Chinese whispers is an old children’s game where everyone sits in a circle, and one child whispers into the ear of the next on their right a sentence like Send reinforcements, we’re going to advance. That child then whispers the message they heard to the child on their right, until it reaches the one who started it, who says out loud what they heard, classically Send three-and-fourpence, we’re going to a dance, as a demonstration of how messages can so easily become corrupted. What this has to do with China remains one of childhood’s mysteries. I should also explain that three-and-fourpence was idiomatic British English in the days before our currency was ‘decimalised’, and meant three shillings and four (old) pence, about 17 (new) pence, sufficient at one time to enjoy a good night out.
In this article I’m going to do much the same with metadata for a PDF document, tracing what gets indexed by Spotlight, so becoming discoverable by search, and what is displayed in the Finder. This relies on several of my utilities, most of which are available from this page.
Source PDF
I prepared a completely unrelated PDF using my favourite PDF editor, PDF Expert, by adding metadata to be saved in the file’s data. As you might expect, there are several ways that could be stored in the PDF format, including XMP metadata, but in this case for simplicity they were added in the document information dictionary.
I inspected that in a source view in Podofyllin, which found the following fields: /Author (Author name in pdf)
/Creator (Pages)
/Keywords (keyword1 pdf)
/Subject (Subject in pdf)
/Title (0PDFtest1accessdefault)
When rendered in macOS, those are ‘flattened’ by its Quartz PDF engine, to /Author (Author name in pdf)
/Creator (Pages)
/Keywords (keyword1 pdf)
/AAPL:Keywords [(keyword1 pdf)]
/Subject (Subject in pdf)
/Title (0PDFtest1accessdefault)
Note the copying of keywords into a new attribute AAPL:Keywords.
Extended attributes
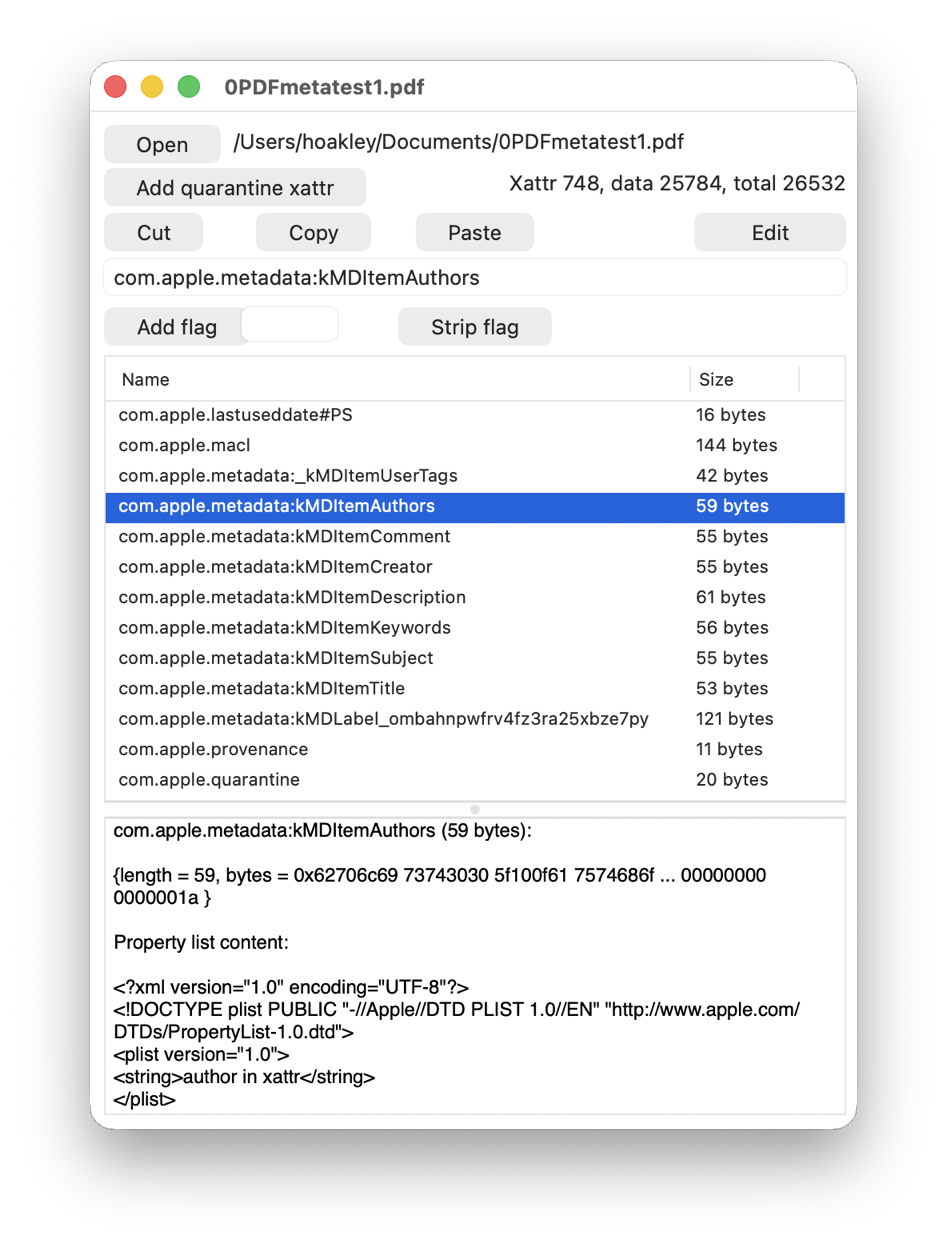
I then added seven extended attributes using Metamer, with names such as com.apple.metadata:kMDItemAuthors, as shown below in xattred.
Spotlight import
I then inspected the file in SpotTest’s new Drop Window, which reported the following attributes found by mdimport: ":EA:kMDItemAuthors" = "author in xattr";
":EA:kMDItemComment" = "xattr comment";
":EA:kMDItemCreator" = "xattr creator";
":EA:kMDItemDescription" = "xattr description";
":EA:kMDItemKeywords" = "keyword1,xattr";
":EA:kMDItemSubject" = "xattr subject";
":EA:kMDItemTitle" = "xattr title";
all from the extended attributes, while those derived from the PDF data were kMDItemAuthors = (Pages);
kMDItemCreator = Pages;
kMDItemDescription = "Subject in pdf";
kMDItemKeywords = ("keyword1 pdf");
kMDItemTitle = 0PDFtest1accessdefault;
Those attributes have already changed, with PDF Subject becoming kMDItemDescription, Creator being duplicated into kMDItemAuthors, and the loss of PDF Author.
Spotlight indexes
Attributes reported by mdls changed again to kMDItemAuthors = (Pages)
kMDItemComment = "xattr comment"
kMDItemCreator = "Pages"
kMDItemDescription = "Subject in pdf"
kMDItemKeywords = ("keyword1,xattr")
kMDItemSubject = "xattr subject"
kMDItemTitle = "0PDFtest1accessdefault"
This has lost the xattr attributes kMDItemAuthors, kMDItemCreator, kMDItemDescription and kMDItemTitle, and the PDF kMDItemKeywords. That list of 7 attributes should then be searchable using Spotlight.
The Finder
The final step was to discover which of those could be displayed in the Finder, either in its Get Info dialog, or in the Preview panel of a Finder window.
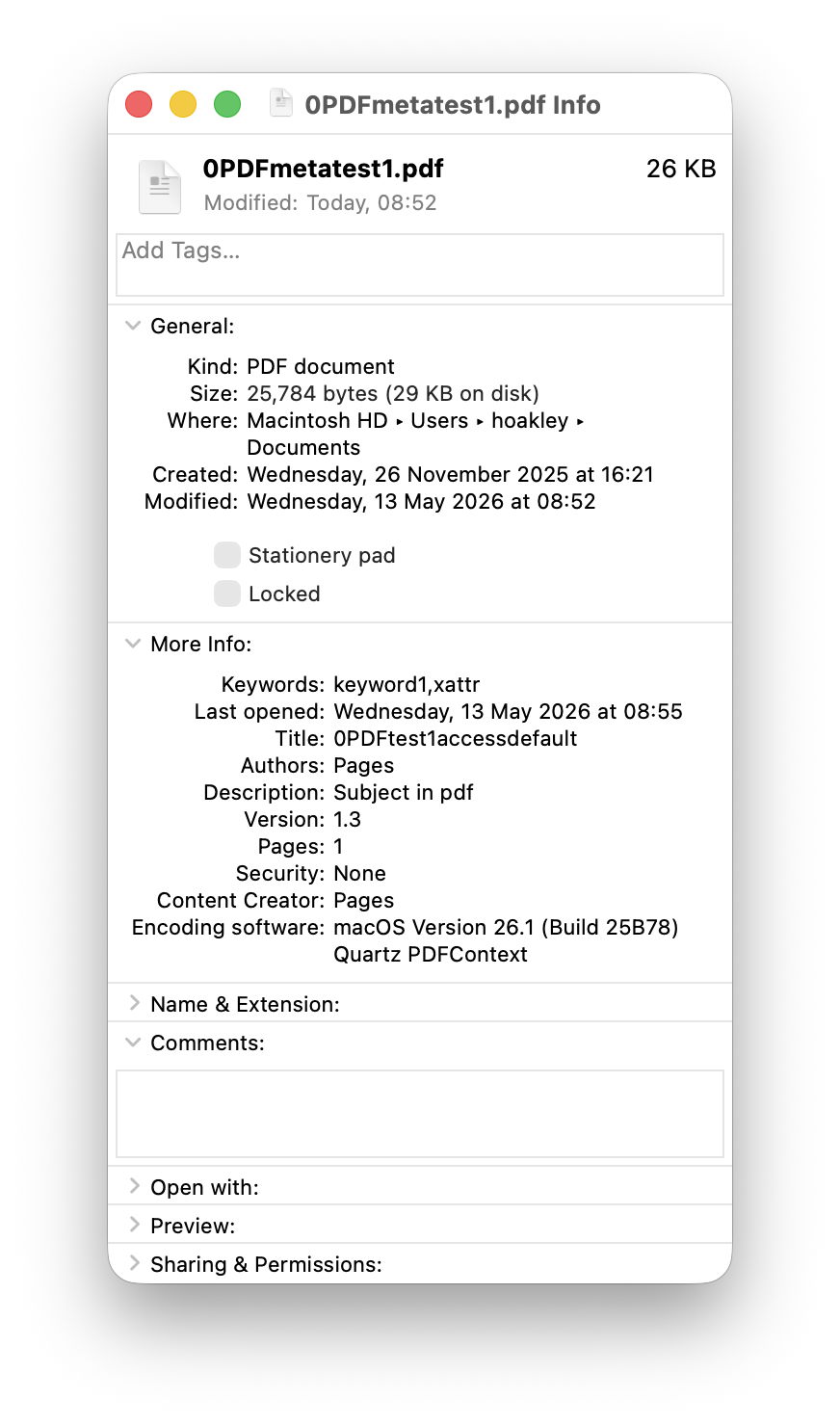
Only 5 of those attributes survived in the Finder, and were given as Authors: Pages
Content Creator: Pages
Description: Subject in pdf
Keywords: keyword1,xattr
Title: 0PDFtest1accessdefault
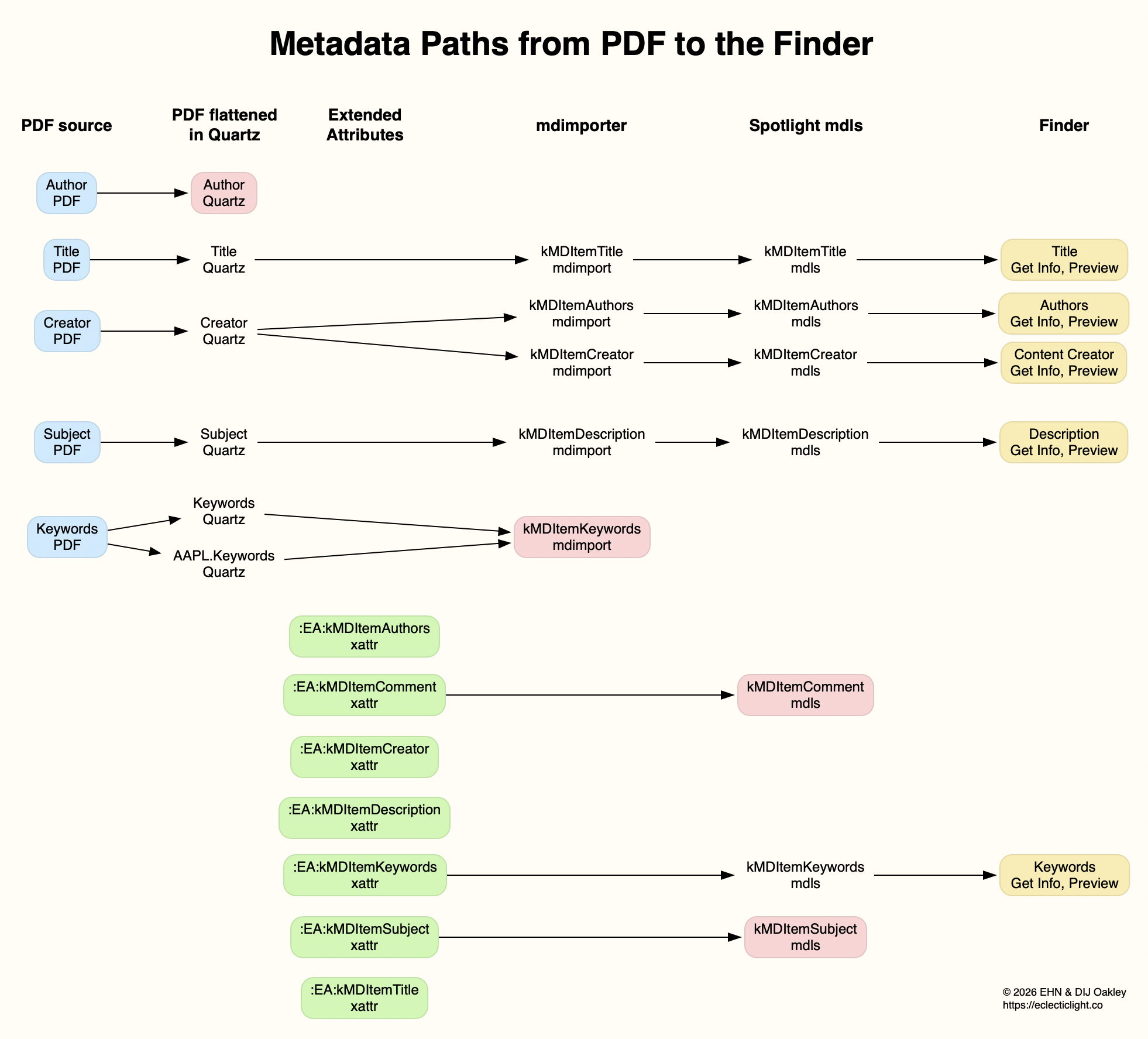
Of those, 4 are taken from the metadata in the PDF file, and only the Keywords were taken from its extended attribute. The attribute named as Authors contains a duplicate of what had originally been in the PDF Creator field, but neither of the PDF Author or xattr kMDItemAuthors fields. Those paths are traced in the diagram below.
Conclusions
Of the total of 12 distinct metadata attributes added in the PDF data and extended attributes, only 6 different items were indexed by Spotlight, and 4 were displayed in the Finder (allowing for the duplication of Authors and Content Creator).
Before relying on metadata for search and access in the Finder, it’s essential to verify that the attributes you intend using are successfully indexed and displayed. Choose the wrong attributes and you’ll never find anything.
Keeping previous versions of a document you’re working on can be a great timesaver. Although I seldom restore files from backups, it’s far more frequent that I look back in a file’s versions to recover changed or removed contents. In most cases, those had changed so rapidly that even hourly backups didn’t capture them. Had those versions not been saved automatically by macOS, I would have wasted time trying to recreate them from scratch.
Although a great many apps now come with built-in version support, macOS doesn’t preserve those versions as well as it could. Duplicate a document with versions, save it as another document, or move it to a different volume, and all its versions are blown away. As I explained yesterday, versions don’t transfer in iCloud Drive either. This article explains how you can work around all those, how to ensure versions get backed up, and how you can create PDF documents with versions.
How versions work
Many apps now have built-in support to automatically save versions of documents you edit with them. The tell-tale sign is when the app has a Revert To command in its File menu, which opens the current document in a version browser resembling the Time Machine app.
Each time you save a document in those apps, the existing document is saved to a hidden and locked-down database at the root level of that volume, in the .DocumentRevisions-V100 folder. When you use the Revert To command to browse all versions, you can look back at all the versions of that document saved to that volume. You can then revert to an older version, or copy contents from an older version to the current one. As long as that document remains in its current volume, those versions will remain accessible. However, if that document is moved to a different volume, even on the same disk, those versions don’t move with it, but will be retained in the original volume until it’s deleted from there.
If you’ve been editing a document in your Documents folder and move it into iCloud Drive, which is actually a folder inside your Home Library folder, its versions will be preserved when you access it from the same Mac. However, other Macs connected to the same iCloud account won’t see those versions, as they remain on the original Mac and don’t get synced to iCloud Drive.
How to extend versions
Apps can’t access stored versions directly, but have to do that via macOS. The most compatible way for them to do that is to fetch previous versions from the volume version database. They can then save each version as a separate file, and reconstitute a document complete with its versions by adding those files back to a document’s versions in the volume’s database. That’s exactly what my free utilities Versatility and Revisionist do. Versatility is the simpler of the two to use here, while Revisionist adds more features including checking documents to see how many versions they already have stored in their volume database.
Archive versions
Simply drag and drop a file with saved versions onto Versatility’s window, and it will extract all its versions and save them as a series of numbered files in a folder. You can then copy or move that folder to any other location, where you can reconstitute the original document with all its versions intact.
Unarchive versions
Simply drag and drop a folder containing archived version files onto Versatility’s window, and it will reconstitute the original document with all its previous versions.
Versions in iCloud Drive
To preserve all versions in iCloud Drive and make them available to all that connect to that folder, move the document from its existing location in your Home folder, to the correct folder in iCloud Drive. Once it’s there:
Perform any editing necessary.
Archive. Drop the document onto Versatility’s window, and save that archive folder to the same location.
Move the original document elsewhere.
When you want to edit that document, particularly on another Mac, on that Mac:
Unarchive. Drop the archive folder onto Versatility’s window, and save the document to the same location.
Edit the document, saving whenever you want to create a new version.
When you’ve finished, save for the last time, and close the document.
Archive. Drop the document onto Versatility’s window, and save that archive folder to the same location.
Tidy up old archive folders and files.
That leaves the most recent archive folder, with composite versions written in the correct order, with the right timestamps, ready to be unarchived on the next Mac to edit that document. This may appear complicated, but once you have tried it out, it’s really a simple sequence to unarchive-edit-save-archive and hand over to the next editor.
Backing up versions
I’m not aware of any backup utility for macOS, including Time Machine, that backs up and preserves versions, although they are stored in local volume snapshots. However, all you have to do is archive the versions of important files into folders using Versatility, and back up those folders. When you want to restore the original document with all its versions, simply unarchive that folder using Versatility.
PDF versions
One of the lesser-known features of the PDF format are incremental updates, which can provide a primitive form of versioning within a single file. In practice it catches users out when they publish a PDF containing old edited content they thought had been removed.
Few PDF editors and viewers support the macOS version system, but Preview does, and Versatility can be used to assemble a PDF document with versions.
For my example, rather than edit a PDF, I generated a series from an archived RTF, converting each file into a consecutively numbered PDF, starting from 000.pdf and rising to 010.pdf. I then dropped that folder onto Versatility’s window and it unarchived those into a single PDF document with all those versions.
Key points
Archive a file with saved versions to a folder by dropping it onto Versatility’s window.
Unarchive a folder containing version files to a file with saved versions by dropping it onto Versatility’s window.
In iCloud Drive, unarchive-edit-save-archive to preserve versions for the next editor.
Wherever you want to preserve versions, archive the file using Versatility.
Anthropic 的内部团队正在利用 Claude Code 彻底改变他们的工作流程。无论是开发者还是非技术人员,都能借助它攻克复杂项目、实现任务自动化,并弥补那些曾经限制生产力的技能鸿沟。
为了深入了解,我们采访了以下团队:
通过这些访谈,我们收集了不同部门使用 Claude Code 的方式、它对工作带来的影响,以及为其他考虑采用该工具的组织提供的宝贵建议。
数据基础设施团队负责为公司内所有团队整理业务数据。他们使用 Claude Code 来自动化常规的数据工程任务、解决复杂的基础设施问题,并为技术和非技术团队成员创建文档化工作流,以便他们能够独立访问和操作数据。
利用截图调试 Kubernetes
当 Kubernetes 集群出现故障,无法调度新的 pod 时,团队使用 Claude Code 来诊断问题。他们将仪表盘的截图喂给 Claude Code,后者引导他们逐个菜单地浏览 Google Cloud 的用户界面,直到找到一个警告,指出 pod 的 IP 地址已耗尽。随后,Claude Code 提供了创建新 IP 池并将其添加到集群的确切命令,整个过程无需网络专家的介入。
为财务团队打造纯文本工作流
工程师向财务团队成员展示了如何编写描述其数据工作流程的纯文本文件,然后将这些文件加载到 Claude Code 中,以实现完全自动化的执行。没有任何编程经验的员工只需描述“查询这个仪表盘,获取信息,运行这些查询,生成 Excel 输出”等步骤,Claude Code 就能执行整个工作流,甚至会主动询问日期等必要输入。
为新员工提供代码库导览
当新的数据科学家加入团队时,他们会被指导使用 Claude Code 来熟悉庞大的代码库。Claude Code 会阅读他们的 Claude.md 文件(文档),识别特定任务所需的相关文件,解释数据管道的依赖关系,并帮助新人理解哪些上游数据源为仪表盘提供数据。这取代了传统的数据目录和发现工具。
会话结束时自动更新文档
在每项任务结束时,团队会要求 Claude Code 总结已完成的工作并提出改进建议。这创建了一个持续改进的循环:Claude Code 根据实际使用情况帮助优化 Claude.md 文档和工作流指令,使后续的迭代更加高效。
跨多个实例并行管理任务
在处理耗时较长的数据任务时,团队会为不同项目在不同的代码仓库中打开多个 Claude Code 实例。每个实例都能保持完整的上下文,因此即使在数小时或数天后切换回来,Claude Code 也能准确地记住他们当时正在做什么以及任务进行到哪里,从而实现了无上下文丢失的真正并行工作流管理。
无需专业知识即可解决基础设施问题
解决了通常需要系统或网络团队成员介入的 Kubernetes 集群问题,利用 Claude Code 诊断问题并提供精确的修复方案。
加速新员工上手
新的数据分析师和团队成员无需大量指导,就能迅速理解复杂的系统并做出有意义的贡献。
增强支持工作流
Claude Code 能够处理比人类手动审查大得多的数据量,并识别异常情况(例如监控 200 个仪表盘),这是人力无法完成的。
他们建议使用 MCP 服务器而不是 BigQuery 命令行界面,以便更好地控制 Claude Code 的访问权限,尤其是在处理需要日志记录或存在潜在隐私问题的敏感数据时。
分享团队使用心得
团队举办了分享会,成员们互相演示他们使用 Claude Code 的工作流程。这有助于传播最佳实践,并展示了他们自己可能没有发现的各种工具使用方法。
Claude Code 产品开发团队使用自家的产品来为 Claude Code 构建更新,扩展产品的企业级功能和 AI 智能体循环功能。
通过“自动接受模式”快速构建原型
工程师们通过启用“自动接受模式”(Shift+Tab)并设置自主循环,让 Claude 编写代码、运行测试并持续迭代,从而实现快速原型开发。他们将自己不熟悉的抽象问题交给 Claude,让它自主工作,然后在接手进行最后润色前,审查已完成 80% 的解决方案。团队建议从一个干净的 git 状态开始,并定期提交检查点,这样如果 Claude 跑偏了,他们可以轻松回滚任何不正确的更改。
同步编码开发核心功能
对于涉及应用程序业务逻辑的更关键功能,团队会与 Claude Code 同步工作,提供带有具体实现指令的详细提示。他们实时监控过程,确保代码质量、风格指南合规性和正确的架构,同时让 Claude 处理重复的编码工作。
构建 Vim 模式
他们最成功的异步项目之一是为 Claude Code 实现 Vim 快捷键绑定。他们要求 Claude 构建整个功能,最终实现中大约 70% 的代码来自 Claude 的自主工作,只需几次迭代即可完成。
生成测试和修复 bug
在实现功能后,团队使用 Claude Code 编写全面的测试,并处理在代码审查中发现的简单 bug。他们还使用 GitHub Actions 让 Claude 自动处理像格式问题或函数重命名这样的 Pull Request 评论。
代码库探索
在处理不熟悉的代码库(如 monorepo 或 API 端)时,团队使用 Claude Code 来快速理解系统的工作方式。他们不再等待 Slack 上的回复,而是直接向 Claude 提问以获取解释和代码参考,从而大大节省了上下文切换的时间。
更快的功能实现
Claude Code 成功实现了像 Vim 模式这样的复杂功能,其中 70% 的代码由 Claude 自主编写。
尽管对“JavaScript 和 TypeScript 知之甚少”,团队仍使用 Claude Code 构建了完整的 React 应用,用于可视化强化学习(RL)模型的性能和训练数据。他们让 Claude 控制从头开始编写完整的应用程序,比如一个 5000 行的 TypeScript 应用,而无需自己理解代码。这一点至关重要,因为可视化应用相对上下文较少,不需要理解整个 monorepo,从而可以快速构建原型工具,以便在训练和评估期间了解模型性能。
处理重复的重构任务
当遇到合并冲突或半复杂的文件重构时——这些任务对于编辑器宏来说太复杂,但又不足以投入大量开发精力——他们就像玩“老虎机”一样使用 Claude Code:提交当前状态,让 Claude 自主工作 30 分钟,然后要么接受解决方案,要么在不成功时重新开始。
创建持久性分析工具而非一次性笔记本
团队现在不再构建用完即弃的 Jupyter 笔记本,而是让 Claude 构建可重复使用的 React 仪表盘,这些仪表盘可以在未来的模型评估中重复使用。这很重要,因为理解 Claude 的性能是“团队最重要的事情之一”——他们需要了解模型在训练和评估期间的表现,而这“实际上并非易事,简单的工具无法从观察一个数字上升中获得太多信号”。
零依赖任务委托
对于完全不熟悉的代码库或语言中的任务,他们将整个实现委托给 Claude Code,利用其从 monorepo 中收集上下文并执行任务的能力,而无需他们参与实际的编码过程。这使得他们在自己专业领域之外也能保持生产力,而不是花时间学习新技术。
在让 Claude 工作之前保存你的状态,让它运行 30 分钟,然后要么接受结果,要么重新开始,而不是试图费力去修正。重新开始的成功率通常比试图修复 Claude 的错误要高。
必要时为了简化而打断它
在监督过程中,不要犹豫,停下来问 Claude “你为什么这么做?试试更简单的方法。” 模型默认倾向于更复杂的解决方案,但对于简化方法的请求反应良好。
产品工程团队致力于开发如 PDF 支持、引用和网页搜索等功能,这些功能将额外的知识引入 Claude 的上下文窗口。在大型、复杂的代码库中工作意味着不断遇到不熟悉的代码部分,花费大量时间来理解特定任务需要检查哪些文件,并在进行更改前建立上下文。Claude Code 通过充当向导,帮助他们理解系统架构、识别相关文件并解释复杂的交互,从而改善了这种体验。
第一步工作流规划
团队将 Claude Code 作为任何任务的“第一站”,要求它确定在进行 bug 修复、功能开发或分析时需要检查哪些文件。这取代了传统上在开始工作前手动浏览代码库和收集上下文的耗时过程。
跨代码库独立调试
团队现在有信心处理不熟悉代码库部分的 bug,而无需向他人求助。他们可以问 Claude “你觉得你能修复这个 bug 吗?我看到的行为是这样的”,并经常能立即取得进展,这在以前由于所需的时间投入是不可行的。
通过内部测试进行模型迭代测试
Claude Code 自动使用最新的研究模型快照,使其成为他们体验模型变化的主要方式。这为团队在开发周期中提供了关于模型行为变化的直接反馈,这是他们在之前的发布中从未体验过的。
消除上下文切换的开销
他们不再需要复制粘贴代码片段并将文件拖入 Claude.ai,同时还要详细解释问题,现在可以直接在 Claude Code 中提问,无需额外的上下文收集,从而显著减少了心智负担。
增强了处理不熟悉领域的信心
团队成员可以独立调试 bug 并调查不熟悉代码库中的事故。
在上下文收集中节省了大量时间
Claude Code 消除了复制粘贴代码片段和将文件拖入 Claude.ai 的开销,减轻了心智上的上下文切换负担。
加速轮岗员工上手速度
轮岗到新团队的工程师可以快速熟悉不熟悉的代码库并做出有意义的贡献,而无需与同事进行大量咨询。
提升开发者幸福感
团队报告称,随着日常工作流程中的摩擦减少,他们感到更快乐、更高效。
将其视为迭代伙伴,而非一次性解决方案
不要指望 Claude 能立即解决问题,而是把它当作一个与你一起迭代的合作者。这种方法比试图在第一次尝试中就获得完美的解决方案效果更好。
最近有很多朋友在讨论:「Deep Research 的用量是怎么算的?」 又因为目前 Plus 每个月只能用 10 次,大家都非常担心浪费。其实一句话就能总结——只要开始出现 「Starting Research」 的进度条,就算使用了一次。在进度条出现之前,怎么问都不算。下面就为大家分享一些 Deep Research 的使用流程、注意事项和提示词模板,帮助大家更好地运用这一强大的研究功能。
报告生成 研究进度条走完后,ChatGPT 会给你发送完整的报告,这标志着一次 Deep Research 流程的完成。
进度条出现后,你可以随时离开 进度条开始后,无论你是关闭窗口、刷新网页、切换到其他会话还是新开会话,都不会影响已经开始的 Deep Research 流程,它会在后台继续执行并最终生成报告。
Deep Research 可以后续追问 当报告生成结束后,如果你要继续追加信息重新生成报告,有两种选择:1). 直接提问,会使用你开始会话时选择的模型继续对话,报告内容可以作为上下文;比如说你从 GPT-4o 开始的,那么你在报告生成后,如果继续提问,实际上是 GPT-4o 基于你报告和提问内容回复,但是可能会受限于上下文长度无法完整理解报告内容;2). 重新生成新报告:Deep Research 是一次性生成的,但是你可以继续在当前会话选中「Deep research」按钮,这样可以把当前会话内容作为输入,或者把内容复制出去新开会话选中「Deep research」按钮重新开始一次新的生成。内容复制出去处理一下再生成会更好的对输入进行控制,但是麻烦一些。
你无法追加新的信息让它继续深度研究。如果你在当前会话里继续追问,后续的回答将由其他模型(如 GPT-4o)接管。 如果你对报告不满意,需要重新修改提示词再新开一次会话进行 Deep Research。
灵活切换模型 你可以先选任何模型(如 o1 pro/o1 等),再让它进行 Deep Research。若后续还打算继续追问报告内容,建议在 Deep Research 开始前就选一个更强的模型(比如 o1 pro / o1)来进行分析。