RSS简单科普
9 September 2024 at 09:26
RSS是一种基于XML的内容发布和订阅格式,用于在互联网上分享和同步网站内容。用户可通过RSS阅读器订阅网站的最新内容,从而在一个界面中查看多个网站的更新。尽管其主流性已降低,但RSS仍然在信息自主选择和隐私保护方面展现独特价值,为用户提供高效的信息获取方式。
RSS简单科普最先出现在Justin写字的地方。
RSS是一种基于XML的内容发布和订阅格式,用于在互联网上分享和同步网站内容。用户可通过RSS阅读器订阅网站的最新内容,从而在一个界面中查看多个网站的更新。尽管其主流性已降低,但RSS仍然在信息自主选择和隐私保护方面展现独特价值,为用户提供高效的信息获取方式。
RSS简单科普最先出现在Justin写字的地方。
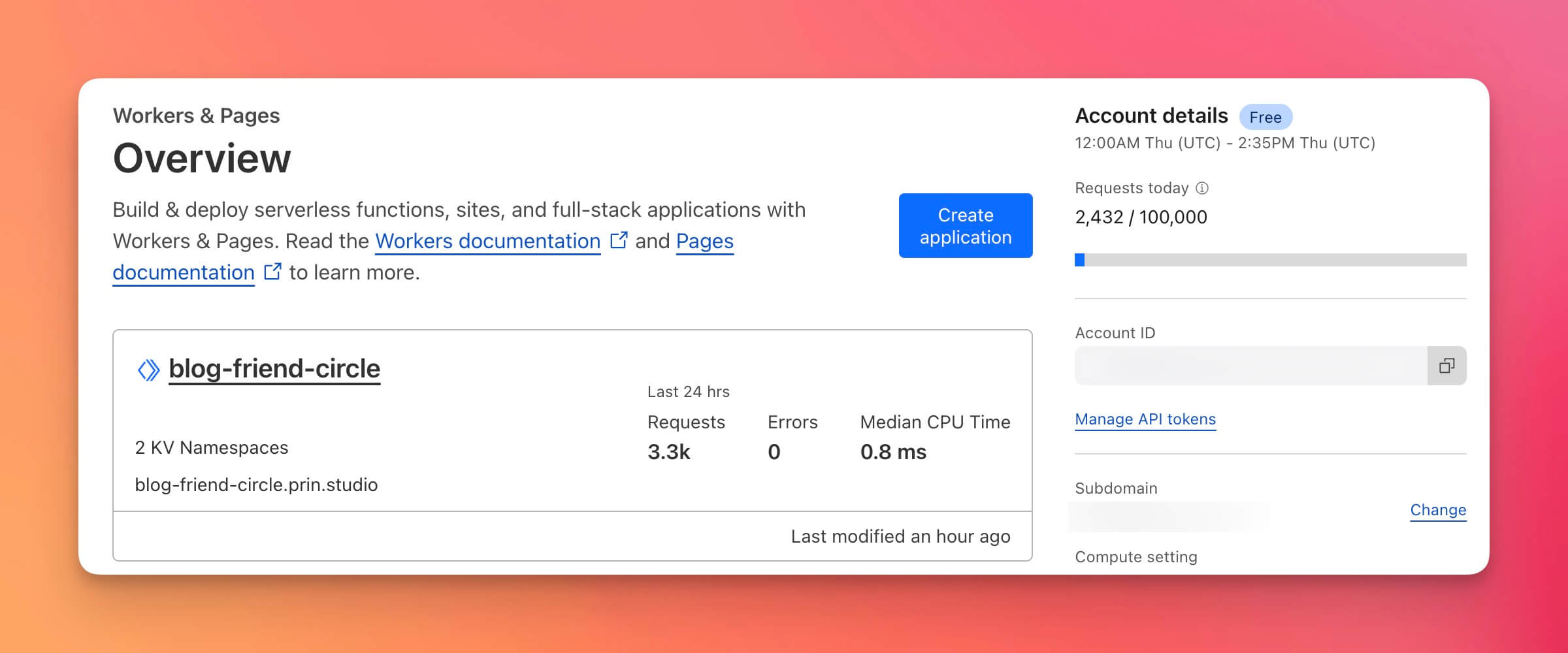
先来看看效果:友情链接 - PRIN BLOG。
自我感觉还是不错的,友链的博客们有什么更新都可以实时展示在页面上,一目了然。作为博主,不用打开 RSS 阅读器就可以查看新文章;作为访客,也可以快速找到更多自己感兴趣的内容,比起原来全是链接的页面,看起来也让人更有点击欲望了。
从临时起意到开发完成总共两个晚上,最速传说就是我!(误)
前段时间看到有个博客用了这样的一个东西:
当时就感觉卧槽好高端,很有想法。
这种聚合订阅的形式有个名字,叫做 Planet(社区星球)。Planet 通常用于聚合某个领域的博客,然后展示在一个页面上,方便用户一站式阅读,比如:
这种形式在开源社区里比较常见,不过用在博客的友链上我倒还是第一次看到。
就像我在本站友链页里说的一样,独立博客之间的联系基本上就是靠的链接交换和评论互访。一个博客的访客看到了其他博客的链接,点过去看了,然后从对面的友链中,又导航到新的博客……如此往复,我们就依靠着这种从现在看来显得十分古老的方式,维系着这些信息孤岛之间的纽带。原始又浪漫。
不过这里就会涉及到一个用户点击率的问题。我自己之前在维护友链页面的时候,总感觉只放标题和链接看起来效果不怎么好。就算加上描述、头像这些元素,也总觉得差点意思。因为一个博客最重要的其实还是它的内容,仅靠一个网站标题,可能很难吸引到其他用户去点击。
而「友链朋友圈」的这种形式,就像微信朋友圈一样,作为一个聚合的订阅流,展示了列表中每个博客的最新文章。
比起干巴巴的链接,这显然会更加吸引人。虽然我写博客到现在也已经 9 年了,早就佛系了,主打一个爱看不看。不过对于和我交换了友链的博主们,还是希望他们能够获得更多的曝光和点击(虽然我这破地方也没多少流量就是啦……),也希望我的访客们也可以遇到更多有价值的博客。
然而在准备接入的时候,我发现这玩意儿不就是一个小型的 RSS 阅读器么……其实等于是自己又实现了一套订阅管理、文章爬取、数据保存之类的功能。
于是我就寻思,可能直接复用已有 RSS 阅读器 API 的思路会更好,让专业的软件做专业的事。友链的管理也可以直接复用 RSS 阅读器的订阅管理功能,这样增删改也不需要了,我们就只需要封装一下查询的 API,提供一个精简的展示界面就 OK。
作为行动力的化身,咱们自然是说干就干,下班回家马上开工!
首先是 RSS 后端的选择。
市面上的 RSS 阅读器有很多,我自己主要用的是 Inoreader。然而我看了下,Inoreader API 只面向 $9.99 一个月的 Pro Plan 开放,而且限制每天 100 个请求……这还玩个屁。Feedly 也是差不多一个尿性,可以全部 PASS 了。我也不知道该说他们什么好,也许做 RSS 真的不挣钱,只能这样扣扣搜搜了吧。
另外一个选择就是各种支持 self-host 的 RSS 阅读器,比如 Tiny Tiny RSS 和 Miniflux。我之前部署过 TTRSS,说实话感觉还是太重了。Miniflux 则是使用 Go 编写的,该有的功能都有,非常轻量级,部署也很方便。就决定是它了!
技术栈方面选择了之前一直比较心水的 Hono,部署在 Cloudflare Workers 上。前端方面没有使用任何框架,连客户端 JS 都没几行,基本上是纯服务端渲染。有时候不得不感叹技术的趋势就是个圈,以前那么流行 SPA,现在又都在搞静态生成了。
![]()
页面渲染使用了 Hono 提供的 JSX 方案,可以在服务端用类似 React 的语法返回 HTML,挺好用的。不过 CSS 没有用 Hono 的那一套 CSS-in-JS,因为要允许用户覆盖样式,所以要用语义化的类名。最后选了 Less,还是熟悉的味道。
前端文件的构建使用了 tsup,配置文件就几行,爽。
实现思路很简单,就是做一个 Proxy 层,把:
GET /v1/categories/22/entries - Get Category EntriesGET /v1/categories/22/feeds - Get Category Feeds这两个 Miniflux 的 API 包一下。这里要注意不能暴露实际的 API Endpoint,避免可能的恶意攻击。API 缓存也要在我们这一层做好,防止频繁刷新把服务打爆。
缓存策略上使用了 SWR (Stale-While-Revalidate):
stale 状态,依然返回前端;这样可以保证最快的响应速度,以及相对及时的更新速度,比较适合这种场景。
最后的交付形式其实就是两个 HTML 页面,通过 <iframe> 的形式嵌入到网页中。另外参考 giscus 提供了一个脚本,可以设置参数并自动完成 iframe 的初始化,用户只需要引入一个 <script> 标签即可,非常方便:
<script async data-category-id="28810" src="https://blog-friend-circle.prin.studio/app.js"></script>![]()
当然也可以作为独立页面打开,有做双栏布局适配:
blog-friend-circle.prin.studio/category/2/entries
新版博客友链朋友圈的所有代码都开源在 GitHub 上,欢迎使用:
这个方案和 hexo-circle-of-friends 并没有孰优孰劣之分,只是侧重点和实现方式不同。不过我这个的一个好处是,如果你已经在用 Miniflux 了,那么可以直接复用已有的大部分能力,不需要再起一个 Python 服务和数据库去抓取、保存 RSS,相对来说会更轻量、稳定一些。
如果你选择使用 Miniflux 官方提供的 RSS 服务,甚至可以无需服务器,部署一下 CF Workers 就行了,像我这样的懒人最爱。
虽然大家写 blog 的频率都没那么勤了,但是,RSS 还是有其它可以玩的方式的!
很多人都有用各种 read it later、或者书签类工具,把有意思的网页保存下来。在这些工具里,可以通过某些手法,把一些想要分享的网页,生成 rss。其他好友订阅这个 rss 地址,就可以自动刷新,看到你推荐的文章啦!
下面介绍一些,常见的书签网站,生成 rss 的方式。但首先——
我的 RSS 分享地址是:
https://feed.fivest.one/readings
或者
https://feeds.feedburner.com/fivestone/readings有兴趣和我分享的,欢迎留言或私信交换!!
感觉 Instapaper 生成 RSS 的功能是最好用的,可以把特定的文件夹设为公开,直接得到它的 rss,形如:
https://instapaper.com/folder/1234567/rss/123456/Vciysdfsd7mod9B好像 Pocket 的免费用户,内容都只能是公开的(无语…),只要知道了用户名,就可以通过 RSS 查看全部的内容(所以生成的 rss 需要转录才安全)。而且不能自定义分类,只有默认的:
https://getpocket.com/users/USERNAME/feed/all
https://getpocket.com/users/USERNAME/feed/unread
https://getpocket.com/users/USERNAME/feed/read最后一条 …/read 会返回所有 Archived 了的文章,可以勉强用它作为分类的手段。
这个只有收费版,我就不去试了。有它家的用户,可以帮忙把生成 rss 的方法分享一下?
我在用 Wallabag,可以自建,也有收费的服务可用。生成的 rss 是全文输出,效果很好。在 Config – Feed 里,生成一个 token,然后点开任何一个 tag,点击列表上方的 rss 图标,就可以得到这个 tag 的 rss 订阅(生成的地址里带着统一的 token,所以需要转录才安全):
https://wallabag.your.domain/feed/USERNAME/asdfghjkl/tags/t:share我的个人网站 LRD.IM 从 2018 年元旦发布至今,已经持续维护 4 年了。从最开始根据一个网站模板替换图文,到现在全面的「自主研发」,这是我最骄傲的一款作品。接下来要开始尝试将我的博客内容输出成 RSS 源。
这篇博客不谈设计。写一点自己对互联网的初印象,将博客做成 RSS 源的原因,以及使用 RSSHub 将自己网站生成订阅源的过程。
家里 2005 年配置了台电脑,依稀记得那会儿互联网的潮流正好是从门户网站转换到「社会性网络」。
Discuz!、贴吧、QQ空间、开心网等等,都是 Web 2.0 的代表作,我「当年」也有高度参与到这些生态里面。那时候的互联网鼓励人们创造内容,强调互动和内容本身。而不像现在基于所谓的「算法」一直在投喂内容,网站上充斥着营销号、广告、对立、(甚至审查🤫)…
我记得以前网络上的内容是挺有趣的,因为都是自发的内容,感觉很真实。而现在在网上看到「有趣」的内容,却总感觉像是某个 MCN 机构生产出来的,所有内容都有目的,一直在包装、孵化,指向最后的变现…
所以正好我这位在 Web 2.0 时代背景下成长的网民,正好也有掌握了一些专业知识,于是乎就捣鼓出属于我的个人网站 LRD.IM,以及目前为止积累了 40 多篇的设计博客。一方面是想通过这些来积累自己的专业知识,另一方面是更想在互联网上留下自己的(且属于自己)的一些痕迹。
以前在 WordPress 搭建的博客、新闻资讯等网站总会有一个 RSS 订阅渠道,最初还没有了解过是什么意思,只是记住了有这个很不起眼的橙色的彩虹条纹的图标。
直到在大学了解到了一些信息获取来源方式和分类之后,才真正了解到 RSS 这个东西。很神奇的是它将内容进行重新格式化输出,将内容和从页面中分离出来,供读者在自己喜欢的第三方阅读器里接收新内容并阅读。
我还是挺认同这个概念的,即使它是 20 年前的产物。
分离原本的网页,意味着读者可以根据自己喜好在第三方阅读器上进行阅读,甚至自己捣鼓一个阅读器,而并非局限在原本网页管理者的设计中。
而第三方阅读器通常都会有新内容通知、已读未读标记、分类、标签等功能,这意味着读者能够拥有自己的一套信息获取方式,而不需要受到算法的介入,并能及时获得新内容的推送。
正好由于今年我的设计博客还上了不少公众号、周报的推荐,我察觉到拥有一个自己的内容推送服务迫在眉睫,而 RSS 订阅、邮件订阅都能满足这个需求,正好我就先将 RSS 订阅服务做起来先。
综上所述,我认同 RSS 的中立、纯粹、无算法介入,以及需要获取一个推送功能。所以,这时的我作为互联网内容生产者,是时候为自己的博客搭建一个 RSS 服务了!
首先阐述下我的预期效果:
于是乎我首先也试了几个做法,第一个是寄托于第三方的 RSS 生成服务。比如 Feed43、Feedburner、RSS.app。当时我是期望这些第三方服务能够满足上述的预期效果,自动抓取我发布的新博客生成为 RSS 文件。它们确实也做到了,但会各自有一些硬伤。
试了一遍论坛/讨论组内大伙儿推荐的 RSS 生成服务提供商,没有完美地达到我的期望,每个都是差一点,只能靠自己了。
眼见外部服务不好使,于是乎我跑去看了看 RSS 的语法规范,尝试用最笨的方法:按照语法自己手动编写一份 XML 文档出来,给到读者去订阅。
大费周章按 RSS 语法规范写完了 XML,传了两份用作测试,一份传在自己的阿里云轻应用服务器上,另一份传到了阿里云 OSS 里。之后用第三方阅读器订阅 RSS 链接。
结果在阅读器里看到顺序错乱,时间异常,更新非常迟缓。刚开始我还以为这个笨方法能行得通,只是做起来比较麻烦,没想到仍然有这么多缺点。
了解 RSSHub
前两种方法试过都不能满足我的要求之后,我实在找不到一个好的思路或方向去实现,唯有在 V2EX 上发了个帖子请教下其他人。虽然帖子只有两个人回复,但足够启发我去解决问题了。
一楼回复建议我给 RSSHub 提个申请,让其他人写个规则来抓取我的网站,然后合并到 RSSHub 项目里,用该链接作为 RSS 的订阅链接。
后面我去了解了下 RSSHub,原来这是一个开源的 RSS 订阅源生成器,编写好规则(项目内称为脚本)后就能将内容按照 RSS 的语法生成一份订阅源,之后都可以用生成出来的链接在第三方阅读器上订阅和浏览。同时可以部署在自己的服务器里面,也能直接用 RSSHub 项目内别人预先编写好的规则,两者的效果是一样的。
粗浅了解下 RSSHub 的能力,以及也看了用该服务生成出来的订阅链接,功能上是能解决我的问题,但是时效性、准确度这些得自己部署完才能知道。
二楼回复认为静态的 XML 文件作为订阅源,会存在着不受我控制的缓存机制。于是乎我更坚定地认为应该尝试使用 RSSHub 的服务,毕竟这是动态生成,不是一个憨憨的静态文件。
安装 RSSHub
登录到服务器,由于我用的网站在阿里云轻服务器上搭建的,所以直接在网页里就能远程登录,其他服务器也能 ssh 登录后依次输入指令安装并运行 RSSHub。
git clone https://github.com/DIYgod/RSSHub.git
cd RSSHub
npm install
npm start
成功安装并运行后,在浏览器访问 1200 端口应该能看到如下页面。
回到终端,设置 RSSHub 服务常驻(断开 ssh 链接后仍然保持服务);以及开机自启。
# 设置常驻
npm install pm2 -g
pm2 start lib/index.js
# 设置开机自启
pm2 save
pm2 startup
这时可以访问几个 RSSHub 项目自带的路由,探索下其他有趣的 RSS 源。然后开始编写自己的脚本路由。
编写脚本路由
这一部分我的思路是参考文档的指引,并且在 RSSHub 项目内找到已有的脚本路由,找一份与自己网页结构类似的脚本,照葫芦画瓢捣鼓一份出来。
按文档的说法,/lib/router.js 里面记载了所有路由,即指明通过域名访问而指向的脚本。我先在里面创建一个路由,让其链接到之后创建的脚本。
# 添加路由
router.get('/feed', lazyloadRouteHandler('./routes/lrdim/blogs'));
其中 /feed 意思是我希望通过域名/feed 能够访问到我的 RSS 源,即 lrd.im/feed。后面的 ./routes/lrdim/blogs 意思是用前面的链接访问时,是链接到 /routes/lrdim/blogs.js 这个文件,用里面的规则生成 RSS 源。
然后到 /lib/routes 里面创建 lrdim 这个文件夹,并在里面创建 blog.js 这个文件,我们的抓取规则要写在里面。
由于我的网站是静态的 HTML 页面,所以我按照文档里的第二种方法,按照元素的标签和样式来抓取里面的数据。并且当时有参考了一个网页结构同样很简单的 RSSHub 内置源:十年之约。具体做法不在这详细说明了,主要按文档规范走就没啥问题,cheerio 语法也很直观容易理解。
保存后过几分钟,已经能在 lrd.im:1200/feed 中访问生成的 RSS 源了。此时需检查下名称、描述、标题、摘要、日期等有没有问题。
注意:日期必须按照格式编写,不能出现非法内容。否则这条 item 不会出现在结果中。我是写成了 YYYY-MM-DD。
调整渲染模版
由于刚刚通过设置 RSSHub 脚本获取到的数据,会经过 rss.art 模版处理后再成为 RSS 订阅源,所以我们需要打开 /lib/views/rss.art 对渲染模版作出相应的调整,比如预设 <webMaster> 不符合预期,调整为我自己的邮箱。
设置代理
至此,我的 RSS 订阅源已经生成完毕,内容、格式等符合要求,剩下的只有域名还不大对劲。
截至到上面的步骤,我的 RSS 订阅源扔人家需要通过端口来访问:lrd.im:1200/feed。这个肯定是不能作为最终产物的,谁会把端口直接暴露出来,太丢人了。于是乎需要配置最后一步:设置代理。
我的服务器里安装了 nginx,打开 nginx/conf/nginx.conf 后配置代理,将 lrd.im/feed 指向 1200 端口的页面。
location /feed {
proxy_pass http://127.0.0.1:1200;
}此时测试 lrd.im/feed,已经能正常访问经 RSSHub 生成的订阅源。
验收
拿订阅链接去各主流阅读器中试验,尝试搜索、添加此链接,并尝试增删改被抓取的网页内容,检查到确实能够及时更新,且不会信息错乱。
大功告成!奉上我的设计博客正式的 RSS 订阅链接:https://lrd.im/feed
将该链接复制到 RSS 阅读器上就能够及时获取我的最新设计博客了。阅读器的话看个人喜好,目前我觉得 Inoreader 和 Reeder 的体验都不错。
费了这么大周章捣鼓的新功能,起码在我的网站里多多曝光才是。所以我顺手做了三件事。
RSSHub 有一个浏览器插件叫 RSSHub Radar,用于探测网站上提供的 RSS,让读者能在浏览器的插件位置直接就能订阅,而不必在网页上费劲去找 RSS 订阅按钮。
支持该功能也不怎么复杂,我在所有页面的 <head> 处都添加了一条订阅地址,就能够被 RSSHub Radar 识别到。
既然是我的博客内容的 RSS 源,那理所当然地应该在 lrd.im/blog.html 里添加一个稍微醒目一点的 Banner,提示到当前已经支持 RSS 啦!
此处参考了 Instagram 和 Apple 的样式,高亮若干秒之后开始减弱对比,使其融入到页面中。用了 CSS 的 keyframe 来做。
从 Google Analytics 处跟踪到的数据,挺多流量是来自直接的博客详情页,而不是先从列表页跳转到详情页。所以也为了增加在详情页的曝光,我在「作者信息」一行右侧新添加了几个按钮,分别是:复制文章链接、RSS 订阅、联系小东。
原本「复制文章链接」这个功能我是做成响应式设计,只在移动端尺寸下才能看到,但还是根据 GA 数据反馈,造访我的博客的流量中有至少 75% 是来自桌面端,所以我将这个功能开放了。
「RSS 订阅」功能点击后能直接跳转到 lrd.im/feed,后续的订阅操作懂得都懂。每篇文章都提供这个入口,极大提高曝光量。
「联系小东」的功能是点击后出现我的微信二维码。我的设计博客通常会输出我的观点和看法,而我的网站里面又没有评论的功能,所以我捣鼓了一个微信二维码上去,读者如果有东西想和我交流就能直接加我好友一起交流。
这些功能没做成悬停在左右两侧,原因是我不太想在读者阅读时有其他干扰项。
哦对了,还顺便 Close 了一个,也是目前唯一一个 Issue。
给博客生成 RSS 订阅源这事虽然一直惦记了有大半年,但实际开始到最终呈现,历时一周左右,都是用下班时间和周末探索的。
又到了给自己挖坑的时间:后面关于博客订阅这块,我会做的几件事:
完成了自己的一项执念,如释重负,舒坦开朗。但心里仍然藏了另一项执念,我惦记了有至少一两年了,仍待推进…
基本上算作官网文档的补充,官网很多东西散落在各个角落,不太好找,本文稍微归纳了一下。
技术发展日新月异,随着时间的流逝文中的一些东西可能会过时,请注意更新时间。
最后修改:2019–08–08。
目前 shadowsocks 中还在不断更新的只有 shadowsocks-libev,本文主要介绍这个。
首先你要有台用于搭建 ss 的服务器。另外本教程适合用户个人使用,如果想建站,请自行查阅其他资料。
ubuntu 的安装很简单,一条命令即可,不过貌似对 Ubuntu 版本有要求
sudo apt install shadowsocks-libev
安装的可能不是最新版,最新版请手动编译
按官网说明安装软件,建议采用手动方法,原因一是能保证用的是最新版,二是出了问题容易上网搜索解决。
Installation
不过官网上写得有些混乱,如果看不懂的话直接无脑进行如下操作即可:
yum install epel-release -y
yum install gcc gettext autoconf libtool automake make pcre-devel asciidoc xmlto c-ares-devel libev-devel libsodium-devel mbedtls-devel -y
git clone https://github.com/shadowsocks/shadowsocks-libev.git
cd shadowsocks-libev
git submodule update --init --recursive
./autogen.sh && ./configure && make
sudo make install
接下来需要将配置文件拷贝到常用路径
添加配置文件:
cp ./rpm/SOURCES/etc/init.d/shadowsocks-libev /etc/init.d/shadowsocks-libev
cp ./debian/config.json /etc/shadowsocks-libev/config.json
chmod +x /etc/init.d/shadowsocks-libev
编辑配置文件
vim /etc/shadowsocks-libev/config.json
修改里面的配置,这里给个 demo,具体每个参数什么意思在官网了解吧:
{
"server":["[::0]","0.0.0.0"],
"server_port":8388,
"local_port":1080,
"password":"barfoo!",
"timeout":60,
"method":"chacha20-ietf-poly1305"
}该配置同时支持 Ipv6 和 Ipv4,并采用 ss3.0 支持的 AEAD 加密方式。
接下来我们要修改 /etc/init.d/shadowsocks-libev,由于历史原因这里面有点问题。
把文件中的DAEMON=/usr/bin/ss-server改成DAEMON=/usr/local/bin/ss-server
修改完成后修改文件权限
chmod 755 /etc/init.d/shadowsocks-libev
启动 shadowsocks-libev
/etc/init.d/shadowsocks-libev start
多用户配置有多种方法,官方推荐通过给每个用户一个配置文件,启动多个ss-server实现。
还有种方法如下,通过启动ss-manager实现
多用户配置文件与单用户不同,我们配置文件目录创建一个ss_manager.json
{
"server": ["[::0]","0.0.0.0"],
"local_port": 1080, # 本地端口,自行设定
"timeout": 600, # 超时毫秒数
"method": "chacha20-ietf-poly1305",
"port_password": {
"8388": "barfoo1", # 端口号与密码
"8389": "barfoo2"
}
}单用户很简单
chkconfig --add shadowsocks
service shadowsocks start
若是针对多用户情况,需要手写开机启动脚本,方法如下:
应在/usr/lib/systemd/system下新建一个.service文件,例如ssmanager.service
[Unit]
Description=shadowsocks manager # 服务的描述
After=network.target # 该服务跟在哪个服务后启动
[Service]
Type=forking # 启动时的进程行为,forking是以fork形式从父进程创建子进程,子进程创建后父进程退出
ExecStart=/usr/local/bin/ss-manager --manager-address /var/run/shadowsocks-manager.sock -c /etc/shadowsocks/ss_manager.json # 启动服务时执行的命令
PrivateTmp=true # 使用私有临时文件目录
[Install]
WantedBy=multi-user.target # 附挂在multi-user.target下
所有配置文件与脚本都设置完毕,使用systemctl开启服务。
# 更改.service文件后,都要重载守护进程更新systemctl
systemctl daemon-reload
# 启动服务
systemctl start ssmanager.service
# 查看服务状态,若为绿色active(running)则说明服务成功启动
systemctl status ssmanager.service
# 设置服务开机自启动
systemctl enable ssmanager.service
# 还可使用systemctl restart ssmanager.service重启服务,使用systemctl stop ssmanager.service停止服务
很多人按照教程的配置完后,发现并不能使用,原因是端口被防火墙关闭了。
输入如下代码开启防火墙端口白名单:
vim /etc/firewalld/zones/public.xml
在文件中适当位置添加下面代码:
<port protocol="tcp" port="[server port]"/>
<port protocol="udp" port="[server port]"/>
[server port] 填你的端口号。
重启防火墙
firewall-cmd --complete-reload
在这里面找适合自己版本的吧
GitHub
shadowsocks-libev 一个进程只能开启一个端口,因此我们要开启多个进程,对应每个进程使用一份相应的配置文件,从而达到多用户使用的目的
配置完多份配置文件后w在 /etc/init.d/shadowsocks 相应位置添加如下代码,一下代码仅供参考,读者可根据实际需求修改,这些代码的意思都很简单。
# 配置文件位置
CONF1=/etc/shadowsocks-libev/config1.json
# 检测配置文件是否存在
if [ ! -f $CONF1 ] ; then
echo "The configuration file1 cannot be found!"
exit 0
fi
# 定位到 pid 文件
PID1=/var/run/$NAME/pid1
# 开启进程
daemon $DAEMON -c $CONF1 -f $PID1
# 杀死进程
killproc -p ${PID1}
# 移除 pid 文件
rm -f ${PID1}
在原来的脚本里有跟上面代码极其相似的地方(数字1没有),把上面的6段代码插入到原来脚本中对应相似的代码后面即可。