Young Folks Help English Grow Up
The language is benefiting from a respect for diversity.
One of the Mac’s great attractions has been its support for those whose first language isn’t English. That means many of you, as WordPress tells me that you speak German, Dutch, Chinese, Spanish, French, Italian, Japanese, Polish, Swedish, and more, although perhaps not all at once. While English is great as a lingua franca, our mother tongue is our culture and our literary tradition, and a multilingual world is far richer for all our languages.
What you may not realise is the deep support for your languages in macOS. I’m not here referring to Language & Region settings, or translation support, but to the features in the Natural Language framework, introduced in macOS 10.14. It provides support for apps to analyse text in many different natural languages and do useful things with those analyses. These days, that not only includes support provided by Apple, but enables apps to deploy custom natural language models using Machine Learning, or AI if you prefer the term.
AI seems a particular problem for non-English languages at present. In the headlong rush to be first with the most powerful Large Language Model, an industry dominated by monolingual US corporations has focussed its efforts almost entirely on English. Although most of the leading LLMs are claimed to be multilingual, and some include over 50 languages, their models are in reality overwhelmingly built on English, with less than 10% representing all other languages. And that small minority breaks down to even less when you consider individual languages: even major European languages like Italian barely get a look-in.
I’d be interested to hear of your experience accessing LLMs using non-English languages.
This is an area that Apple’s enthusiastic support for smaller, local models could make them more useful than hugely expensive LLMs built in all those US-run data centres.
When the Natural Language framework was first released for macOS, I built an app to demonstrate some of its powers, Nalaprop, and its current version still runs happily in Tahoe. Although it remains useful for some, I feel the time has come to make better use of this framework, or let Nalaprop slip away quietly with the arrival of macOS 27 this autumn/fall. Let me explain what it currently does.
Nalaprop relies on linguistic support modules loaded into macOS. As far as I can tell at present, those provide full support for English, French, Spanish, German, Italian, Portuguese, Russian and Turkish. It can also recognise many other languages, but support for those doesn’t extend to analysing them more fully.
Load your Mac up with a good selection of those, some you’d like it to aspire to, and give it an hour or so to download and install additional language support. Then open Nalaprop’s bundled demonstration text file drawn from Wikipedia’s many languages.
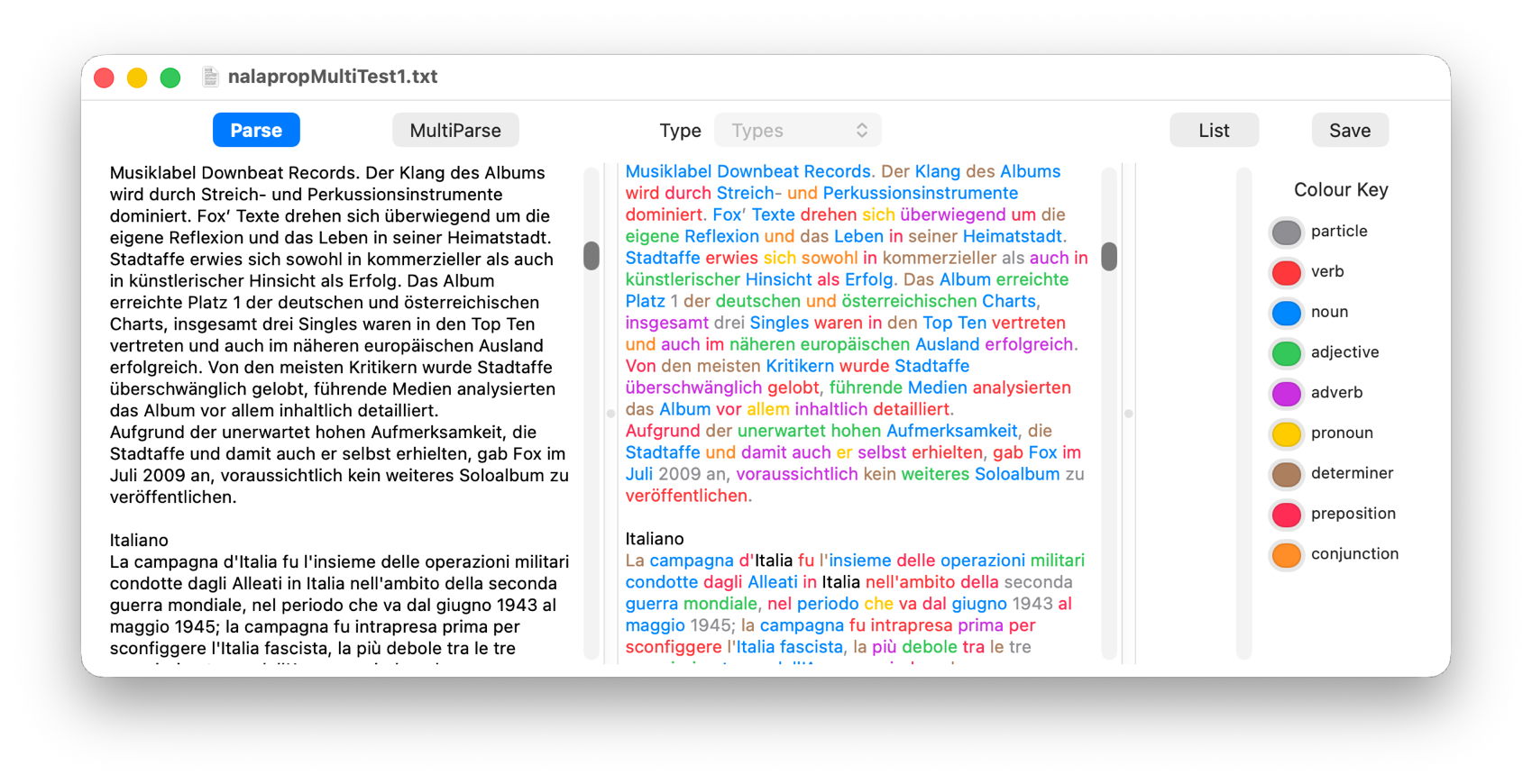
It then analyses the text (on the left) for the common parts of speech, such as nouns, verbs, adjectives, and colours all the words according to that classification (in the centre). As you can see here, it’s not afraid to do this on texts containing multiple languages, and appears to make a good job of all those its supports.
The next stage is initiated by clicking on the MultiParse button, which performs an even more thorough analysis, including lemmas, converting words into their ‘root’ form. For example, the English word is is a form of the verb to be, just as the French est is of être, so Nalaprop displays that root form of the word in the centre panel. As you can see, this doesn’t do much for English, which doesn’t decline words much, but for many languages it can be a great help when you’re trying to understand them.
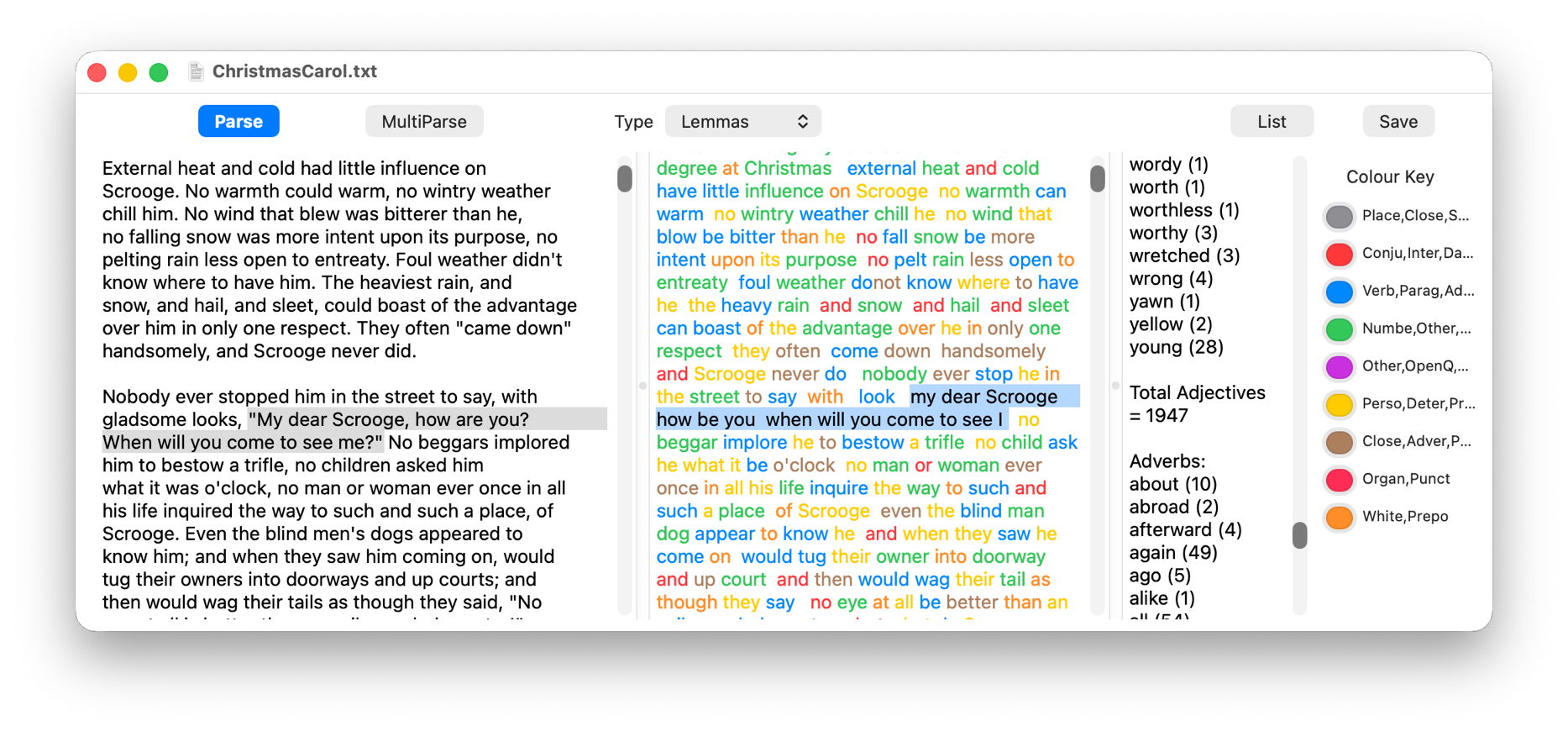
Given all those lemmatised forms, Nalaprop can then build word lists by parts of speech, classifying the word young as an adjective, and finding a total of 28 examples (on the right) in the text of Charles Dickens’ novella A Christmas Carol.
Since I wrote Nalaprop, the Natural Language framework has extended its capabilities, and there’s a great deal more that the app could do, even down to building gazetteers of place-names, exploring similarities between words and sentences using semantic distance, and of course integrating AI built into macOS.
Nalaprop is available from its Product Page.
Should I put it into retirement, or do something more useful with it, and if so, what would you find most useful?
看《波斯语课》,犹太人阴错阳差,靠着教德国军官波斯语来活命,但他完全不会波斯语,于是硬编了一门语言出来,每天编出一些单词让德国人背,犹太人自己也拼命背,忽悠了两年都没穿帮。
这听起来不太可能,当然电影里也做了很多铺垫,譬如犹太人声称自己也不懂读写,只是单纯教口语。在那个信息不流畅的时代,人们对如何学习一门外语的认知,也和我们如今相差甚远。总之,这只是电影里的设定,借此体验剧情就好。
电影的情节,让我想起萨苏说过一个段子:抗战时期的冀中八路军,冒充日本兵去刺探情报,他们只是跟着亲中的日本人学了一阵子口语,就能练到,让日本人听不出是 “外国人在说日语” 的程度。
你们现代人学不好外语,就是少挣俩钱儿。我们学不好的,都牺牲了。
萨苏《尊严不是无代价的》
想象如果换作是我,或者,如果是几个我脑中浮现出的,日常就有压力和情绪状况的朋友,面对这样的情境,这种一旦露馅就会死的巨大压力,能不能蒙混搞定?
大概有人真的会直接选择死亡吧?相比之下,虽然我也焦虑,但默认的思考方向,仍然是先去试试,再大不了一死。虽然自认是语言天赋很糟糕的人,但也存在着微小概率,拼命学外语,然后蒙混过关?——某种意义上,我觉得自己并不是因为面对压力而焕发了斗志,而是,没有经历过这种必须拿命学外语的样子,作为一种体验,有些好奇?
从文化决定论的角度,这些不同的状态,和环境、和文化,有很大的关系。但究竟有多大的关系?古代和如今的环境,对人的影响到底差异在哪里?我并不清楚。甚至,这样的人的比例,古今是否真的不同,现在是否变得更多,我也不清楚。也许他们之前只是没有显现。
以及,我第一次意识到「有的人会在面对巨大生存压力时,直接选择去死」这件事,大概是《大逃杀》里,那几个直接跳崖的学生。
之前聊到,日文、藏文的语序结构,和我们习惯的中文、英文不同,是谓语动词放在句子最后的「主语-宾语-谓语」的形式。
:(吐槽)所以人们常说的,日本人懂礼貌,会听人把话说完。其实是因为这样的结构,需要认真听到最后一个词,才知道整个句子要说「是」或「不是」啊。
:对于需要使用不同敬语的日本人,也方便他们先把宾语对象列出来,再根据其身份,决定用什么样的敬语去修饰动词。
另一个 blog 有时候写得少的原因,大概是在「文章是在写给谁?」这方面,无意识地发生了混乱。
除去一部分
的篇目;其它很多文章,应该是(有意识或无意识地)有一个,潜在的写作对象的。他可能是
于是,经常写到一半,突然意识到这个对象的存在,然后陷入「我这样写,有什么意义吗」的沮丧,也就不写了。
又或者,吐槽吐到一半,突然意识到,我所吐槽的特质,其实和来看 blog 的人,并不相关。于是反而担心,会不会让读者们对号入座产生误解,或者觉得我这个对空掰扯道理的样子很爹味儿之类的。
——就像在「主-宾-谓」的句子里,谓语写一半了,才意识到,那个预设的宾语的存在。
