Apple has released its regular weekly update to XProtect for all versions of macOS, bringing it to version 5346. As usual it doesn’t release information about what security issues this update might address.
This version removes 11 Yara rules for MACOS.f3edc61, MACOS.d1e06b8, OSX.Bundlore.D, OSX.OpinionSpy, OSX.DevilRobber.A, OSX.DevilRobber.B, OSX.Mdropper.i, OSX.FkCodec.i, MACOS.d4735e3, MACOS.HONKBOX.B, and MACOS.FLUFFYFERRET.CT, and many of the component rules for MACOS.ADLOAD. There are no changes in the Osascript rules in XPScripts.yr.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5346
Sequoia and Tahoe systems only
This update has already been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5346 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
Apple has released its regular weekly update to XProtect for all versions of macOS, bringing it to version 5345. As usual it doesn’t release information about what security issues this update might address.
This version adds one new Yara rule for MACOS.SILLYSTRAW.IMA, which appears to be a new genus, and in the Osascript rules in XPScripts.yr it adds a new rule for MACOS.OSASCRIPT.TADE and amends the existing rule for MACOS.OSASCRIPT.SYPR.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5345
Sequoia and Tahoe systems only
This update has already been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5345 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
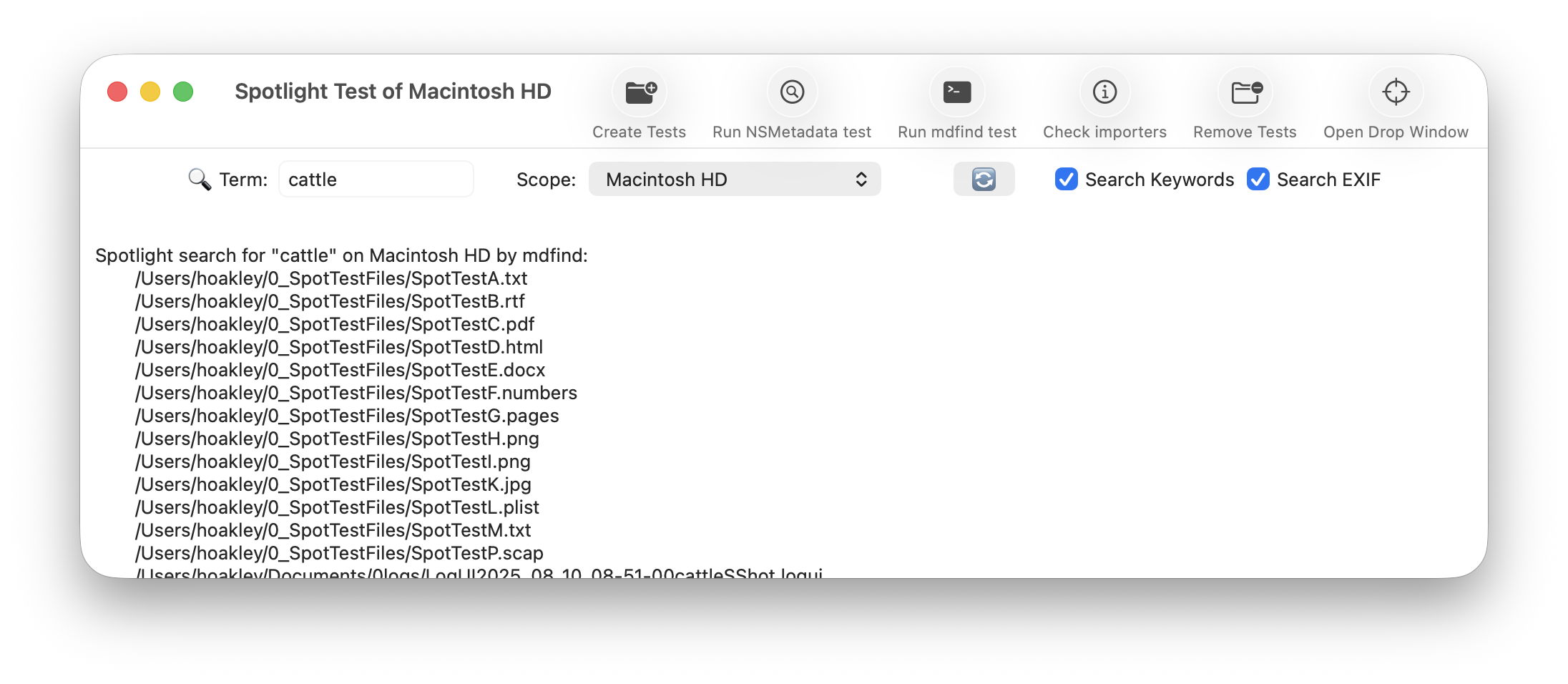
As promised, here is a new version of my free Spotlight test utility SpotTest, which will now display full information from two Spotlight command tools listing metadata for files.
To open its new Drop Window, either click on the new tool at the right end of the toolbar in its main window, or use the command in its Window menu. Then drag and drop files you want to inspect onto that window.
The app then runs two command tools on those files: mdimport -t -d2 filename
to list all known metadata recognised by the mdimporter used, and mdls filename
to list all indexed metadata.
That mdimport command currently crashes on most images, so won’t return any information about their metadata until Apple fixes the bug.
If you want to save the output in this Drop Window, select the file(s) output in its display, copy and paste it into a text editor or similar. You don’t have to keep the app main window open, and could use the Drop Window alone as a convenient way to inspect metadata.
As you’ll see, the length of mdimport output is significantly greater than that from mdls. Although there are matching entries, there’s no simple way to align those matches. Of all the possible layouts, I found this linked arrangement, where both outputs scroll alongside one another, the most effective for comparing their contents. It also allows you to view output for several files in the single window.
SpotTest version 1.2 is now available from here: spottest12
from Downloads above, and from its Product Page.
Tomorrow I’ll be using it to trace the paths of metadata from a source file to their display in the Finder.
Apple has released an update to XProtect for all versions of macOS, bringing it to version 5344. Version 5343 doesn’t appear to have been released. As usual it doesn’t release information about what security issues this update might address.
This version makes minor amendments to the Yara rules for MACOS.SHEEPSWAP.OBF.C, MACOS.SHEEPSWAP.OBFE.COMMON and MACOS.ADLOAD. There has been no change in the Osascript rules in XPScripts.yr.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5344
Sequoia and Tahoe systems only
This update has already been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5344 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
The update bringing macOS Tahoe to version 26.5 is modest in size and, apart from its security fixes, seems largely routine maintenance.
The only release notes worth reading are those listing vulnerabilities fixed, available here. Among the 69 listed there are 9 in the kernel, which must be the highest number in any recent macOS update. I wonder whether those have been swelled by AI, and one of the kernel bugs is credited to a researcher “with Claude and Anthropic Research”. There could of course be fixes resulting from early use of Mythos, but they’re unlikely to appear in a public list. None of the fixes listed are reported as being known to exist in the wild.
The new build number for 26.5 is 25F71. Apple silicon Macs have a firmware update bringing them to mBoot 18000.120.36, and Intel Macs with T2 chips are updated to 2103.100.6.0.0 (iBridge 23.16.15067.0.0,0).
Bundled apps have routine increments in version numbers:
Books, from version 8.4 to 8.5
Freeform, 4.4 to 4.5
Music, 1.6.4 to 1.6.5
News, 11.4 to 11.5
Passwords, 2.4 to 2.5
Safari, 26.4 (21624.1.16.11.4) to 26.5 (21624.2.5.11.4)
Stocks, 8.4 to 8.5
TV, 1.6.4 to 1.6.5.
Although there are abundant increments in build numbers reflecting routine maintenance, there are few substantial changes apparent in /System/Library, including:
In kernel extensions, the whole AGX series has a substantial change in version, as does AppleUSBAudio, and smbfs is updated to version 6.0.1
APFS is incremented to version 2811.120.14
There’s a new AppleAccountTransparency in private frameworks.
Apple has released the update to bring macOS Tahoe to version 26.5, and security updates for Sequoia and Sonoma to bring them to 15.7.7 and 14.8.7.
If you were expecting 15.7.6 or 14.8.6, then you’ll be as surprised as I was that Apple appears to have skipped those and gone straight on to x.x.7. I haven’t seen any explanation for this curious change in version numbering.
Download size for the 26.5 update on an Apple silicon Mac is around 3.8 GB, and the last 5 minutes of preparation takes maybe a tad longer than that. Intel Macs should download around 2.9 GB instead.
In Apple silicon Macs, firmware is updated to mBoot 18000.120.36, while Intel firmware is updated to 2103.100.6.0.0 (iBridge 23.16.15067.0.0,0).
Release notes are the bland and unhelpful statement that “This update includes enhancements, bug fixes, and security updates for your Mac.”
Security release notes are here for Tahoe with around 69 vulnerabilities fixed including more kernel bugs than I’ve ever seen in a single update, here for Sequoia with around 45, and here for Sonoma with a mere 43 or so.
Apple still hasn’t posted any enterprise release notes here but might think of something to report later.
Apple has released an update to XProtect for all versions of macOS, bringing it to version 5342. As usual it doesn’t release information about what security issues this update might address.
This version doesn’t appear to bring any additions or amendments to either the main Yara rules, or for Osascript rules in XPScripts.yr, but there has been extensive reformatting, tidying, and relabeling of lists.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5342
Sequoia and Tahoe systems only
This update has now been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5342 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
Apple has released an update to XProtect for all versions of macOS, bringing it to version 5341; the previous public release was 5338. As usual it doesn’t release information about what security issues this update might address.
This version amends the Yara rule for MACOS.PIRRIT.TWEN, and adds new rules for MACOS.AIRPIPE.IM, MACOS.EIGER.SUNOTO, MACOS.EIGER.BA and MACOS.MONCH.BA. Osascript rules in XPScripts.yr have amendments to those for MACOS.OSASCRIPT.BOZO, MACOS.OSASCRIPT.BOWISP and MACOS.OSASCRIPT.GEPEPA, and new rules added for MACOS.OSASCRIPT.DUCACI, MACOS.OSASCRIPT.DUCOOB and MACOS.OSASCRIPT.AMSCLUCL.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5341
Sequoia and Tahoe systems only
This update has now been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5341 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
Overnight, Apple has released its regular weekly update to XProtect, bringing it to version 5338. As usual it doesn’t release information about what security issues this update might address.
This version adds four new Yara rules for MACOS.BONZAIBREEZE, MACOS.BONZAIBUFFOON, MACOS.BONZAIBOOMER and BONZAIBUNNY, additions to the Bonzai family of what appear to be clickfix stealers. To accompany those are four new entries in the Osascript rules in XPScripts.yr, for MACOS.OSASCRIPT.BOPADO, MACOS.OSASCRIPT.BOSTA, MACOS.OSASCRIPT.BOMSPAA and MACOS.OSASCRIPT.BOMSPAB.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5338
Sequoia and Tahoe systems only
This update has now (as of 1700 GMT 10 April) been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5338 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
Apple has just released an update to macOS Tahoe, bringing it to version 26.4.1.
Apple’s Enterprise release notes reveal that this resolves “an issue where MacBook Air with M5 and MacBook Pro with M5 Pro or M5 Max failed to join 802.1X Wi-Fi networks while using content filter extensions.” Otherwise, this update has no published CVE entries, and no general user release notes.
The download is about 2.13 GB for Apple silicon Macs.
The build number is 25E253, just 7 builds since 26.4, and there don’t appear to be any firmware updates.
There are no changes in bundled app version or build numbers, even in Safari, and the only change in /System/Library is in the Private Framework for Icon Services in SwiftUI. I suspect that the bug fixed is in one or more binaries elsewhere in the SSV. However, this may fix more than that single bug, as iOS and iPadOS 26 also had a patch update yesterday for unidentified “bug fixes”.
Apple has overnight released its out-of-cycle update to XProtect for macOS prior to Sequoia, bringing it to version 5337. This update has already been released for macOS Sequoia and Tahoe, and this update provides the same version for those Macs still using on the older bundle location.
This version removes the Yara rule for MACOS.SOMA.MAENB, and makes no changes to the Osascript rules in XPScripts.yr.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5337
Sequoia and Tahoe systems only
This update has already been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5337 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
Apple has just released an out-of-cycle update to XProtect for macOS Sequoia and Tahoe only, bringing it to version 5337. As usual it doesn’t release information about what security issues this update might address.
This version removes the Yara rule for MACOS.SOMA.MAENB, and makes no changes to the Osascript rules in XPScripts.yr.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page.
Currently this update is only available for Macs running Sequoia or Tahoe. Those running earlier versions of macOS can only update to XProtect version 5336 via softwareupdate.
This update has only been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5337 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
With macOS Tahoe already more than half way through its cycle, and Apple’s WWDC announced, now is a good time to plan your Mac’s calendar. This article peeks at what lies ahead for macOS over the next six months.
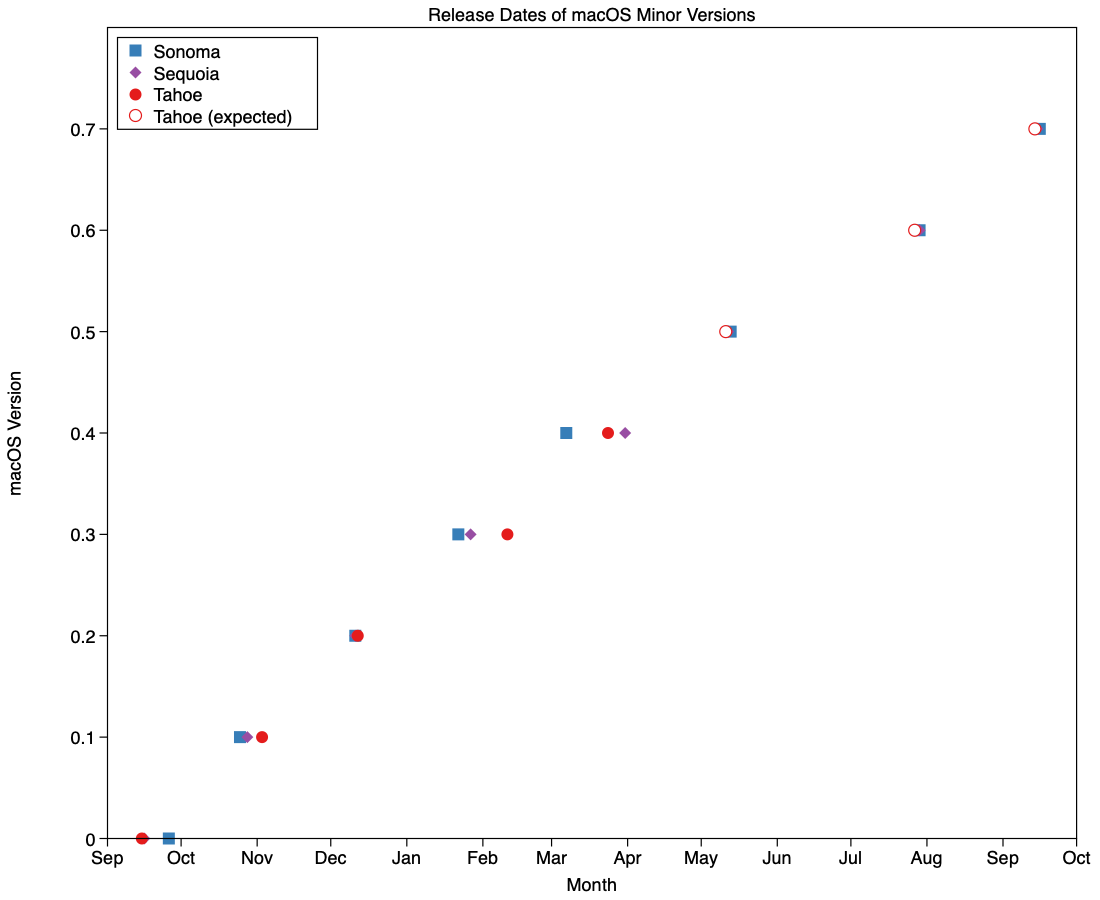
Since the pandemic disruption settled, minor version updates to macOS have become more regular. Looking across Sonoma, Sequoia and Tahoe, greatest variation in their timing has been in their x.3 and x.4 releases, that have varied between 22 Jan – 11 Feb, and 7 – 31 March, respectively. x.5 to x.7 have been more consistent, as they’re more tightly constrained by events including WWDC, the subsequent new beta season, and for some maybe even a vacation.
Those are summarised in the chart above, together with my predictions for the dates we should expect the remaining minor versions of Tahoe. Those should bring its cycle to look like:
26.0 – 15 September 2025
26.1 – 3 November 2025
26.2 – 12 December 2025
26.3 – 11 February 2026
26.4 – 24 March 2026
26.5 – 11 May 2026
26.6 – 27 July 2026
26.7 – 14 September 2026.
Where my forecasts are given in italics. Patch releases, such as 26.3.1, and BSIs occur outside that schedule. While we’re on the topic of BSIs, all indications are that Apple only intends to provide them for the current release of macOS, as it did with RSRs, which means that those Macs staying with Tahoe from 26.7 will no longer get them. It’s unclear how significant a loss that might prove.
WWDC this year is being held between 8-12 June, and will almost certainly bring the first developer beta release of macOS 27.0 (and all Apple’s other OSes). That’s likely to be made available to public beta-testers in early July. This is particularly significant this year, as it will be the first version of macOS to run exclusively on Apple silicon Macs.
For those with Intel Macs, or intending to remain with older versions of macOS, likely dates of release for scheduled security updates to Sonoma and Sequoia are:
15.7.6, 14.8.6 – 11 May 2026
15.7.7, 14.8.7 – 27 July 2026
15.7.8, 14.8.8 – 25 August 2026
15.8 – 14 September 2026.
The date at the end of August is possible, but less likely than the previous two. So far this year, security updates for Sonoma and Sequoia have been keeping reasonably close to those for Tahoe, in terms of vulnerabilities addressed, so the security gap between them has been rather less than in previous cycles.
However, the important message here is that it’s unlikely that Sonoma will receive any further security updates after the end of August this year. If your Mac is capable of being upgraded to Sequoia, now is the time to plan that, or it’ll all too quickly be September and your macOS will have lost its last support.
Similarly, if you’ve been holding back from upgrading to Tahoe in the hope that it will undergo interface improvements, I’m afraid that’s now looking increasingly unlikely. If it’s an Intel Mac capable of running Tahoe, there’s little point in avoiding making that decision any longer. There’s only limited time and scope left for improvement in macOS 26, with most engineers now more focussed on getting macOS 27 ready for WWDC.
Apple has just released its regular weekly update to XProtect, bringing it to version 5336. As usual it doesn’t release information about what security issues this update might address.
This version adds two new rules for MACOS.WANNABEWALLABY.IMA and MACOS.WANNABEWALLABY.STA, amends rules for MACOS.TIMELYTURTLE.DYHEOC, MACOS.SOMA.MAENA, and MACOS.SOMA.MAENB, and changes some rule UUIDs. In the Osascript rules in XPScripts.yr, it amends the rule for MACOS.OSASCRIPT.SYPR.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5336
Sequoia and Tahoe systems only
This update hasn’t yet been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5336 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
For those working with Rich Text without embedded images, my free editor DelightEd offers a suite of unique features. I wrote it when macOS Mojave introduced Dark appearance mode, with the primary purpose of composing Rich Text documents that work independent of appearance. For that it can set styled text on a background that ensures perfect readability in both Light and Dark modes.
Since then it has gained other unique features, including support for creating interlinear text, in which different translations or versions of the same document are interleaved line by line. It will also open PDF documents and automatically extract all their text content.
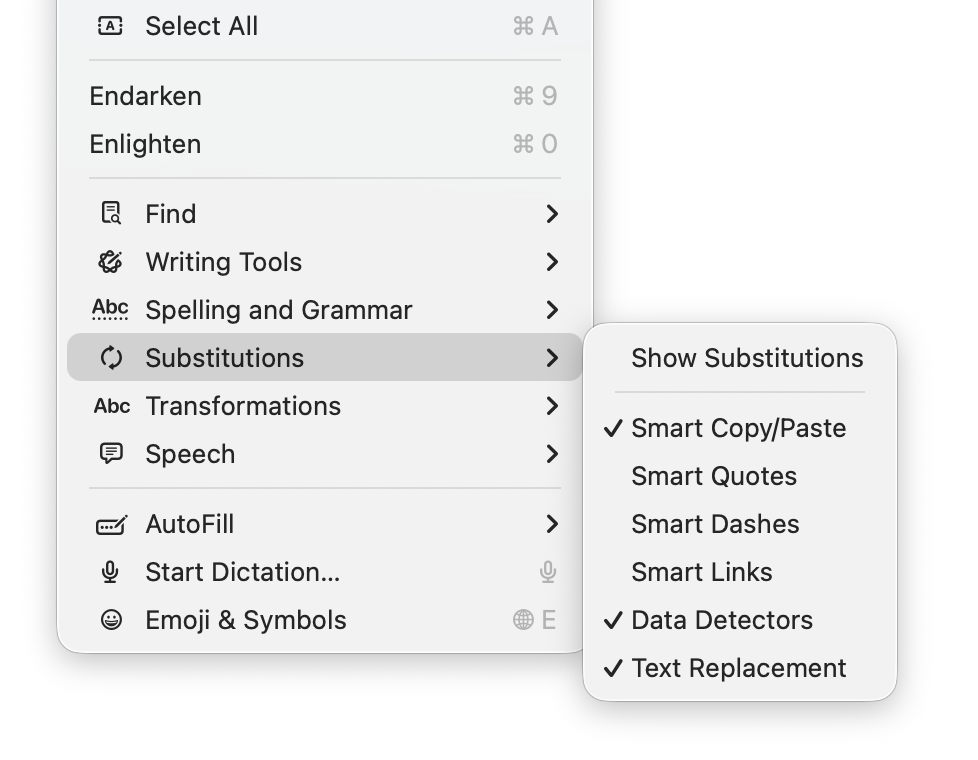
General features supported include Writing Tools (Apple silicon Macs), case transformations, and a full suite of substitutions. However, until this new version of DelightEd, substitution settings haven’t been saved in DelightEd’s app settings. Version 2.5 now puts that right: to set the app’s default substitutions, set them up using the Substitution command in its Edit menu, for instance enabling Smart Links.
Then save those to its settings using the Save Defaults command in the app’s menu. Each time you open DelightEd after that, its substitutions will start from those saved defaults.
DelightEd version 2.5 for macOS 11.5 Big Sur and later, including Tahoe, is now available from here: delighted25
from Downloads above, from its Product Page, and through its auto-update mechanism.
I’m very grateful to Manuel for asking for this to be fixed.
Many discovered how long 5 minutes could last when they updated from macOS 26.3.1 to 26.4. Right at the end of its Preparation phase, Software Update showed there were only 5 minutes remaining for far longer. This article reveals what went wrong with that update.
My observations come from a Mac mini M4 Pro running a vanilla installation of macOS Tahoe, being updated from 26.3.1 (a) with the BSI installed, to 26.4. Times and details are taken from log extracts covering the final 14 minutes of the update, immediately prior to the reboot for its installation.
Preparation
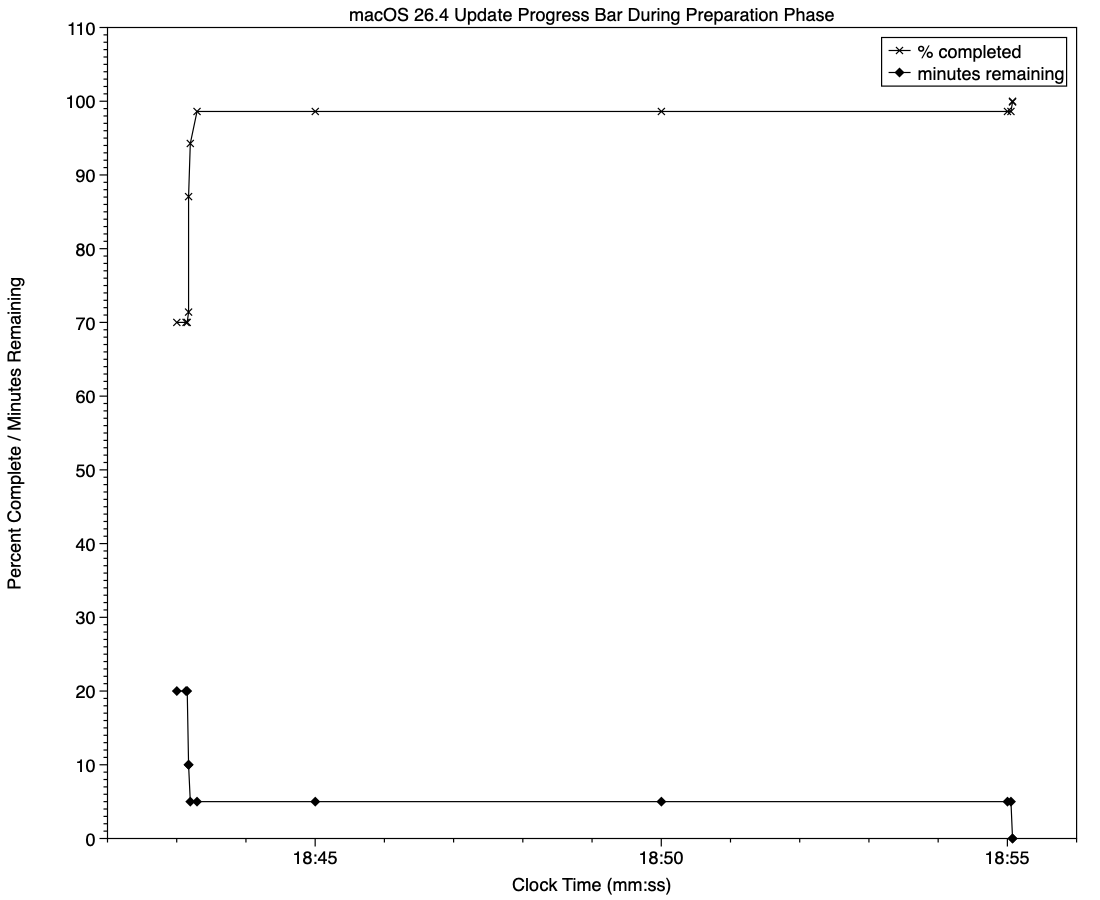
At almost exactly 18:43:00, softwareupdated reported that the PREPARING_UPDATE phase was in progress, with 70% complete on the progress bar, and 20 minutes remaining. Periodic preparation activities were then reported in the log, mainly verifying components to be installed as part of the update. One of the longest of those, /usr/standalone/i386/Firmware.scap, took nearly 6.5 minutes alone, although you might wonder why that’s required on an Apple silicon Mac!
Eleven seconds later, softwareupdated changed the progress bar to display 10 minutes remaining, with 71% completed. Just 1.5 seconds later that changed again to display 5 minutes remaining with 94% complete. Six seconds after that, with 5 minutes still displayed, the log records 98.6% was complete.
The log and progress bar then remained stuck at 5 minutes remaining and 98.6% complete for the next 11 minutes and 47 seconds, before changing to 99.9% complete and no time remaining.
These are plotted in the chart below.
The final 5 minute period started at 18:43:12, and lasted until 18:55:04, as reflected in the long period of 98.6% completion (upper line) and 5 minutes remaining (lower line).
The “5 minutes” remaining actually took 12 minutes and 7 seconds, although log entries make it clear that preparation continued throughout that time, with further verifications and “Preparing system volume…”. Those details were reported as ActionText for progress monitoring, but curiously aren’t accessible to the user at the time.
Log entries record softwareupdated keeping detailed records of progress over this period, though. For example: 18:51:32.924688 softwareupdated PrepareUpdate PROGRESS (Continue) | state:{
ActionText = "Preparing system volume...";
ElapsedTime = 490;
ExpectedTime = 1335505;
PercentBytesComplete = "48.05373989419242";
PercentComplete = "4.701870471432042";
}
But those aren’t reflected in the progress bar.
Once the update had completed that preparation phase, extensive checks were performed to ensure it was correctly configured, and components were moved into place in the ‘stash’ to be used during installation. One second after successful completion, softwareupdated locked the controller state and waited for the reboot to start installation. Rebooting followed less than two minutes later.
What went wrong?
The macOS 26.4 update for Apple silicon Macs was large, and the work required to verify its contents and complete its preparation was incorrectly reported in both percent completion and time remaining. Even in smaller updates, some form of progress needs to be shown in the progress bar during these later stages of preparation, or users may be mislead into thinking the update has frozen or failed, and could for example restart their Mac to try updating again.
What should the user do?
When an update claims there’s only 5 minutes left, that could readily extend to longer, possibly on slower Macs as long as 30 minutes or more. Unless there’s evidence that the update has gone wrong at this stage, you should leave your Mac to complete it, as it almost certainly will. If you’re still in doubt and want to confirm that the update hasn’t frozen, open Activity Monitor and look for around 100% CPU from softwareupdated or related processes, and disk activity.
Unfortunately, there’s nothing the user can do to accelerate macOS updates.
One of the longstanding jokes in computing is how misleading progress indicators can be, and last week most of us had a timely reminder when we updated macOS. However much we might like a perfectly accurate linear indicator for macOS updates, this is one of those situations where the best we can expect is a compromise, as I tried to explain here.
Showing progress
There are two types of progress indicator, determinate and indeterminate, depending on whether the task is quantifiable and progress is measurable. Determinate indicators are always preferred, as they inform the user whether they need only wait only a few moments, or they have time to enjoy a leisurely meal, but that requires quantifiability and measurability.
The simple example is copying a file from one disk to another: although macOS doesn’t know in advance how long that might take, it can quantify the task as the size of the file to be copied, then keep track of how much of that has already been completed. When half the size of the file has been copied, the progress bar can be set to half-way along its total length, so providing an accurate indication of progress.
However, with some copy operations that breaks down: when copying a sparse file between APFS volumes, for example, only the sparse data is copied, not the whole file size. As a result, copying sparse files often results in progress bars that jump from a low point to completion in the twinkling of an eye. This also relies on the quantities involved being linearly proportional to the time required, an assumption that often breaks down when downloading from a remote server.
macOS updates
Updating macOS consists of a series of many tasks (see references at the end), of which only one, downloading, is both quantifiable and has measurable progress, and even that may be far from linear. Apple therefore has a choice of:
Display multiple progress indicators, appropriate to each phase. While that might work well for the download phase, it can’t work for others, including preparation, which is likely to take a period of several minutes at least.
Combine those into a single progress bar, as at present.
Use an indeterminate progress indicator, such as a spinning wheel, which would be reliable but unhelpful.
As downloading is the one task that is quantifiable and its progress is measurable, I’ll start there.
For this, the progress bar starts an an arbitrary 15%, and softwareupdated assumes the total size of that download is the magnitude of that task.
When the download has been completed, the progress bar reaches an arbitrary 55%, and its caption then changes to reporting progress with preparation.
There is a weakness in the assumption that becomes obvious when downloading from a local Content Caching server, as the final 1 GB or so normally isn’t provided from the cache, but has to be freshly downloaded from Apple’s servers. However, that isn’t normally apparent when caching isn’t available and the whole of the download comes from the same remote source.
For the remainder of the progress bar, between 0%-15% and 55%-100%, the task is neither quantifiable nor measurable. Instead, softwareupdated divides it into a series of subtasks, each of which has a fixed progress level. One list of subtasks and levels obtained from the log is given in the Appendix at the end.
The disadvantage of that strategy is that time required by each subtask varies with the update and the Mac being updated. Inevitably, computationally intensive subtasks will proceed more rapidly on newer and faster Macs, while those mainly constrained by disk speed should be more uniform. Large updates should take significantly longer, and that will vary by subtask as well.
The last 5 minutes
A particular problem with some more recent macOS updates, including that from 26.3.1 to 26.4 last week, has been unmarked progress over the final “5 minutes” of preparation. While indeterminate progress indicators continue to move over that period, and reassure the user that the task hasn’t ground to a halt or frozen, the progress bar shown had no intermediate points, making it easy to misinterpret as failure to progress. If this is going to be a feature of future macOS updates, Apple needs to insert some intermediate points to let the user know that the update is still proceeding.
Conclusion
A progress bar that combines different measures of progress, such as download size and substages, can work well, but only if the user is aware of how to read it. As we only update macOS a few times each year, that isn’t sufficient exposure, and how it works needs to be made explicit.
Updating macOS is a far more complex series of processes than it used to be, and the progress bar displayed in Software Update settings is complicated as a result. To capture all the phases that precede installation of an update, the progress bar moves through a series of stages, only one of which is downloading. This article identifies and explains them.
Start
When the Software Update pane offers a macOS update, it has already done a lot of the preliminary work, in fetching the catalogue of updates, checking through them to determine which could be installed, and working out what that would require. This enables it to provide a first estimate of how much needs to be downloaded. Note this is only an estimate at this stage, and may not include additional components such as an update to Rosetta 2.
Once you’ve agreed to install the update now, the progress bar is displayed.
Progress shown here covers many different processes, of which the most substantial are the download and preparation phases. Although progress shown during the download will vary depending on the speed of your Mac’s connection with Pallas, Apple’s software update servers, other sections are determined by the completion of tasks required for the installation, and may proceed in fits and starts.
Before the download can begin, softwareupdated has initial preparations to make, including reloading and downloading the Update Brain responsible for much of the task of installation. Following that are extensive preflight checks, and together those account for the first 15% of the progress bar shown. On a fast Apple silicon Mac, the progress bar may jump straight to that 15%.
Download
This starts at that arbitrary 15%, and is completed when the bar reaches 55%. In between those it should progress according to download speed, but that can be highly non-linear.
This displays a more accurate total size for the download, and the current amount that has already been downloaded. In this case, the bulk of this update is coming over the network from my Content Caching server, so its initial estimate is for a brief period of just 2 minutes. The progress bar then moves in proportion to the amount downloaded, not the time.
Although most of the download can be cached, for Apple silicon Macs the last 1 GB or so has to be obtained for each update from Pallas. As a result, the progress bar suddenly slows as it’s approaching 55%, and the estimated time remaining increases before decreasing again.
Preparing
As soon as the download is complete, there’s another preflight phase lasting from 55%-60%, then the downloads are prepared for installation. This phase doesn’t apparently involve their decompression, which is largely performed on the download stream during the download phase.
Preparations are arbitrarily assigned a period of 30 minutes to complete, but now seldom if ever require that long. As they’re allocated to the last 40% of the progress bar, this phase usually completes much quicker than the times given.
The final 5 minutes are often the slowest, and can take a few minutes longer than that, as the files for installation are gathered into a ‘stash’ ready for the Update Brain to install. Because the progress bar tends to jump straight from 95% complete to 100% this can make it look as if the update has frozen.
Installing
As soon as preparations are complete and reach 100% on the progress bar, the Mac prepares to restart into the installation phase, for which you’re given a 1 minute countdown before the screen goes black and installation happens.
Progress bar key phases
0-15% preparation, preflight; usually brief
15-55% download; on Apple silicon Macs, last 1 GB usually can’t be cached, so slower
55-60% preflight; brief
60-100% preparing; last 5 minutes may be longest.
I hope this helps you make sense of what you see during macOS updates, at least until the screen goes black and the installation starts.
Apple has just released its regular weekly update to XProtect, bringing it to version 5335. As usual it doesn’t release information about what security issues this update might address.
This version adds two new Yara rules for MACOS.TIMELYTURTLE.OBDR and MACOS.SOMA.MAENB, and amends the existing rule for MACOS.SOMA.BYTE.SEQUENCE.B. In the Osascript rules in XPScripts.yr, it relocates those for TABUPA, REBUPA, DUVAST, DUCUHA and DUSTCO.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5335
Sequoia and Tahoe systems only
This update has already been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5335 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
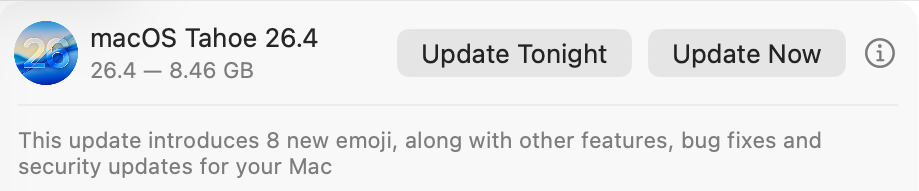
The update to bring macOS Tahoe up to version 26.4 is hefty at around 7.15 GB (more than double that if you’re unlucky), and reflects a great deal of bug fixes and improvements in almost every subsystem. Apple provides three good sets of release notes:
General release notes include the addition of an option to use compact tabs in Safari, Freeform’s new Creator Studio enhancements, and a facility for Purchase Sharing in Family Sharing. Oh, and the requisite eight new emoji.
Security release notes list over 70 fixes, many of which are significant, but none are reported as being known to be exploited in the wild at present.
The new build number of 26.4 is 25E246. The Darwin Kernel version is 25.4.0, and XNU 12377.101.15~1.
Apple silicon firmware is updated to a completely different version numbering system, and is now reported as mBoot version 18000.101.7. If you’re running SilentKnight older than version 2.14 (71), then it’s likely that it will crash as a result of this change in firmware version. Please use version 2.14 from here.
Firmware in Intel Macs with T2 chips remains with the previous system, and is updated from 2094.80.5.0.0 (iBridge 23.16.13120.0.0,0) to 2103.100.6.0.0 (iBridge 23.16.14242.0.0,0).
Looking through the bundled apps and /System/Library, there are a great many increments in build numbers reflecting the extensive changes made. Here are a few of the more substantial changes found.
In bundled apps:
Books goes from version 8.1 to 8.4
Freeform, version 4.3 to 4.4
iPhone Mirroring, version 1.5 to 1.6
Music, version 1.6.3 to 1.6.4
Safari, version 26.3.1 (21623.2.7.111.2) in BSI (a) to 26.4 (21624.1.16.11.4)
TV, version 1.6.3 to 1.6.4
Audio MIDI Setup, version 3.7 to 3.8
Digital Color Meter, version 6.10 to 6.11
Screen Sharing, version 6.2 (758.1) to 6.1 (760.4), note the reduction in version number.
In /System/Library:
AGX kernel extensions all have build increments
AppleDiskImages2 kext has a build increment
AppleEmbeddedAudio kext and its plugin kexts have build increments
AppleIntel Graphics kexts have version increments
AppleStorageDrivers kext and its plugin kexts have build increments
APFS is updated from 2632.80.1 to 2811.101.1, suggesting a substantial change has been made
new private frameworks include ASMExclaveSupport, AccelerateOpt, AlwaysOnExclavesDaemon, AnteroAgent, AppRemoteAssets, AudioPasscodeDSP, BNNSOdieDelegate, CookingData, CoreTransparency, DynamicPrefetching, InAppFeedback, NanoPassKit, PartnerVisualSearch, a whole family of Unilog frameworks, and a group of iCloudWeb frameworks
mdimporters updated include those for Application, CoreMedia, Mail, Office, iWork but not RichText.
After seeing the new CookingData private framework, I looked out for RecipeKit, but was disappointed not to see it.
This is probably going to be the last such substantial update to macOS Tahoe, as much of Apple’s engineering effort is transferring to make macOS 27 ready for release as a beta at WWDC in early June.
Freeform joins Creator Studio, with advanced tools and a premium content library
Purchase Sharing in Family Sharing
and eight new emoji.
Security release notes for 26.4 list over 70 fixes, those for Sequoia 15.7.5 list about 56, and those for Sonoma 14.8.5 list about 50. None are reported as being known to be exploited in the wild at present.
Firmware in Apple silicon Macs is updated to a new mBoot firmware version numbering system, with the current version given as 18000.101.7. The macOS build number is 25E246, and Safari is version 26.4 (21624.1.16.11.4). Firmware in Intel Macs with T2 chips is updated from 2094.80.5.0.0 (iBridge 23.16.13120.0.0,0) to 2103.100.6.0.0 (iBridge 23.16.14242.0.0,0).
If you’re running SilentKnight older than version 2.14 (71), then it’s likely that it will crash as a result of the change in firmware version. Please use version 2.14 from here.
I’ll be posting an analysis of what has changed later today.
Updated 09:15 25 March 2026 with firmware details for Intel Macs.
If there’s one thing I’ll remember macOS Tahoe for it’s brilliant engineering inside a shockingly flawed interface. Last week’s first Background Security Improvement was yet another example of that trend.
I had enthused about its predecessor the RSR three years ago, although it was sent to the naughty corner after an updated version of Safari told Facebook and other popular sites it wasn’t who they expected. After that trauma, most users shunned RSRs, and it seems engineers who dared mention them were strapped to the front of an F1 car and driven round until they recanted.
Thankfully, RSRs were only put on pause before being rebadged as Background Security Improvements or BSIs, an Orwellian turn of phrase that skilfully avoids the word update despite the fact that they’re still discovered, downloaded and installed by softwareupdated. Now I’ve had a chance to give a fair account of the first public BSI, I can consider what’s wrong with their current implementation.
Location
BSIs are controlled not in Software Update settings, but in their own section at the end of Privacy & Security. As such, they are the only macOS update there, and all others remain in Software Update where they belong. This misleads users, and Software Update reports that Your Mac is up to date when it isn’t, because there’s an outstanding BSI available.
Not only that, but users naturally assume that when Software Update settings have Install macOS updates disabled, no macOS updates will be installed automatically. Little do they realise they can still get a BSI without being asked.
BSIs are currently misplaced in System Settings, and their controls should be moved back to Software Update where RSRs were.
I fear the reasoning behind hiding BSIs among strangers in Privacy & Security was to ensure most Mac users would leave BSIs to be installed automatically. It’s no coincidence that, in addition to this hiding, the automatic installation of BSIs was enabled by default when upgrading to macOS Tahoe. This reeks of deliberate deception.
Control
There is a single on-off toggle provided, to Automatically Install BSIs. Apple explains that “if you choose to turn off this setting, your device will not receive these improvements until they’re included in a subsequent software update.” Thus the user is given a forced choice between macOS deciding when to install an available BSI, or not being notified about that BSI at all.
As with other macOS updates, the user must be given the option to be notified when a BSI is available, and to make their own choice whether and when to install it.
The alternative for users is to disable Automatically Install, watch for news of BSI releases, and, if they wish to receive one, to enable that setting, download and install the BSI, then disable the control again. For many Mac users, that appears to be the best option in the absence of better support.
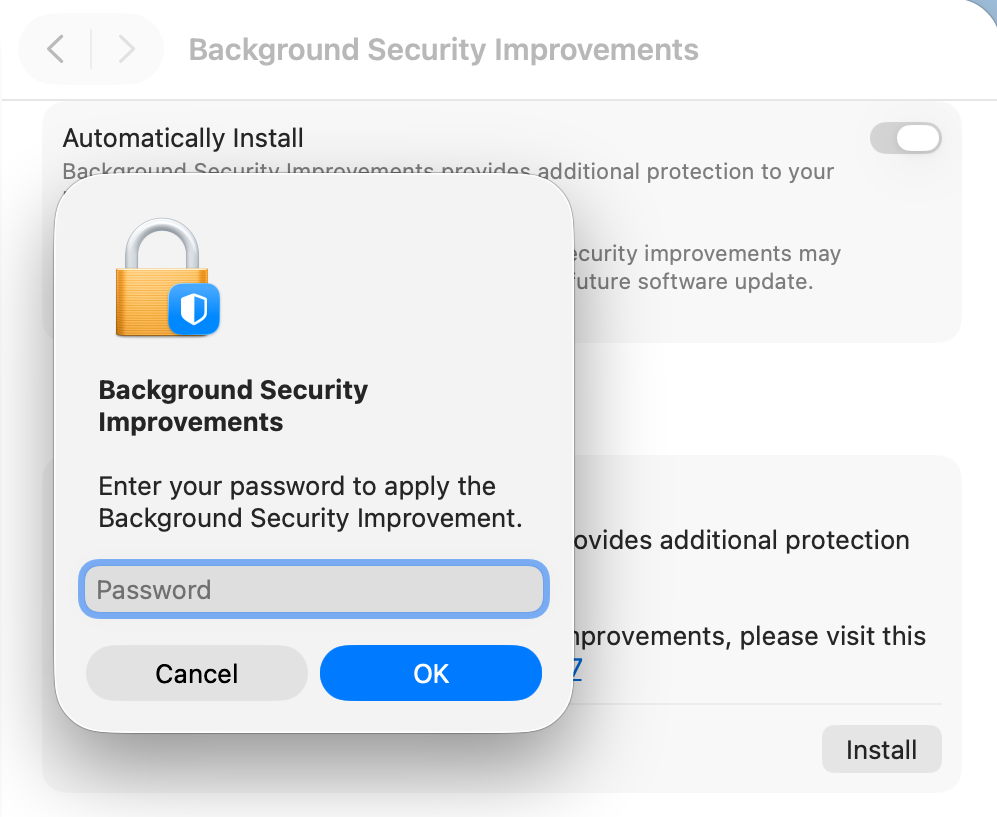
Although the control is titled Automatically Install, its behaviour is different. When a BSI is found to be available, macOS doesn’t automatically download and install it, but waits for the user to click on the Install button, then to authenticate.
However, if the user isn’t aware that BSI is available, or chooses to ignore it, automatic installation does appear to occur without the user being informed until the Mac is just about to restart, and no authentication seems necessary after all.
This behaviour is the greatest deterrent to users, as it effectively means that their Macs could restart unpredictably with almost no warning, resulting in data loss and disruption to their work. That’s completely unacceptable, and will ensure many will disable BSIs as a precaution to avoid the possibility of data loss. This aversion could be addressed simply by allowing the user full manual control over whether and when a BSI will be installed.
Progress
Despite softwareupdated monitoring progress through the download and preparation phases, the user is shown an indeterminate progress spinner, rather than a progress bar, which would at least give better warning of the restart that is coming. Although much briefer than a full macOS update, a progress bar should be displayed for the download and preparation phases of a BSI.
Restart warning
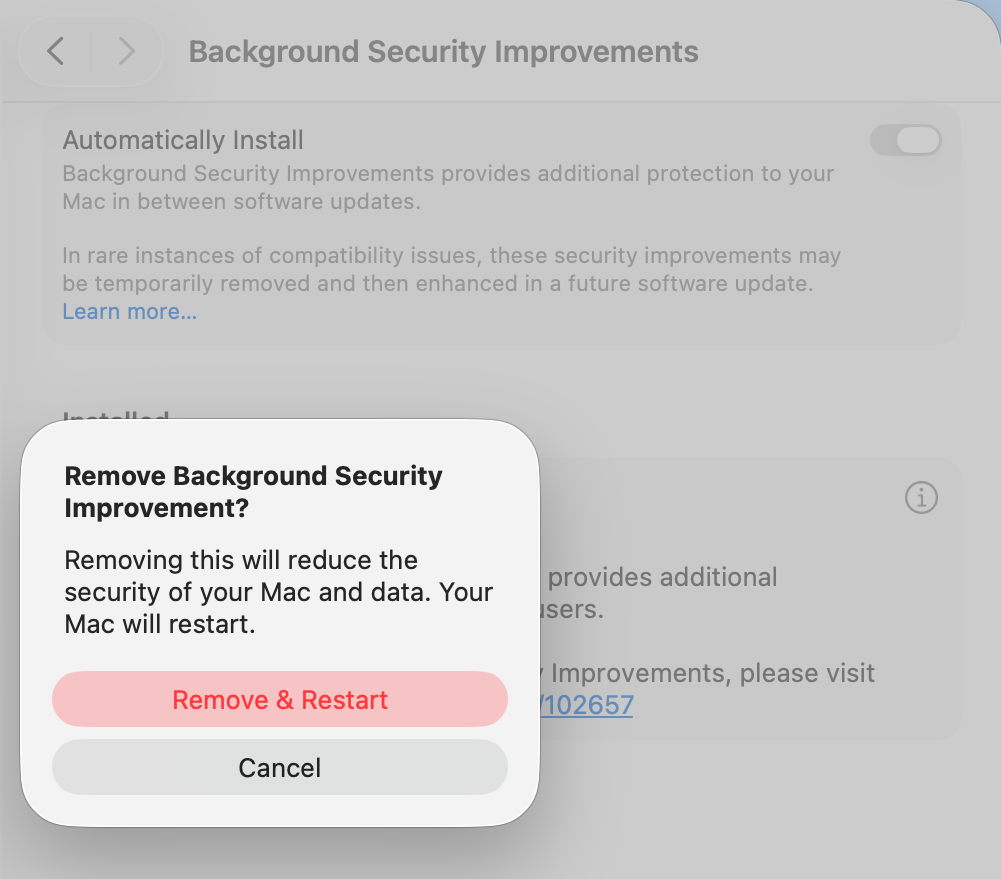
All previous RSRs, and this first BSI, have required restarts to complete the update. Yet at no time during this BSI was the user told that would be necessary. A notification was displayed a few seconds before the restart, but gave insufficient notice for the user to make any preparations.
It’s essential that information given about the BSI states clearly if a restart will be necessary, and the user is given the same one-minute countdown provided in macOS updates. Bizarrely, the one place that a restart was mentioned is in the dialog to remove a BSI.
Information
Apple’s current support note on BSIs is woefully inadequate, as is obvious by the content of this article. What would appear to be additional information in the BSI settings, marked with the ⓘ Info button, isn’t informative at all, but provides the means to remove a BSI, which is at least an improvement on RSRs, which unaccountably hid removal in the About settings. A more appropriate button should be provided.
BSIs are also only currently covered in the US English version of Apple’s Platform Security Guide. All other localised versions, including British and Canadian English, still contain the outdated section on RSRs. Fortunately, as their content is almost identical, this is revealing rather than misleading.
Version numbering
Ignoring RSR and BSI version numbering, macOS has in recent years achieved clean and systematic version (and build) numbering, without the excesses of the past. By adopting a parenthesised letter as the identifier of a BSI, comparison is clumsy and prone to error. ProcessInfo.processInfo.operatingSystemVersion doesn’t contain a field for the BSI identifier, which is only offered as part of the full string in ProcessInfo.processInfo.operatingSystemVersionString. Version numbers like 26.3.1 (a) and build numbers of 25D771280a are irregular and unnecessary.
Recommendations
BSI controls should be removed from their hiding place in Privacy & Security and put alongside all other macOS updates in Software Update settings.
An option should be provided so that users are informed of the availability of BSIs without any obligation for them to be installed automatically.
Behaviour of the Automatically Install button should be described explicitly to the user. Does it automatically install, and if so, in what circumstances will the user not be so informed?
BSI download and preparation should be accompanied by a progress bar similar to that for a macOS update.
When a BSI requires a restart to complete its installation, the user must be informed of that before they consent to the BSI being downloaded.
When a BSI install is ready to restart the Mac, one minute’s warning notification should be given, just as in macOS updates.
The BSI support note should provide full details, not a sketchy outline.
The button to remove a BSI shouldn’t use the ⓘ Info symbol, but something more appropriate to its purpose.
Apple’s Platform Security Guide should be updated in all its online versions. Is it really that hard to translate from US English to British English?
Version and build numbering should be redesigned to be more consistent and better accessible in the API.
Despite having over three years to get them right, BSIs are a worse mess than RSRs were in Ventura. This is a great shame as their technology is still brilliant, but their current interface is shockingly flawed in so many respects.
Since the introduction of the Signed System Volume in Big Sur, the great majority of macOS has been strongly protected. So strongly that applying the smallest security patch has required the full might of a macOS update. There are times when something more lightweight enables Apple to promulgate urgent patches swiftly and efficiently, and that’s what a Background Security Improvement or BSI does.
This was set up when macOS Monterey introduced cryptexes to contain Safari, its WebKit supporting library, and the large dyld caches for general support in Frameworks. Cryptexes are cryptographically sealed disk images that aren’t mounted like other volumes, but are grafted into arbitrary locations in the file system. In Ventura they were used for Rapid Security Responses (RSR), in many ways indistinguishable from BSIs.
This week’s first BSI for macOS 26.3.1 is a good example: it fixes one serious vulnerability in WebKit. Rather than building that into a full update to 26.3.2, because it only requires changes in the cryptex containing Safari and WebKit, this BSI swaps out the existing App cryptex and replaces it with a patched one. For those who don’t want to install BSIs, those same vulnerabilities should be fixed in the next set of security updates to macOS.
Controls
Look in Software Update settings, and you’ll see no mention of any BSI, and that will claim your Mac is up to date, even though it’s not.
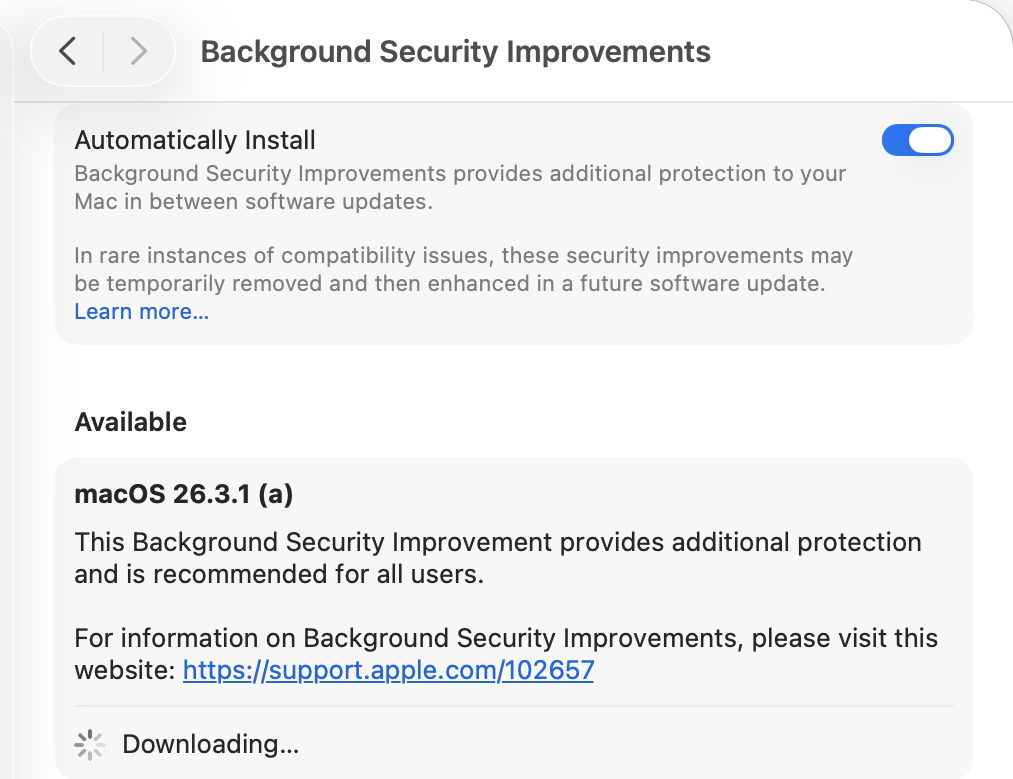
BSIs are controlled in their section listed close to the foot of Privacy & Security settings. If you want your Mac to be offered BSIs when they’re available, you must enable Automatically Install first. Despite those words, BSIs don’t appear to install in the least bit automatically, and you should be offered those available for the installed version of macOS. When you’ve chosen to download and install one and authenticated, you’ll see a progress spinner rather than a bar.
As soon as downloading and preparation are complete, you should be given a few seconds before your Mac restarts to complete the installation. This is all very brief, but once you’ve authenticated to start the process, it will run through to completion automatically.
Once your Mac has restarted, you always retain the option to remove any BSI and return to an unpatched cryptex. To see that, click on the ⓘ Info button on the right.
If you decide you want to remove the BSI, your Mac will need to be restarted.
Problems
If you know a BSI is available but Privacy & Security settings appear unable to find it, something I’ve encountered in Virtual Machines, try running SilentKnight. Although BSIs aren’t controlled in Software Update, they do still use the same softwareupdate system used by SilentKnight. Normally you shouldn’t try to install BSIs using SilentKnight, as installation will fail. However, you can turn this to your advantage when a BSI is being elusive.
Once SilentKnight has downloaded and failed to install the BSI, you should be notified of that failure. Restart your Mac, give it a couple of minutes to settle once you’ve logged back in, and open the BSI section in Privacy & Security settings again. The downloaded BSI should now be available, and shouldn’t even need to be downloaded.
If you think a BSI has caused another problem, such as instability in Safari, use the ⓘ Info button to remove that BSI.
Installing a BSI does weird things to the macOS version and build numbers, and those can break scripts and possibly some apps. While ProcessInfo.processInfo.operatingSystemVersion doesn’t contain a field for the BSI letter, ProcessInfo.processInfo.operatingSystemVersionString does return a full version description including the BSI letter and extended build number. In Terminal, sw_vers -productVersion returns the regular version number without BSI, while sw_vers -productVersionExtra returns the BSI designation alone.
Currently, SilentKnight and Skint ignore BSIs, and won’t inform you if you could have one installed except by listing it as an available installation, nor will they check whether your Mac is up to date with the latest BSI. Experience from RSRs in Ventura shows that trying to track lightweight updates like RSRs or BSIs is only going to annoy those who don’t want to install them, and as they can change in a short period, they are hard to track reliably. SilentKnight does report the full version and build number, and SystHist lists details of all BSIs that Mac has installed.
Limitations
Like the RSRs of Ventura, BSIs can only work for a limited range of patches. If a vulnerability needs a fix outside Safari, WebKit, and the dyld caches, then it will require a full macOS update to fix it. BSIs are only ever likely to be provided for the current version of the latest major version of macOS.
From its first account of RSRs, Apple has claimed that some RSRs and BSIs shouldn’t require a restart to apply their patches. However, every RSR and BSI to date has had to be completed by restarting that Mac, which is mildly disruptive and not as lightweight as we’d like.
If you disable Automatically Install in the BSI section of Privacy & Security settings, then your Mac won’t be informed about or have access to any BSIs.
Under the hood
Despite their control being part of Privacy & Security settings, BSIs are managed like all other macOS and related updates by softwareupdated. What is most remarkable about them is their speed of download, preparation and installation compared with macOS updates. From detection of a new BSI to logging back into the restarted Mac can take little more than five minutes.
Apple’s in-house term for BSIs is the same as it used for RSRs, Splat. You’ll also come across Semi-splat, which should be a transient state in which the Splat Restore Version is different from the Cryptex1 Restore Version. That’s normally rectified after the reboot.
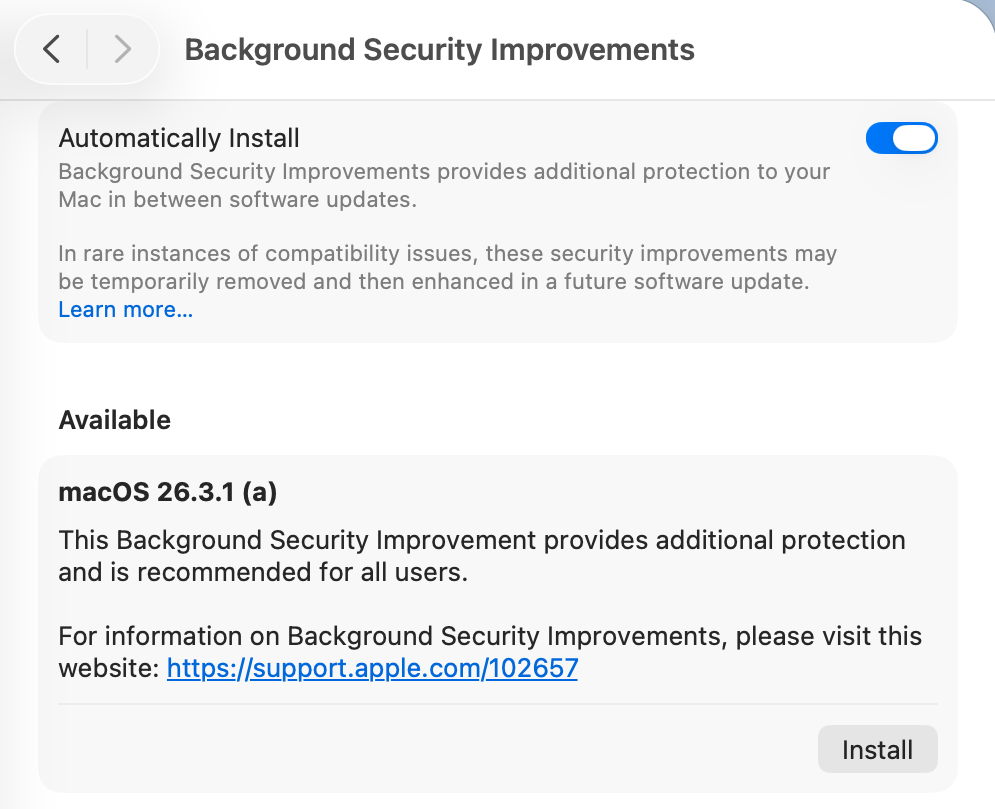
softwareupdated checks specifically for BSIs by scanning the update server catalogue for Splat updates. In this case, for an App cryptex, the download size is given as 214 MB. There’s a brief preflight phase, followed by its download. Although no progress indicator is shown in Privacy & Security settings, softwareupdated does record progress, but using similar figures for a full macOS update. Under those, preparing the update is set at 60% progress.
Applying the update takes around 2.5 seconds, at which stage softwareupdated reports that Semi-splat is active because of unequal restore versions, and rollback objects are checked.
Once the Mac has restarted, property list paths are checked for six different Splat versions, enabling the restore versions to be rectified and Semi-splat is no longer active. A brief purge of update assets is performed, and softwareupdated checks once again for any available updates.
Is a BSI just an RSR in disguise?
Apart from the move of its control from Software Update to Privacy & Security settings, there appear to be few if any differences between them. This is even reflected in version numbering. Installing the first RSR for macOS 13.3.1 brought it to version 13.3.1 (a), with a build number of 22E772610a. This first BSI for macOS 26.3.1 brings it to version 26.3.1 (a), with a build number of 25D771280a.
Most telling, though, are the accounts of RSRs and BSIs given in Apple’s Platform Security Guide, which are almost word-for-word identical apart from their names. It seems most likely that a BSI is a rebranded RSR in a bid to move on from the loss of confidence in RSRs following unfortunate errors nearly three years ago.
Key points
If you’re running the current version of the latest major version of macOS, BSIs provide lightweight fixes for some vulnerabilities, including those in Safari and WebKit.
Enable them in Privacy & Security settings, in their section at the foot. If they aren’t enabled there, you won’t be offered them at all.
Control their installation in that section. Once you’ve agreed to install one and have authenticated, your Mac is likely to restart automatically soon after the BSI has been downloaded.
Remove and revert a troublesome BSI using the ⓘ Info button there.
Although the US English version of Apple’s Platform Security Guide has replaced its section on RSRs with an almost identical account of BSIs, most other localised versions of that guide still contain the old RSR version.
In my account of how Tahoe updates macOS, I had reached the stage when Rosetta and the main update had started downloading from Pallas, Apple’s software update server (see the Appendix at the end for further explanation of terms used).
Download
Currently, the main update download (at least) is compressed using Zip, and is decompressed as a stream during download, so there’s no delay decompressing during the preparation phase later.
In this case, downloading the main update was completed within 8 minutes. The source of the Zip archive was originally given as a path on [https://]updates.cdn-apple.com/2026WinterFCS/patches, and that was written to a local path on /System/Library/AssetsV2/com_apple_MobileAsset_MacSoftwareUpdate/ In my case, though, I have a local Content Caching Server running, and immediately before the download started com.apple.AssetCacheServices substituted a download URL on that server to ensure the update was obtained through the local caching server. At the same time, an Event Report was sent back to Apple, recording the start of download.
Progress was updated every second during the download, and brought the progress bar from 16% to 53.9% over the following 8 minutes, with little other activity taking place.
Preflight
Activity then changed to what is repeatedly referred to as Preflight FDR Recovery, and is the first entry point for the UpdateBrainService, downloaded for MobileSoftwareUpdate rather than softwareupdated.
This runs an Event Recorder and begins to perform preflight checks to “recover FDR SFR”, and to perform a “firmware-only update”. To prepare for that, it retrieves various nonces and their digests for LocalPolicy, RecoveryOS boot policy, and others. Following those is the first of many attempts to determine purgeable space, in preparation for installation of the update. Those are performed by com.apple.cache_delete.
Pallas was then checked to see if there was any more recent version of RecoveryOS UpdateBrain, but there wasn’t. A further check for any newer recoveryOS was also made, before the main macOS update was prepared, at a progress level of 60% as set previously.
Preparation
The first step of the main preparation phase is to purge staged assets with com.apple.cache_delete. With that complete, UpdateBrainService recalculates cryptex size requirement for the update, and the install target prepare size:
cryptex size is 1.2 times the app cryptex size = 60 MB, plus 1.2 times the system cryptex size = 7749 MB, a total of 7809 MB, as previously calculated;
prepare size is the sum of the snapshot installation size of 3785 MB, the cryptex size of 7809 MB, three ‘slack sizes’ for VW, Recovery and Preboot of 2048 + 1024 + 1024 = 4096 MB, the new template size of 991 MB, twice the update partition size totalling 600 MB, less the old template size of 363 MB. The grand total comes to 16,918 MB.
UpdateBrainService then checks volume free sizes, and confirms that they’re sufficient to complete the update. It next creates a ‘stash’, which is protected by keys in the stash keybag, handled by the Secure Enclave Processor. There is then another round of purging with com.apple.cache_delete.
Much of the preparation phase is spent verifying the protection of installation packages, cryptexes, then the contents of /System/Applications and /System/Library. As progress is about 64% complete, System volume preparations are started, and there’s another round of purging by com.apple.cache_delete. There’s surprisingly little log activity as progress passes 70% complete.
With progress reaching 84% complete, UpdateBrainService starts unarchiving files in parallel, taking just under 5 seconds to complete those. Following that, there’s another brief period unarchiving data files in parallel, then working with the contents of /System/Volumes/Update/mnt1/private/var/MobileAsset/PreinstalledAssetsV2 as progress reaches 87% complete.
When there’s 87.5% completed, UpdateBrainService reports it’s creating hard links in parallel, then is searching for new paths and verifying files, such as those in the Ruby framework. The Recovery volume is unmounted, and there’s yet another purge with com.apple.cache_delete. After those, key volume locations are checked.
The high water mark of disk usage during update is prepared. This reveals some of the steps to be undertaken during installation, including:
prepare source package,
patch cryptexes,
patch system volume,
extract to system volume,
install personalised.
There’s a further round of purging with cache_delete before declaring PrepareUpdate as successful, then suspending the update briefly. When update resumes, the Update volume is mounted and prepared, and there’s another round of purging. The System volume is then mounted, checked, and prepared. Progress is now at 98.5% complete, and once 100% is reached, the countdown to restarting the Mac is begun.
Installation
During the download and preparation phases, apart from repeated purging, the log is generally quiet. This changes dramatically once the Mac starts preparing for shutdown and installation. WebKit is cleaned up and shut down, as are many other processes. The ‘stash’ of update components is then committed, and final scans and checks are completed.
The update is then applied, followed by Rosetta, RecoveryOS, UpdateBrain and finally minor documentation. After that period of nearly 20 seconds, this phase is declared complete, and a restart is notified before waiting for the essential reboot.
Reboot
Once rebooting by root has been initiated, the boot chime is muted to ensure the update continues in silence. The last log message is written a few seconds later, and UpdateBrain then runs the update.
Less than 3 minutes later, the system boot is recorded in the log, and kprintf is initialised 5 seconds later. About 3 minutes afterwards softwareupdated is started up, and runs various clean-up routines to complete the update sequence in conjunction with ControllerSetup and a Finite State Machine.
Key points
The main update download is decompressed while streaming, to save preparation time later.
If a local Content Caching Server is connected, AssetCacheServices will substitute its IP address for that of the Pallas server to ensure the download is obtained through the cache.
Following download, extensive preflight checks are performed.
During preparation components are verified, paths checked, and some unarchiving is performed.
Prior to reboot and installation, processes including WebKit are shut down in readiness for reboot and install.
FDR is unknown, but appears associated almost exclusively with a preflight phase.
Pallas is the internal name for Apple’s software update server. This appears throughout log entries, where for example Pallas audience is jargon for the type of user, normally macOS Customer.
RecoveryOS appears to refer to the version of Recovery in the hidden container of the internal SSD, more widely known as Fallback Recovery.
SFR appears to refer to the version of Recovery in the Recovery volume of the active boot volume group, also known as Paired Recovery.
Splat, semi-splat and rollback objects all refer to cryptexes. Splat is the general term, while semi-splat refers to a cryptex-based update that might include rapid security responses (RSR) and background security improvements (BSI) implemented by replacing one or both cryptexes. Rollback objects are older versions of a cryptex that have been saved to allow a newer cryptex to be reverted to that older one, in the event that the newer cryptex causes problems.
UpdateBrain is the executable code supplied as part of an update that prepares and installs that specific update. There’s a separate UpdateBrainService for RecoveryOS.
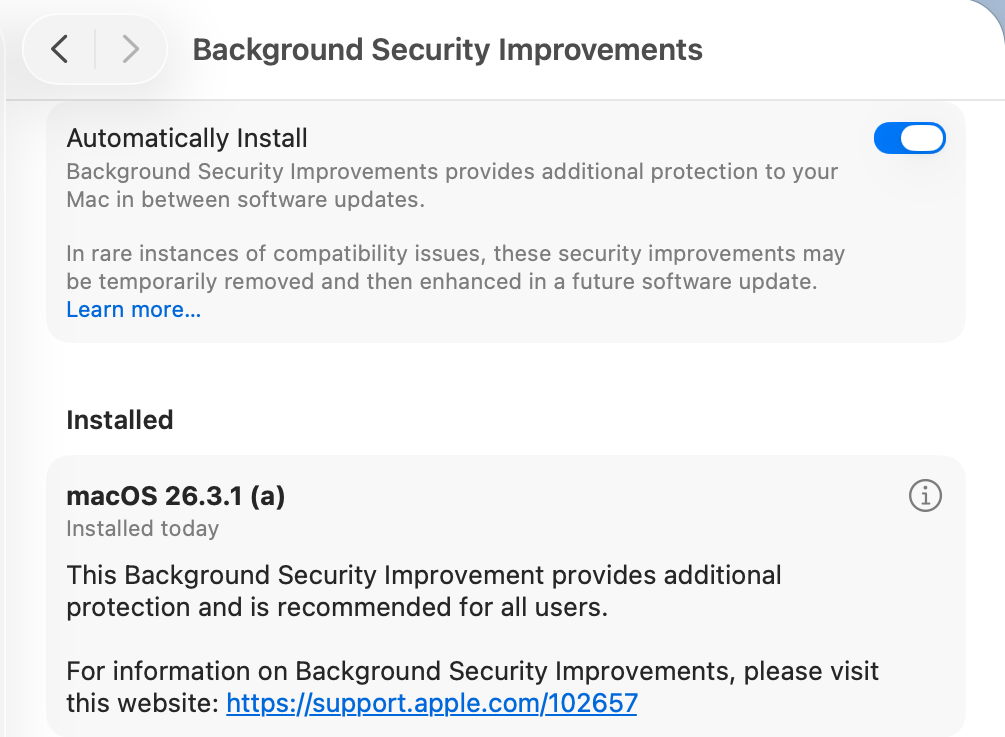
Apple has just released its first public Background Security Improvement (BSI) for macOS 26.3.1 Tahoe, labelled as BSI (a)-25D771280a. Once installed, macOS will identify itself as version 26.3.1 (a), with a build number of 25D771280a.
You can install this through Privacy & Security Settings, in the Background Security Improvements section. It doesn’t appear listed in Software Update, although SilentKnight will offer it. Please don’t try to use SilentKnight to install this, though, as it will download successfully but fail to install unless you then use the BSI section in Privacy & Security settings, which will finish the job off.
Apple has now released details of the single vulnerability that this fixes, in WebKit. As a result it updates Safari from 26.3.1 (21623.2.7.11.7) to 26.3.1 (21623.2.7.111.2).
Following installation, your Mac will need to restart for the BSI to be applied.
Apple has just released its regular weekly update to XProtect, bringing it to version 5334. As usual it doesn’t release information about what security issues this update might address.
This version makes no changes to its main Yara rules. Changes to the OSASCRIPT rules in XPScripts.yr include amendments to more than a dozen of them, and two new rules are added for MACOS.OSASCRIPT.GEPEPA and MACOS.OSASCRIPT.TAPEPA. Several rules that previously added the property wide to their text now have wide ascii instead.
You can check whether this update has been installed by opening System Information via About This Mac, and selecting the Installations item under Software.
A full listing of security data file versions is given by SilentKnight and SystHist for El Capitan to Tahoe available from their product page. If your Mac hasn’t yet installed this update, you can force it using SilentKnight or at the command line.
If you want to install this as a named update in SilentKnight, its label is XProtectPlistConfigData_10_15-5334
Sequoia and Tahoe systems only
This update has now been released for Sequoia and Tahoe via iCloud. If you want to check it manually, use the Terminal command sudo xprotect check
then enter your admin password. If that returns version 5334 but your Mac still reports an older version is installed, you should be able to force the update using sudo xprotect update
I’d like to apologise to those of you who ended last week downloading two new versions of SilentKnight, instead of the one that I had intended. This article explains how the second came about.
SilentKnight is heavily dependent on discovering key facts about the Mac that it’s running on. One of the first it needs to know is whether it’s looking at a plain Intel Mac, one with a T2 chip, or an Apple silicon Mac, as that determines how it should go about checking which version of firmware it’s running, and much else.
Over the last five years, SilentKnight has relied on the command-line equivalent of the System Information app, system_profiler. Surprisingly that doesn’t have a single field that draws a clear distinction between those types of Mac. The closest it comes to doing that is the information shown for the Controller item, or system_profiler SPiBridgeDataType
in Terminal:
Intel Macs without a T2 chip return no information, as they’re not considered to have a controller in this sense.
Those with T2 chips return a Model Name of Apple T2 Security Chip.
Apple silicon Macs give the iBoot (or, from 26.4, mBoot) firmware version number.
While that has worked for five years, for SilentKnight version 2.13 I decided to slightly extend the text it looks for, to ” T2 ” to reduce the chance of false positives now that Apple silicon results are becoming more diverse. That worked fine on my two Intel Macs with T2 chips, but broke weirdly in a MacBook Pro tested by Jan, to whom I’m deeply grateful for the early report of this problem. Jan’s MacBook Pro was thoroughly confused, found and reported the correct T2 firmware but told them it should be running a more recent version of iBoot, for Apple silicon Macs.
It turned out that Jan’s MacBook Pro is running German as its primary language, so instead of reporting Apple T2 Security Chip in system_profiler it returned Apple T2-Sicherheits-Chip, and ” T2 ” couldn’t be found to confirm it wasn’t an Apple silicon Mac. The simple fix was to remove the trailing blank from the search term, which becomes ” T2″.
Although system_profiler can return its information in plain text, JSON or XML formats, its content is the same in all three, with localised text that’s dependent on that Mac’s primary language setting. Besides, its XML is exceptionally verbose, squeezing a few lines of information into 262. I was surprised by this five years ago, when I first came across it when trying to parse the list of Apple silicon security settings.
Here you can see those for a Mac using Dutch localisation. Instead of responses like Secure Boot: Full Security
using Dutch for your Mac’s primary language turns that into Secure Boot: Volledige beveiliging
When SilentKnight tries to work out whether your Mac is set to Full Security, that means it would have to look up the response in a dictionary containing every possible language.
Not only that, but these localised responses vary between different sections and data types.
The above responses to system_profiler with French set as the primary language demonstrate that has no effect on Hardware data, where core types are given in English, but changes those in Controller’s Boot Policy. To discover which change, you have to test with many different language settings, as none of this is documented, of course.
At that time I spent several days trying to get an unlocalised response by running system_profiler in an English environment, but that had no effect, and there was no way to bypass this localisation. As this language dependency limits the usefulness of the command tool, I argued that its output shouldn’t be localised at all.
Now, five years later, I have been bitten again, and apologise for putting you through two updates to SilentKnight when there should only have been one.
Apple silicon Macs are about to undergo change to the numbering of their firmware versions. Accounts from beta-testing of the next minor update to macOS 26 Tahoe, version 26.4, indicate that future firmware will no longer be numbered as iBoot 13822.101.6, but as mBoot 18000.101.6 instead. This has major consequences for my free utility SilentKnight, which checks and reports the version of firmware installed. Version 2.14 should address that change in readiness for the release of the 26.4 update, and is particularly recommended for use on Apple silicon Macs.
This change was first reported in macOS 26.4 beta 2, and has apparently been sustained in the two subsequent beta releases, confirming that it’s an intended change, and not a bug.
There are currently two places in System Information that report a Mac’s firmware version, either the main Hardware section (also accessible in system_profiler SPHardwareDataType), or the Controller item within that section (or system_profiler SPiBridgeDataType).
Intel Macs without a T2 chip don’t report anything for their Controller, but those with T2 or Apple silicon chips reveal that they have a T2 or give an iBoot firmware version there. All three types of Mac also give a System Firmware Version in the Hardware overview.
This can get more confusing if you update or install macOS to an external disk. That will normally update the Mac’s firmware if the version of macOS installed on the external disk comes with more recent firmware. For example, if your Apple silicon Mac is currently running macOS Tahoe 26.3.1, it should have an iBoot firmware version of 13822.81.10. If you were to install Tahoe 26.4 to an external disk, as that has a more recent version of iBoot firmware, that should update the version installed in your Mac, and that remains so even when you start it up from its internal SSD.
As far as I can tell at present, this can result in internally inconsistent reporting. When running 26.3.1 from its internal SSD, that Mac will report its old iBoot version in the Controller section, but its new mBoot version in the Hardware section. Although that could change by 26.4 release, it might remain in all older versions, so providing lasting confusion.
As Apple hasn’t documented this change, I don’t know whether this will apply to all Apple silicon Macs updated to macOS 26.4, or to those updated to the matching versions of Sequoia or Sonoma. Therefore this new version of SilentKnight doesn’t attempt to check these new mBoot versions, and merely reports those found as well as it can. Once I know more, I will endeavour to interpret the results.
SilentKnight version 2.14 for macOS 11.5 and later is now available from here: silentknight214
from Downloads above, from its Product Page, and via its auto-update mechanism.
Please let me know how you get on with these new firmware version numbers.
Note: version 2.14 now fixes a bug that failed to recognise T2 Macs correctly in certain localisations including German. Thanks to Jan for reporting this so promptly.