使用两家服务商会增加配置难度,但可以提高 DNS 服务的稳定性。如最近的 DNSPod 宕机以及 2016 年的 Dyn 宕机所导致的众多网站无法访问,均是因为众多网站仅使用了一家 DNS 提供商。如果使用了多家 DNS 提供商,则网站仅会在所使用的所有服务商均发生宕机事故时才会无法访问,而这显然发生概率很小。
国外请求测试地址,其中的 via 字段就是 Cloudflare 与本站建立的连接的 IP 地址。通过 GeoIP 服务查询,发现是香港的 IP。Cloudflare 将自己的节点之间都建立了长连接,并在离源站最近的服务器上与源站也提前建立了连接。这样,就能大大降低首次连接所需要的时间。如果回源是 HTTPS 的,那么效果更明显。我的另一个测试地址是没有开启这个功能的,用来对比,它的回源与本站建立的 IP 就不是香港的。
域名相关:不管你是选择使用虚拟主机、VPS 或是独立服务器,通常你还需要自己买一个域名,配置 DNS 解析等等,推荐免费的 DNS 解析有 CloudFlare、Rage4,国内还有 CloudXNS,一些虚拟主机商以及域名注册商也提供免费的解析,但不如前面介绍的那几个(详细关于 DNS 的介绍请见此)。如果选择使用 CloudFlare,那么你还可以在 DNS 后台选择开启 Proxy(CDN),这样能为你的网站缓存并加速(但实际上对于国内来说有可能反而减速),并获得一些基础的 DDOS 防护,并隐藏你的源站 IP 地址。
整个 DNS 具有复杂的层次,这对刚开始购买域名的人有很大的疑惑。本文将详尽的介绍 DNS 的工作原理,有助于更深刻的理解。本文将介绍:
在客户端上是如何解析一个域名的
在 DNS 缓存服务器上是如何逐级解析一个域名的
同时还包含:
域名的分类
什么是 Glue 记录
为什么 CNAME 不能设置在主域名上
先从本地的 DNS 开始讲起。
本地 DNS
本地的 DNS 相对于全球 DNS 要简单的多。所以先从本地 DNS 开始讲起。 127.0.0.1 常被用作环回 IP,也就可以作为本机用来访问自身的 IP 地址。通常,这个 IP 地址都对应着一个域名,叫 localhost。这是一个一级域名(也是顶级域名),所以和 com 同级。系统是如何实现将 localhost 对应到 127.0.0.1 的呢?其实就是通过 DNS。在操作系统中,通常存在一个 hosts 文件,这个文件定义了一组域名到 IP 的映射。常见的 hosts 文件内容如下:
1 2
127.0.0.1 localhost ::1 localhost
它就定义了 localhost 域名对应 127.0.0.1 这个 IP(第二行是 IPv6 地址)。这样,当你从浏览器里访问这个域名,或者是在终端中执行 Ping 的时候,会自动的查询这个 hosts 文件,就从文件中得到了这个 IP 地址。此外,hosts 文件还可以控制其他域名所对应的 IP 地址,并可以 override 其在全球 DNS 或本地网络 DNS 中的值。但是,hosts 文件只能控制本地的域名解析。hosts 文件出现的时候,还没有 DNS,但它可以说是 DNS 的前身。 如果需要在一个网络中,公用同一个 DNS,那么就需要使用 IP 数据包向某个服务器去获取 DNS 记录。 在一个网络里(此处主要指本地的网络,比如家庭里一个路由器下连接的所有设备和这个路由器组成的网络),会有很多主机。在与这些主机通信的时候,使用域名会更加的方便。通常,连接到同一个路由器的设备会被设置到路由器自己的一个 DNS 服务器上。这样,解析域名就不仅可以从 hosts 去获取,还可以从这个服务器上去获取。从另一个 IP 上去获取 DNS 记录通过 DNS 查询,DNS 查询通常基于 UDP 或者 TCP 这种 IP 数据包,来实现远程的查询。我的个人电脑的网络配置如下,这是在我的电脑连接了路由器之后自动就设置上的:
重点是在路由器和搜索域上。 我的电脑的主机名(也是电脑名)设置的是 ze3kr,这个内容在连接路由器时也被路由器知道了,于是路由器就给我的主机分配了一个域名 ze3kr.local,local 这个一级域名专门供本地使用。在这个网络内所有主机通过访问 ze3kr.local 这个域名时,路由器(10.0.1.1)就会告知这个域名对应的 IP 地址,于是这些主机够获得到我的电脑的 IP 地址。至于搜索域的作用,其实是可以省去输入完整的域名,比如:
1 2 3 4 5 6
$ ping ze3kr PING ze3kr.local (10.0.1.201): 56 data bytes 64 bytes from 10.0.1.201: icmp_seq=0 ttl=64 time=0.053 ms --- ze3kr.local ping statistics --- 1 packets transmitted, 1 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 0.053/0.053/0.053/0.000 ms
当设置了搜索域时,当你去解析 ze3kr 这个一级域名时,便会先尝试去解析 ze3kr.local,当发现 ze3kr.local 存在对应的解析时,便停止进一步解析,直接使用 ze3kr.local 的地址。 现在你已经了解了本地 DNS 的工作方式。DNS 的基本工作方式就是:获取域名对应 IP,然后与这个 IP 进行通信。 当在本地去获取一个完整域名(FQDN)时(执行 getaddrbyhost),通常也是通过路由器自己提供的 DNS 进行解析的。当路由器收到一个完整域名请求且没有缓存时,会继续向下一级缓存 DNS 服务器(例如运营商提供的,或者是组织提供的,如 8.8.8.8)查询,下一级缓存 DNS 服务器也没有缓存时,就会通过全球 DNS 进行查询。具体的查询方式,在 “全球 DNS” 中有所介绍。
总结
在本地,先读取本地缓存查找记录,再读取 Hosts 文件,然后在搜索域中查找域名,最后再向路由器请求 DNS 记录。
全球 DNS
在全球 DNS 中,一个完整域名通常包含多级,比如 example.com. 就是个二级域名, www.example.com. 就是个三级域名。通常我们常见到的域名都是完整的域名。
先从根域名开始,未命名根也可以作为 . 。你在接下来的部分所看到的很多域名都以 .结尾,以 .结尾的域名是特指的是根域名下的完整域名,然而不以 . 结尾的域名大都也是完整域名,实际使用时域名末尾的 .也常常省略。在本文中,我使用 dig 这一个常用的 DNS 软件来进行查询,我的电脑也已经连接到了互联网。 假设目前这个计算机能与互联网上的 IP 通信,但是完全没有 DNS 服务器。此时你需要知道根 DNS 服务器,以便自己获取某个域名的 IP 地址。根 DNS 服务器列表可以在这里下载到。文件内容如下:
其中,可以看到 TTL 与刚才文件中的内容不一样,此外还多了一个 SOA 记录,所以实际上是以这里的结果为准。这里还有一个 SOA 记录,SOA 记录是普遍存在的,具体请参考文档,在这里不做过多说明。
SOA 记录:指定有关 _DNS 区域_的权威性信息,包含主要名称服务器、域名管理员的电邮地址、域名的流水式编号、和几个有关刷新区域的定时器。(RFC 1035)
DNS 区域:对于根域名来说,DNS 区域就是空的,也就是说它负责这互联网下所有的域名。而对于我的网站,DNS 区域就是 guozeyu.com.,管理着 guozeyu.com. 本身及其子域名的记录。
此处的 ADDITIONAL SECTION 其实就包含了 Glue 记录。
一级域名
根域名自身的 DNS 服务器服务器除了被用于解析根自身之外,还用于解析所有在互联网上的一级域名。你会发现,几乎所有的 DNS 服务器,无论是否是根 DNS 服务器,都会解析其自身以及其下级域名。 从之前的解析结果中可以看出,根域名没有指定到任何 IP 地址,但是却给出了 NS 记录,于是我们就需要用这些 NS 记录来解析其下级的一级域名。下面,用所得到的根 NS 记录中的服务器其中之一来解析一个一级域名 com.。
可以看到,使用 host 命令获得 IP 地址的域名与使用 dig 获取的相同,均为 99.138.199.104.bc.googleusercontent.com. 。可以看出,这个 IP 是属于 Google 的。此外,需要注意的是 in-addr.arpa. 下的字域名正好与原 IPv4 地址排列相反。 这个记录通常可以由 IP 的所有者进行设置。然而,IP 的所有者可以将这项记录设置为任何域名,包括别人的域名。所以通过这种方法所判断其属于 Google 并不准确,所以,我们还需要对其验证:
1 2
$ dig 99.138.199.104.bc.googleusercontent.com a +short 104.199.138.99
GCE 虽然是提供独立 IP 的,但是当你执行 ifconfig -a 时,你会看到默认分配的 IP 是一个内网的保留 IP(形如 10.123.0.1),这是为了方便 instance 里之间互相连接的 IP。当你配置一些需要外网的服务要 bind 到指定 IP 时,你只需要 bind 到这个 IP 即可,所分配给你的外网 IP 会自动将流量转发到这个 IP 上。而且,你的主机并不知道那个外网 IP 就是主机本身,所以所有发向主机对应的外网 IP 的流量都会经过一个路由器,然后再由路由器返回,并且会应用防火墙策略。所以,如果需要本地的通讯,建议尽量多使用环回地址(如 127.0.0.1,::1)或那个内网地址。
防火墙
不能关闭的防火墙对于初次接触的人来说可能有些不适,不过一旦习惯后便会爱上这个功能,这个基于在路由器上的防火墙功能要比在 iptables 里做限制更方便。强烈建议利用好防火墙功能,不要默认允许所有端口。比如你的网站流量全部经过 Cloudflare,那么就可以通过防火墙来只允许 Cloudflare 的 IP 与你的主机连接。
使用全站 CDN,可以免去在自己的服务器上配置缓存的问题,还可以为服务器增加 HTTPS、HTTP/2 等功能,同时还能过滤非法流量,防御 DDOS(前提是你的 IP 没有被暴露,或者你设置好了白名单)。 除此之外,使用 CDN 后还能更加明显的提高网站加载速度,让访客从中受益。
使用 CloudFlare
CloudFlare 是可以免费使用的,使用 CloudFlare 前需要更改 DNS 服务商,然后无需额外配置就能使用了。但是它只会缓存 CSS、JS 和多媒体文件,不会缓存 HTML 页面,也就是说用户每次访问时还是会返回到原始服务器,页面本身的速度不会有明显提高,在原始服务器上配置缓存也是必要的。
使用 KeyCDN 并配合插件
KeyCDN 是一个按流量使用付费的 CDN 提供商,使用我制作的插件 Full Site Cache for KeyCDN 可以简单的对其配置,这个插件会自动刷新缓存。 KeyCDN 相比 CloudFlare,可以缓存 HTML 页面,大大减少源服务器的压力,同时在刷新缓存时可以通过 Tag 方式刷新,避免不必要的刷新。 在网站访问量较大时,使用 KeyCDN 就能明显的提高速度,缓存命中率也会有很大的提高。
“OSI”的全称是“Open System Interconnection”。先说说它的历史。
上世纪70年代,“国际电信联盟”(ITU)想对各国的电信系统(电话/电报)建立标准化的规格;与此同时,“国际标准化组织”(ISO)想要建立某种统一的标准,使得不同公司制造的大型主机可以相互联网。
后来,这两个国际组织意识到:“电信系统互联”与“电脑主机互联”的性质差不多。于是 ISO 与 ITU 就决定合作,两家一起干。这2个组织的2套班子,从上世纪70年代开始搞,搞来搞去,搞了很多年,一直到1984年才终于正式发布 OSI 标准。
(前面说了)OSI 是由 ISO & ITU 联手搞出来滴。这两个国际组织里面的人,要么是来自各国的电信部门,要么是来自各国的高校学者。总而言之,既有严重的官僚风气,又有明显的学究风气。(正是因为这两种风气叠加,所以搞了很多年,才搞出 OSI)
OSI 的协议实现(OSI protocols),不客气地说,就是一堆垃圾——据说把 OSI protocols 所有的协议文档,全部打印成 A4 纸,摞起来得有一米多高!是不是很吓人?协议搞得如此复杂,严重违背了 IT 设计领域的 KISS 原则。
由于 OSI protocols 实在太复杂,后来基本没人用。但 OSI model 反而广为流传,并且成为“网络分层模型”中名气最大,影响力最广的一个。
因此,本文后续章节中,凡是提到 OSI,指的是【OSI model】。
◇OSI 模型的7层
OSI 模型总共分7层,示意图参见如下表格:
层次
中文名
洋文名
第7层
应用层
Application Layer
第6层
表示层
Presentation Layer
第5层
会话层
Session Layer
第4层
传输层
Transport Layer
第3层
网络层
Network Layer
第2层
数据链路层
Data Link Layer
第1层
物理层
Physical Layer
(注:为了打字省力,在后续章节把“数据链路层”直接称为“链路层”)
考虑到本文是针对一般性读者的【扫盲教程】,俺重点聊第1~4层。搞明白这几个层次之后,有助于你更好地理解网络的很多概念,也有助于你更好地理解很多信息安全的概念。
网上已经有很多关于 OSI 的文章,可惜大部分写得粗糙——很多文章只是在照抄定义。
俺曾经写过一篇《学习技术的三部曲:WHAT、HOW、WHY》,其中提到【理解技术】的不同层次。要想更好地理解 OSI 模型,你得搞明白:为啥需要引入某某层?(请注意:这是一个 WHY 型的问题)
接下来在讨论 OSI 的每个层次时,俺都会专门写一个小节,谈该层次的【必要性】。搞明白【必要性】,你就知道为啥要引入这个层次。
另外,很多同学应该都用过“USB hub”,就是针对 USB 线的“集线器”(“USB 线”也可以视作某种通讯介质)。
★链路层:概述
◇链路层的必要性
对信息的打包
物理层传输的信息,通俗地说就是【比特流】(也就是一长串比特)。但是对于计算机来说,“比特流”太低级啦,处理起来极不方便。“链路层”要干的第一个事情,就是把“比特流”打包成更大的一坨,以方便更上层的协议进行处理。在 OSI 模型中,链路层的一坨,称之为“帧”(frame)。
差错控制
物理介质的传输,可能受到环境的影响。这种影响不仅仅体现为“噪声”,有时候会出现严重的干扰,导致物理层传输的“比特流”出错(某个比特“从0变1”或“从1变0”)。因此,链路层还需要负责检查物理层的传输是否出错。在 IT 行话中,检测是否出错,称之为“差错控制机制”(后面有一个小节会简单说一下这个话题)。
“MAC 协议”用来确保对下层物理介质的使用,不会出现冲突。为了形象,俺拿“铁路系统”来比喻,说明“MAC 协议”的用途。
假设有一条【单轨】铁路连接 A/B 两地。有很多火车想从 A 开到 B,同时还有很多火车想从 B 开到 A。
首先,要确保不发生撞车(如果已经有车在 A 开往 B 的途中,那么 B 就不能再发车);其次,即使是同一个方向的车,出发时间也要错开一个时间间隔。
所有这些协调工作,都是靠“MAC 协议”来搞定。
如何保证 MAC 地址全球唯一捏?简单说一下:
MAC 地址包含6个字节(48个比特),分为两半。第一部分称作【OUI】,OUI 的24个比特中,其中2个比特有特殊含义,其它22个比特,用来作为网卡厂商的唯一编号。这个编号由国际组织 IEEE 统一分配。
MAC 地址第二部分的24比特,由网卡厂商自己决定如何分配。每个厂商只要确保自己生产的网卡,后面这24比特是唯一的,就行啦。
(MAC 地址的构成)
由于俺在很多安全教程中鼓吹大伙儿使用“操作系统虚拟机”,再顺便说说【虚拟网卡】的 MAC 地址。
“虚拟网卡”是由【虚拟化软件】创建滴。IEEE 也给每个虚拟化软件的厂商(含开源社区)分配了唯一的 OUI。因此,虚拟化软件在创建“虚拟网卡”时,会使用自己的 OUI 生成前面24个比特;后面的24比特,会采用某种算法使之尽可能【随机化】。由于“2的24次方”很大(224 = 16777216),碰巧一样的概率很低。
(注:如果手工修改 MAC 地址,故意把两块网卡的 MAC 地址搞成一样,那确实就做不到唯一性了。并且会导致链路层的通讯出问题)
网络交换机(network switch)
(注:一般提到“网络交换机”,如果不加定语,指的就是“2层交换机”;此外还有更高层的交换机,在后续章节介绍)
为啥要有交换机捏?俺拿“以太网的发展史”来说事儿。
以太网刚诞生的时候,称之为“经典以太网”,电脑是通过【集线器】相连。“集线器”前面提到过,工作在【1层】(物理层),并不理解链路层的协议。因此,集线器的原理是【广播】模式——它从某个网线接口收到的数据,会复制 N 份,发送到其它【每个】网线接口。假设有4台电脑(A、B、C、D)都连在集线器上,A 发数据给 B,其实 C & D 也都收到 A 发出的数据。显然,这种工作模式很傻逼(低效)。由于“经典以太网”的工作模式才“10兆”,所以集线器虽然低效,还能忍受。
后来要发展“百兆以太网”,再用这种傻逼的广播模式,就不能忍啦。于是“经典以太网”就发展为“交换式以太网”。用【交换机】代替“集线器”。
交换机是工作在2层(链路层)的设备,能够理解链路层协议。当交换机从某个网线接口收到一份数据(链路层的“帧”),它可以识别出“链路帧”里面包含的目标地址(接收方的 MAC 地址),然后只把这份数据转发给“目标 MAC 地址相关的网线接口”。
由于交换机能识别2层协议,它不光比集线器的性能高,而且功能也强得多。比如(稍微高级点的)交换机可以实现“MAC 地址过滤、VLAN、QoS”等多种额外功能。
网桥/桥接器(network bridge)
“交换机”通常用来连接【同一种】网络的设备。有时候,需要让两台不同网络类型的电脑相连,就会用到【网桥】。
下面以“操作系统虚拟机”来举例(完全没用过虚拟机的同学,请跳过这个举例)。
在这篇博文,俺介绍了虚拟机的几种“网卡模式”,其中有一种模式叫做【bridge 模式】。一旦设置了这种模式,Guest OS 的虚拟网卡,对于 Host OS 所在的外部网络,是【双向】可见滴。也就是说,物理主机所在的外部网络,也可以看见这块虚拟网卡。
现在,假设你的物理电脑(Host OS)只安装了【无线网卡】(WiFi),而虚拟化软件给 Guest OS 配置的通常是【以太网卡】。显然,这是两种【不同】的网络。为啥 Guest OS 的以太网卡设置为“bridge 模式”之后,外部 WiFi 网络可以看到它捏?
奥妙在于——虚拟化软件在内部悄悄地帮你实现了一个“网桥”。这个网桥把“Host OS 的 WiFi 网卡”与“Guest OS 的以太网卡”关联起来。WiFi 网卡收到了链路层数据之后,如果接收方的 MAC 地址对应的是 Guest OS,网桥会把这份数据丢给 Guest OS 的网卡。
这种网卡模式之所以称作“bridge 模式”,原因就在于此。
ARP 命令
首先,ARP 是“MAC 地址解析协议”的洋文名称。该协议根据“IP 地址”解析“MAC 地址”。
Windows 自带一个同名的 arp 命令,可以用来诊断与“MAC 地址”相关的信息。比如:列出当前子网中其它主机的 IP 地址以及对应的 MAC 地址。这个命令在 Linux & Mac OS 上也有。
★网络层:概述
◇网络层的必要性
路由机制(routing)
在 OSI 模型中,链路层本身【不】提供路由功能。你可以通俗地理解为:链路层只处理【直接相连】的两个端点(注:这么说不完全严密,只是帮助外行理解)
对于某个复杂网络,可能有很多端点,有很复杂的拓扑结构。当拓扑足够复杂,总有一些端点之间【没有直连】。那么,如何在这些【没有直连】的端点之间建立通讯捏?此时就需要提供某种机制,让其它端点帮忙转发数据。这就需要引入“路由机制”。
为了避免把“链路层”搞得太复杂,路由机制放到“链路层”之上来实现,也就是“网络层”。
在上世纪50年代(冷战高峰期),美国军方的指挥系统高度依赖于电信公司提供的电话网络。当时的电话网络大致如下——
在基层,每个地区有电话交换局,每一部电话都连入当地的交换局。
在全国,设有若干个长途局,每个交换局都接入某个特定的长途局(不同地区的交换局通过长途局中转)。
简而言之,当时美国的电话网络是典型的【多级星形拓扑】。这种拓扑的优点是:简单、高效、便于管理;但缺点是:健壮性很差。从这个案例中,大伙儿可以再次体会到“效率”与“健壮性”之间的矛盾。俺写过一篇很重要的博文(这里)深入讨论了这个话题。
话说1957年的时候,苏联成功试射第一颗洲际弹道导弹(ICBM),美国军方开始担心:一旦苏联先用洲际导弹攻击美国,只要把少数几个长途局轰掉,军方的指挥系统就会瘫痪。也就是说,“长途局”已经成为美国军方的【单点故障】(何为“单点故障”?参见这篇博文)。
1960年,美国国防部找来大名鼎鼎的兰德公司进行咨询,要求提供一个应对核打击的方案。该公司的研究员 Paul Baran 设计了一个方案,把“星形拓扑”改为【网状拓扑】。采用【网状拓扑】的好处在于:即使发生全面核大战,大量骨干节点被摧毁,整个网络也不会被分隔成几个孤岛,军方的指挥系统依然能正常运作。
聊完“拓扑”,再来聊“路由”。
当主机 A 向主机 B 发送网络层的数据时,大致会经历如下步骤:
1.
A 主机的协议栈先判断“A B 两个地址”是否在同一个子网(“子网掩码”就是用来干这事儿滴)。
如果是同一个子网,直接发给对方;如果不是同一个子网,发给本子网的【默认网关】。
(此处所说的“网关”指“3层网关/网络层网关”)
2.
对于“默认网关”,有可能自己就是路由器;也可能自己不是路由器,但与其它路由器相连。
也就是说,“默认网关”要么自己对数据包进行路由,要么丢给能进行路由的另一台设备。
(万一找不到能路由的设备,这个数据就被丢弃,于是网络通讯出错)
3.
当数据到达某个路由器之后,有如下几种可能——
3.1
该路由器正好是 B 所在子网的网关(与 B 直连),那就把数据包丢给 B,路由过程就结束啦;
3.2
亦或者,路由器会把数据包丢给另一个路由器(另一个路由器再丢给另一个路由器) ...... 如此循环往复,最终到达目的地 B。
3.3
还存在一种可能性:始终找不到“主机 B”(有可能该主机“断线 or 关机 or 根本不存在”)。为了避免数据包长时间在网络上闲逛,还需要引入某种【数据包存活机制】(洋文叫做“Time To Live”,简称 TTL)。
通常会采用某个整数(TTL 计数)表示数据包能活多久。当主机 A 发出这个数据包的时候,这个“TTL 计数”就已经设置好了。每当这个数据包被路由器转发一次,“TTL 记数”就减一。当 TTL 变为零,这个数据包就死了(被丢弃)。
对于某些大型的复杂网络(比如互联网),每个路由器可能与其它 N 个路由器相连(N 可能很大)。对于上述的 3.2 情形,它如何判断:该转发给谁捏?
这时候,“路由算法”就体现出价值啦——
一般来说,路由器内部会维护一张【路由表】。每当收到一个网络层的数据包,先取出数据包中的【目标地址】,然后去查这张路由表,看谁距离目标最近,就把数据包转发给谁。
上面这段话看起来好像很简单,其实路由算法挺复杂滴。考虑到本文是“扫盲性质”,而且篇幅已经很长,不可能再去聊“路由算法”的细节。对此感兴趣的同学,可以去看《计算机网络》的第5章。
◇路由算法的演变史(以互联网为例)
(技术菜鸟可以跳过这个小节)
由于互联网的 IP 协议已经成为“网络层协议”的事实标准,俺简单聊一下互联网的路由机制是如何进化滴。
(技术菜鸟可以跳过这个小节)
前面聊“互联网诞生”,说到兰德公司的“Baran 方案”。该方案对当时的电信系统提出几大革命性的变化,其中之一就是“分组交换”技术(也称“数据包交换”or“封包交换”)。
一般来说,网络层的设计有两种截然不同的风格:【电路交换 VS 分组交换】。有时候也分别称之为“有连接的网络层 VS 无连接的网络层”。此处所说的“连接”指的是某种“虚电路”(洋文叫做“virtual circuit”,简称 VC)。
当时的电话系统主要承载语音传输,“电路交换”显然性能更高。那为啥 Baran 的设计要采用“分组交换”捏?俺又要再次提到【效率 VS 健壮性】之间的矛盾与均衡。
对于“电路交换”,一旦建立连接,同一个连接的所有数据都走相同的路径(会经过完全相同的路由器)。也就是说,传输的过程中,如果某个路由器挂掉了(网络掉线 or 硬件当机 or 软件崩溃)。那么,该路由器正在处理的 N 个连接全都要报废。而“分组交换”则更加灵活——即使某个路由器挂掉了,后续的数据包会自动转向另外的路由器,损失很小。
“Baran 方案”之所以采用“分组交换”的设计,因为人家这个方案是提交给军方用来应对【全面核战争】滴,当然要考虑健壮性啦。
话说这两种交换机制,各有很多支持者,并分裂为两大阵营,分别是:“电信阵营 VS 互联网阵营”。两大阵营的口水战持续了 N 年,都无法说服对方。到了后来设计 OSI 模型的时候,为了保持中立性与通用性,OSI 模型本身并没有强制要求网络层采用哪一种风格。
经过几十年之后,咱们已经可以看出来:“互联网阵营”占据主导地位。如今,连电信系统都是架构在互联网之上。
★网络层:具体实例
◇网络层的【协议】
网络层的协议有很多。由于“互联网”已经成为全球的事实标准,因此俺只列出属于“互联网协议族”的那些“网络层协议”:
IP 协议(含 IPv4 & IPv6) ICMP IGMP IPSec
......
(考虑到篇幅)俺不可能具体细聊这些协议,只是贴出每个的维基百科链接,感兴趣的同学自己点进去看。
对上述这些协议,最重要的当然是 IP 协议。如果你想要深入了解 IP 协议,可以参考如下这本书。关于 IP 协议的书,此书的影响力最大。这本书共3卷,通常只需看第1卷。
《TCP-IP 详解》
当年设计阿帕网的时候,采用了【4字节】(32比特)来表示“网络层地址”(也就是 IP 地址)。
“IP 地址”的含义很重要,俺有必要解释一下:
咱们平时所说的 IP 地址,采用【点分十进制】来表示。就是把地址的4个字节,先翻译为十进制,然后每个字节用一个小数点分隔开(参见如下示意图):
(4字节 IP 地址:“二进制”与“点分十进制”的对照示意图)
“IP 地址”的32比特,分为两部分:第1部分用来标识【子网】,第2部分用来标识该子网中的【主机】。
这两部分各占用多少比特,是不确定的。在这种情况下,“操作系统协议栈”如何知道哪些比特标识“子网”,哪些比特标识“主机”捏?奥妙在于【子网掩码】。所以,大伙儿在给系统配置 IP 地址的时候,通常都需要再设置一个【子网掩码】,就这个用途。
这个 IP 地址对应的主机已经关机
这个 IP 地址对应的主机已经断线
这个 IP 地址对应的主机拒绝响应 ICMP 协议
从你本机到这个 IP 地址之间,有某个防火墙拦截了 ICMP 协议
......
traceroute
这是一个通用的工具,用来测试路由。很早以前的 Windows 就已经内置了它,命令是 tracert。在 POSIX(Linux&UNIX)上通常叫 traceroute
你可以用这个命令,测试你本机与互联网另一台主机之间的路由(也就是:从你本机到对方主机,要经过哪些路由器)
★传输层:概述
◇传输层的必要性
屏蔽“有连接 or 无连接”的差异
(上一个章节提到)网络层本身已经屏蔽了【异种网络】的差异(比如“以太网、ATM、帧中继”之间的差异),而且网络层也屏蔽了路由的细节。但网络层本身还有一个差异,也就是网络层的两种交换技术:电路交换(有连接) VS 分组交换(无连接)。
前面章节也提到了:上述两种交换技术各有很多支持者,并分裂为两大阵营。当年设计 OSI 模型的时候,为了保持中立性与通用性,并没有强制规定“网络层”必须采用何种交换机制。
对于开发网络软件的程序员来说,当然不想操心“网络层用的是哪一种交换机制”。因此,需要对网络层的上述差异再加一个抽象层(也就是“传输层”)。
在 OSI 7层模型中,传输层正好居中。这是一个很特殊的位置。
OSI 模型最下面3层,与【网络设备】比较密切。这里面所说的“网络设备”,既包括那些独立的主机(比如“路由器、交换机、等”),也包括电脑上的硬件(比如“网卡”)。
OSI 模型最上面3层,与【网络软件】比较密切(或者说,与“用户的业务逻辑”比较密切)。
而中间的传输层,正好是承上启下。对于开发应用软件的程序猿/程序媛,“传输层”是他们能感知的最低一层。
◇传输层的【端口】
刚才谈“传输层的必要性”,提到说——“网络层地址”只能标识【主机】,而传输层必须要能标识【进程】。为了达到这个目的,于是就引入了“传输层端口”这个概念(为了打字省力,后续讨论简称为“端口”)。
在 OSI 模型中,“端口”的官方称呼是“传输服务访问点”(洋文缩写 TSAP)。但是作为程序员,俺已经习惯于“端口”这个称呼。后续介绍依然用“端口”一词。
当程序员使用传输层提供的 API 开发网络软件时,通常把“端口”与“网络地址”一起使用(构成“二元组”),就可以定位到某个主机上的某个进程。
一不小心,这篇教程已经写了这么长。为了照顾那些有“阅读障碍”的读者,俺要稍微控制一下篇幅,就把 OSI 的【上三层】合在一起讨论。
前面的章节说过:【上三层】更接近于“网络软件”,对应的是应用软件的业务逻辑,因此俺统称为“业务层”。
注:有些书(比如《计算机网络》)会把 OSI 的上三层统称为“应用层”。由于 OSI 模型中本来就有一个“应用层”,俺认为这样容易搞混(尤其不利于技术菜鸟),所以另外起了一个“业务层”的名称。
对于大部分读者来说,【没必要】花时间去了解 OSI 最上面三层之间的区别。你只需把最上面三层视作【一坨】——他们都是与网络软件的业务逻辑密切相关滴。
那么,哪些人需要详细了解“这三层的差异”捏?
如果你是个程序员,并且你正好是开发【网络】软件,俺建议你了解一下 OSI 模型的最上面三层,有助于你更深刻地思考某些网络协议的设计。所谓的“更深刻”指的是:你不能光停留在 WHAT 层面,要提升到 HOW 甚至 WHY 层面(参见《学习技术的三部曲:WHAT、HOW、WHY》)
前面的某些章节,已经稍微提及了“网关”这个概念,但还没有具体介绍它。
严格来讲,“网关”是一个逻辑概念,【不要】把它当成具体的网络设备。充当“网关”的东东,可能是:路由器 or XX层交换机 or XX层防火墙 or 代理服务器 ......
“网关”也分不同的层次。如果不加定语,通常指的是“3层网关”(网络层网关)。列几种比较常见的,供参考:
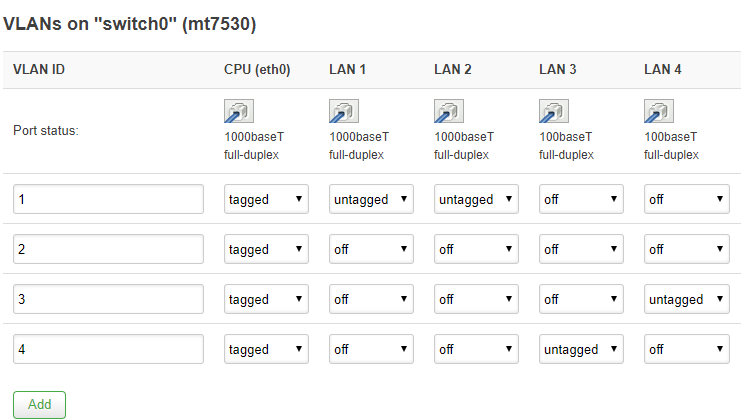
OpenWrt文档所提到的:An untagged port can have only 1 VLAN ID 反映在:OpenWrt中的Switch设置VLAN时单个untagged Port无法再再其他VLAN上为Untagged,否则回提示:LAN 1 is untagged in multiple VLANs!
Tagged on “CPU (eth0)” means that the two VLAN ID tags used in this example (1, 2) are sent to the router CPU “as tagged data”. Remember: you can only send Tagged data to VLAN-aware devices configured to deal with it properly.
Untagged means that on these ports the switch will accept only the incoming traffic without any VLAN IDs (i.e. normal ethernet traffic). The switch will remove VLAN IDs on outgoing data in such ports. Each port can only be assigned as “untagged” to exactly one VLAN ID.
Off: no traffic to or from the tagged ports of this VLAN ID will reach these ports.
Ports can be tagged or untagged:
The tagged port (t is appended to the port number) is the one that forces usage of VLAN tags, i.e. when the packet is outgoing, the VLAN ID tag with vlan value is added to the packet, and when the packet is incoming, the VLAN ID tag has to be present and match the configured vlan value(s).
The untagged port is removing the VLAN ID tag when leaving the port – this is used for communication with ordinary devices that does not have any clue about VLANs. When the untagged packet arrives to the port, the default port VLAN ID (called pvid) is assigned to the packet automatically. The pvid value can be selected by the switch_port section.
If the incoming packet arrives to the interface with software VLANs (incoming packet to eth1) and has a VLAN ID tag set, it appears on the respective software-VLAN-interface instead (VLAN ID 2 tag arrives on eth1.2) – if it exists in the configuration! Otherwise the packet is dropped. Non-tagged packets are deliveded to non-VLAN interface (eth1) as usual.
root@K2P:~# ip r
default metric 1
nexthop via 10.170.72.254 dev pppoe-VWAN21 weight 1
nexthop via 10.170.72.254 dev pppoe-VWAN22 weight 1
nexthop via 10.170.72.254 dev pppoe-VWAN31 weight 1
nexthop via 10.170.72.254 dev pppoe-VWAN32 weight 1
root@K2P:~# ip -6 r default
default metric 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN21 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN22 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN31 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN32 weight 1 pref medium
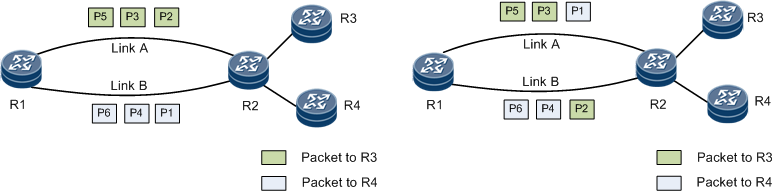
Existing Multipath Routing implementation in Linux is designed to distribute flows of packets over multiple paths, not individual packets. Selecting route in a per-packet manner does not play well with TCP, IP fragments, or Path MTU Discovery.
ip rule add table 916
ip route add 10.173.0.0/16 via 10.170.72.254 dev pppoe-VWAN31 table 916
ip route add 10.170.0.0/16 via 10.170.72.254 dev pppoe-VWAN32 table 916
ip route add ${addresss}/${mask} nexthop via ${gateway 1} weight ${number} nexthop via ${gateway 2} weight ${number}
Multipath routes make the system balance packets across several links according to the weight (higher weight is preferred, so gateway/interface with weight of 2 will get roughly two times more traffic than another one with weight of 1). You can have as many gateways as you want and mix gateway and interface routes, like:
ip route add default nexthop via 192.168.1.1 weight 1 nexthop dev ppp0 weight 10
Warning: the downside of this type of balancing is that packets are not guaranteed to be sent back through the same link they came in. This is called “asymmetric routing”. For routers that simply forward packets and don’t do any local traffic processing such as NAT, this is usually normal, and in some cases even unavoidable.
If your system does anything but forwarding packets between interfaces, this may cause problems with incoming connections and some measures should be taken to prevent it.
可以补充的是如果用的多个等带宽的PPPoE Interface的话,可以使用多个nexthop dev ${pppoe-dev}
fib_multipath_hash_policy - INTEGER
Controls which hash policy to use for multipath routes. Only valid for kernels built with CONFIG_IP_ROUTE_MULTIPATH enabled.
Default: 0 (Layer 3)
Possible values:
0 - Layer 3
1 - Layer 4
2 - Layer 3 or inner Layer 3 if present
fib_multipath_use_neigh - BOOLEAN
Use status of existing neighbor entry when determining nexthop for multipath routes. If disabled, neighbor information is not used and packets could be directed to a failed nexthop. Only valid for kernels built with CONFIG_IP_ROUTE_MULTIPATH enabled.
Default: 0 (disabled)
Possible values:
0 - disabled
1 - enabled
for i in`seq 1 2`do
ip link add link eth0.2 name veth$itype macvlan
done
拨号
还是用脚本省事,填上用户名和密码即可,拨数为2,填下账号密码
#!/bin/shusername=password=for i in`seq 1 2`do
uci set network.VWAN$i=interface
uci set network.VWAN$i.proto='pppoe'
uci set network.VWAN$i.username="$username"
uci set network.VWAN$i.password="$password"
uci set network.VWAN$i.metric="$((i+1))"
uci set network.VWAN$i.ifname="veth$i"
uci set network.VWAN$i.ipv6='1'done
uci commit network
添加所有PPPoE接口到wan zone(担心影响到其他的网络环境的话手动也可以)
for i in`uci show network | grep pppoe | awk-F.'{print $2}'`do
uci add_list firewall.@zone[2].network=$idone
uci commit firewall
添加ECMP路由
只用nexthop dev ${pppoe-dev}:
#IPv4
ip route replace default metric 1 nexthop dev pppoe-VWAN1 nexthop dev pppoe-VWAN2
#IPv6
ip -6 route replace default metric 1 nexthop dev pppoe-VWAN1 nexthop dev pppoe-VWAN2
root@OpenWrt:~# ip -6 route | grep pppoe
default from 2001:250:1006:dff0::/64 via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN4 proto static metric 512 pref medium
2000:::/3 dev pppoe-VWAN4 proto static metric 256 pref medium
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-wan weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN4 weight 1
default from 2001:250:1006:dff0::/64 via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 proto static metric 512 pref medium
2001:250:1006:dff0::/64 dev pppoe-VWAN3 proto static metric 256 pref medium
...
之后通过下面两条常规的添加路由表条目的命令:
route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2
route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3
发现路由表就出现了nexthup和负载均衡中的weight标记
root@OpenWrt:~# ip -6 route | grep pppoe
default from 2001:250:1006:dff0::/64 via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 proto static metric 512 pref medium
2000::/3 dev pppoe-VWAN3 proto static metric 256 pref medium
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 weight 1
...
D = 当前正在下载 (感兴趣且没有被阻塞)
d = 本级客户端需要下载, 但是对方没有发送 (感兴趣但是被阻塞)
U = 当前正在上传 (感兴趣且没有被阻塞)
u = 对方需要本机客户端进行上传, 但是本机客户端没有发送 (感兴趣但是被阻塞)
O = 开放式未阻塞
P = 使用μTP协议连接,兼具TCP的可靠性及UDP的连接性
S = 对方被置于等待状态
I = 对方为一个连入连接
K = 对方没有阻塞本机客户端, 但是本机客户端不感兴趣
? = 本机客户端没有阻塞对方, 但是对方不敢兴趣
X = 对方位于通过来源交换获取到的用户列表中 (PEX)
H = 对方已被通过 DHT 获取.
E = 对方使用了协议加密功能 (所有流量)
e = 对方使用了协议加密功能 (握手时)
L = 对方为本地/内网用户 (通过网络广播发现或位于同一网段中)
Short Guard Interval (GI),由于多径效应(即使单路传输也存在)的影响,信息符号(Information Symbol)将通过多条路径传递,可能会发生彼此碰撞,导致ISI干扰。为此,802.11a/g标准要求在发送信息符号时,必须保证在信息符号之间存在800 ns的时间间隔,这个间隔被称为Guard Interval (GI)。802.11n仍然使用缺省使用800 ns GI