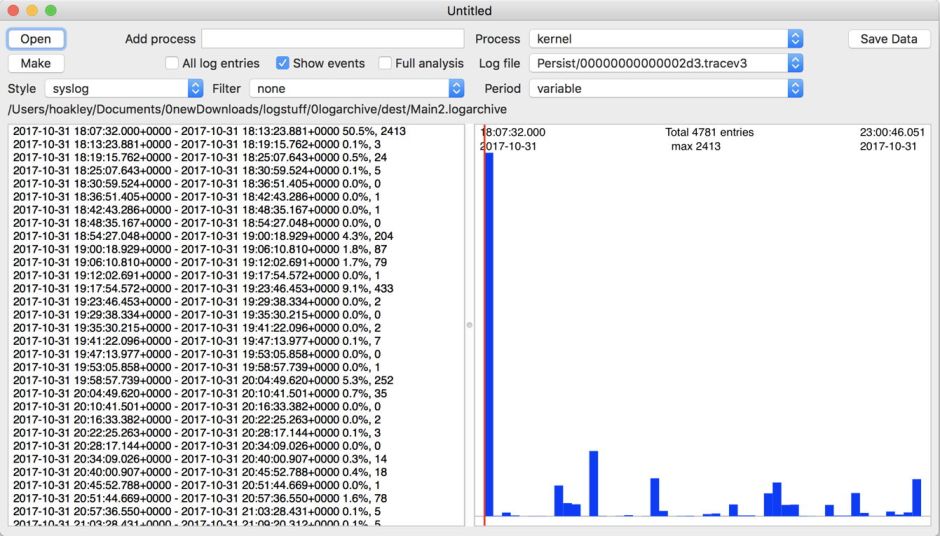
The real test of how many log entries have been retained is to try to retrieve them. Although the oldest Special log file was created on 9 February, the oldest log entry I could retrieve was the start of the boot process on 11 February, in Special log files returning a total of over 44,000 entries for that day. However, no further log entries could be found after those until the morning of 24 February, a gap of over ten days.
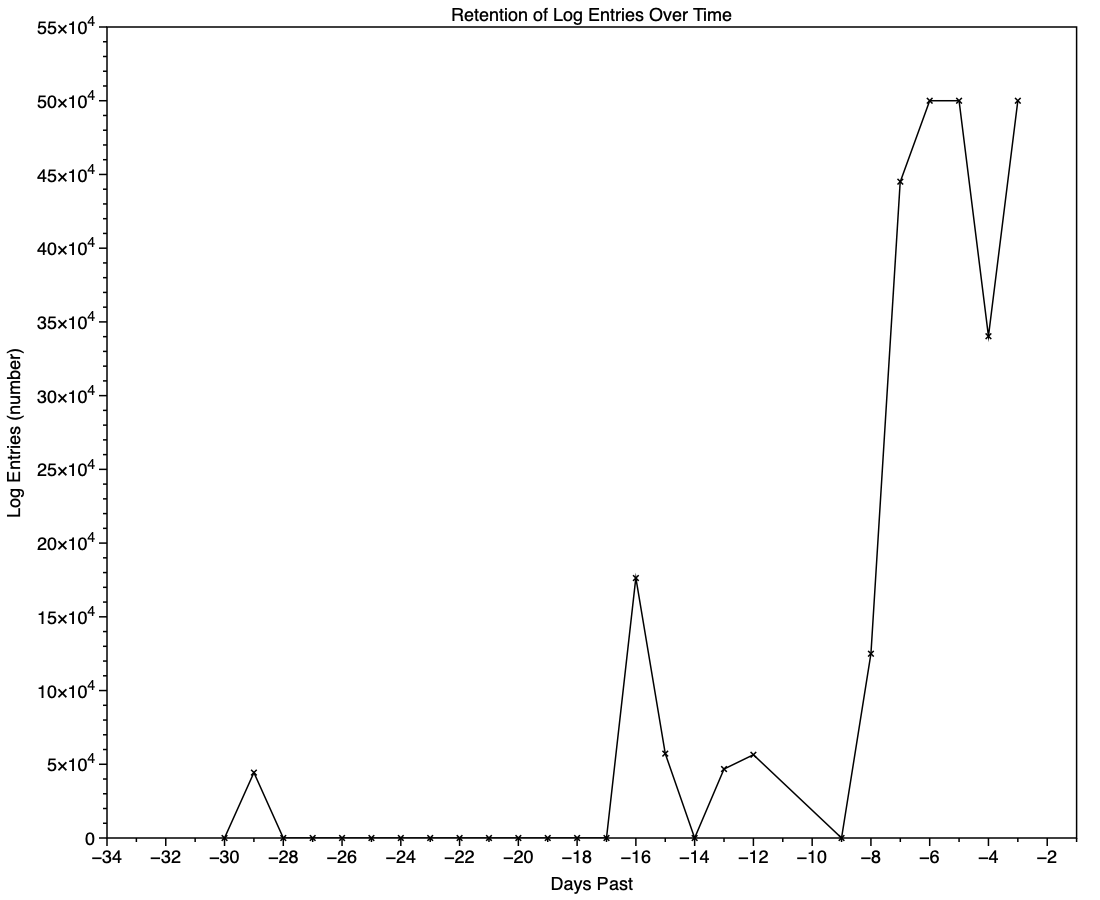
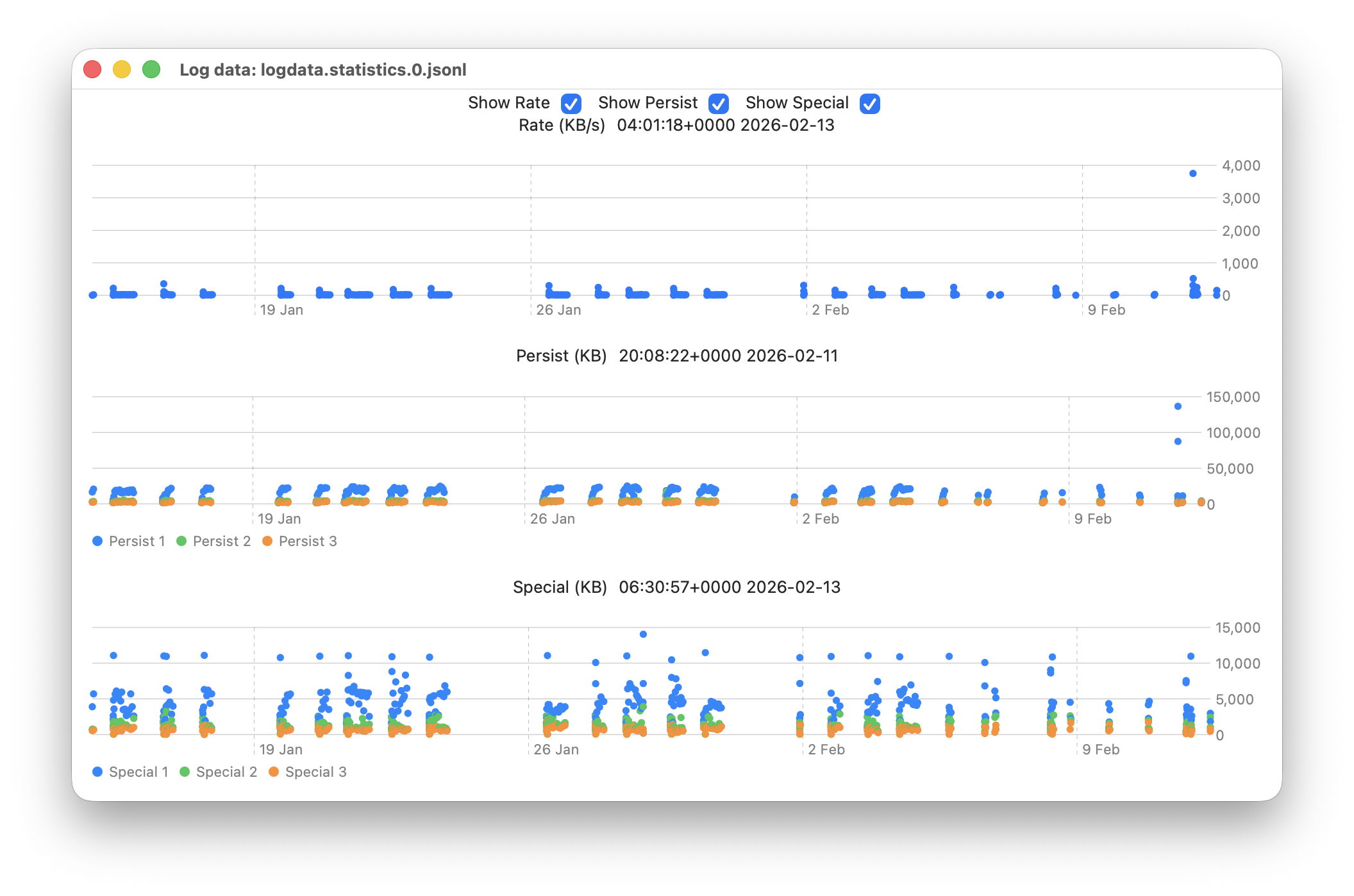
This chart shows the numbers of log entries that could be found and read at intervals over previous days. Where a total of 500,000 is shown, that means over 500,000 for that 24 hour period. I checked these using two different methods of access, using the OSLog API in LogUI, and via the log show command in Ulbow. In all cases, log show returned slightly fewer than OSLog.
It’s clear that with only 3 days of full Persist log files, very few entries have been retained from earlier than 7 days ago, and beyond that retention numbers are erratic.
Over the period prior to the oldest Persist file, when entries could only be coming from Special log files, those included both regular and boundary types, and categories were diverse, including fault, error, notice and info, and weren’t confined to the first two of those categories. Most subsystems were represented, but very few entries were made by the kernel. There is thus no obvious pattern to the longer retention of entries in Special files.
Ephemeral entries
Log entries are initially written to memory, before logd writes most of them to permanent storage in tracev3 log files on disk.

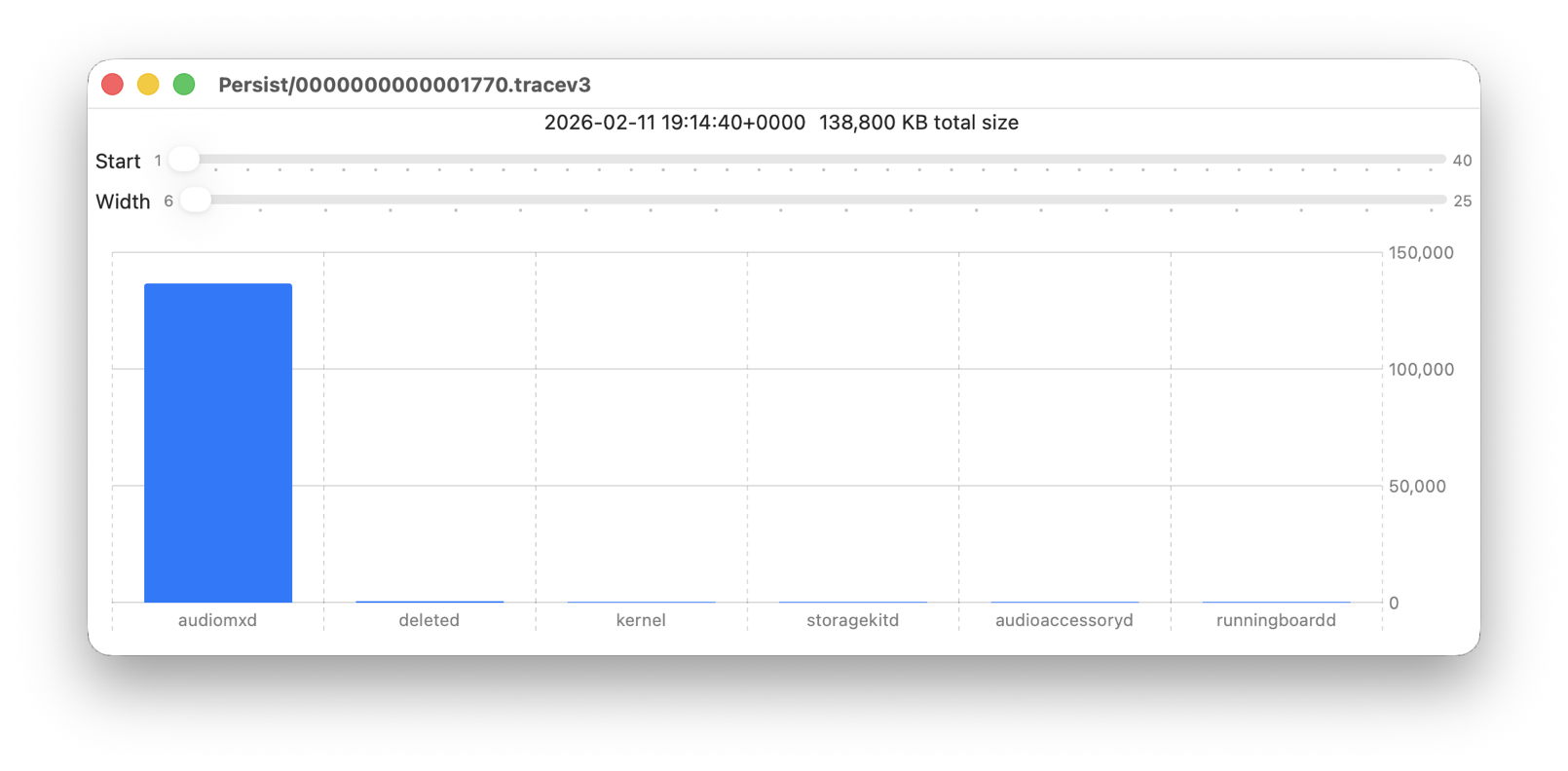
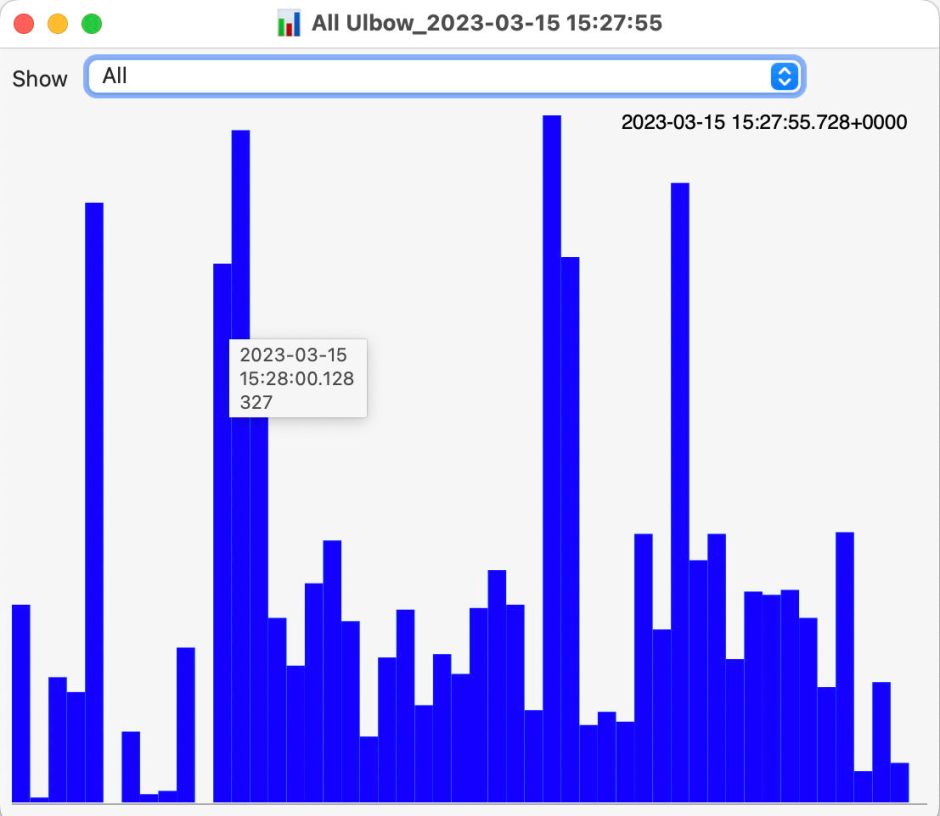
The first substantial purging of entries thus occurs when logd decides which are ephemeral and won’t be retained on disk. This can be seen by following the number of entries in a short period of high activity in the log, over time, and is shown in the chart below for a sample period of 3 seconds.

When fetched from the log within a minute of the entries being written, a total of 22,783 entries were recovered. Five minutes later there were only 82% of those remaining. Attrition of entries then continued more slowly, leaving 80% after 8 hours. Analysis suggests that over this period in which there were about 6,100 log entries per second written to disk, approximately 1,700 log entries per second were only kept in memory and never written to disk. That suggests about 22% were ephemeral, a proportion that’s likely to vary according to the origin and nature of log entries.
Summary
- A fifth of log entries are likely to be ephemeral, and lost from the log within the first minutes after they’re written.
- Most retained log entries are written in Persist logs, where tracev3 files are removed by age to keep their total size to just over 500 MB. Those should preserve the bulk of log entries for hours or days after they’re written.
- Entries stored in Special log files may be retained for significantly longer, here up to a maximum of 29 days. Although those may contain fault and error categories, retention doesn’t follow an obvious pattern, making their period of retention impossible to predict.
- In practice, the period in which a fairly complete log record can be expected is that applied to Persist files, which varies according to the rate of writing log entries. In most cases now that’s unlikely to be longer than 5 days, and could be less than 12 hours.
- You can’t draw conclusions from the apparent absence of certain log entries from the log prior to the earliest entries in Persist log files, as it’s likely that those entries will have been removed.
- Expecting to retrieve log entries from earlier than 5 days ago is almost certain to fail.